- The paper introduces BPPO, a novel method that adapts PPO’s clipped objective to address offline RL challenges.
- It employs clip ratio decay and off-policy advantage estimation to maintain policy performance above the behavior policy.
- BPPO demonstrates competitive, state-of-the-art results on D4RL benchmarks, particularly in environments with sparse rewards.
Behavior Proximal Policy Optimization
Introduction
The paper "Behavior Proximal Policy Optimization" introduces BPPO, a novel approach designed for offline reinforcement learning (RL). Offline RL is inherently challenging due to issues such as overestimation of out-of-distribution (OOD) state-action values. BPPO leverages the inherent conservatism of certain on-policy algorithms to address these challenges without the need for additional constraints or regularizations typically required in offline RL methods.
Motivation
Offline RL eliminates the need for online interactions by learning exclusively from pre-existing datasets. This is advantageous in domains where data collection is costly or risky. Traditional methods often struggle with the extrapolation errors introduced when evaluating OOD actions. The proposed method hypothesizes that certain online, on-policy algorithms, which naturally have conservative behavior, can be directly applied to offline RL due to their intrinsic properties.
Theoretical Foundation
The development of BPPO begins with an analysis of offline monotonic policy improvement, drawing upon the Performance Difference Theorem. This analysis suggests that the policies derived using online methods such as Proximal Policy Optimization (PPO) inherently possess properties conducive to offline learning. This foundational insight allows BPPO to maintain policy performance strictly above the behavior policy extracted from the dataset.
Methodology
BPPO adapts the PPO algorithm for offline settings by applying its optimization objective while considering offline data constraints.
- Clip Ratio and Decay: BPPO uses a clip ratio to ensure policy changes remain within bounds relative to the behavior policy. The introduction of clip ratio decay further stabilizes training by gradually tightening these bounds.
- Advantage Estimation: Instead of using online Generalized Advantage Estimation (GAE), BPPO estimates advantages off-policy by extrapolating from state-action value (Q-function) and state value estimations within the dataset. The method avoids complex off-policy corrections by ensuring the learned policy remains close to behavior policies.
- Algorithm Description: BPPO optimizes policies through iterative updates using PPO's clipped surrogate objective adapted to offline constraints. Advantage replacement serves as a primary means of stabilizing learning, offering assurance against overestimation by focusing improvements on policies that remain tethered to observed datasets.
Results and Evaluation
BPPO shows competitive performance on numerous D4RL benchmarks, often surpassing state-of-the-art results for various environments, especially when dealing with complex tasks like those involving sparse rewards.
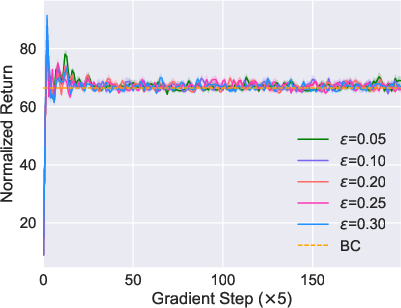
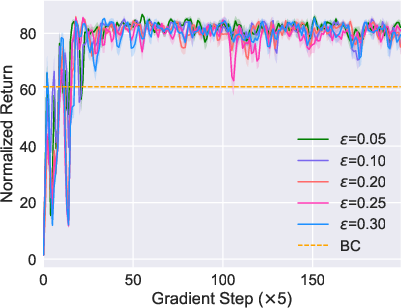

Figure 1: The comparison between BPPO and Onestep BPPO. The hyperparameters of both methods are tuned through grid search, and performance is visualized.
Implementation
Implementing BPPO requires a careful selection of hyperparameters such as clip ratio, decay rate, and learning rate. The emphasis is on ensuring that the iterative refines of policy do not drift far from the behavior observed in the offline dataset.
- Computational Considerations: BPPO inherits computational efficiency from PPO, making it amenable for deployment without excessive requirements. However, the precision in advantage estimation necessitates robust dataset preprocessing.
- Scalability: Given its reliance on datasets, BPPO scales well across various domains provided sufficient coverage of relevant state-action pairs within the offline data.
Conclusion
BPPO presents a streamlined method for addressing offline reinforcement learning challenges by focusing on monotonic improvements tied closely to dataset behavior policies. The approach circumvents traditional pitfalls of offline RL, such as overestimation, without additional constraints, showcasing robust performance across diverse domains. The utilization of BPPO could potentially extend to scenarios beyond the current scope, offering a framework adaptable for various offline learning tasks with constrained online evaluation.