A dynamical clipping approach with task feedback for Proximal Policy Optimization
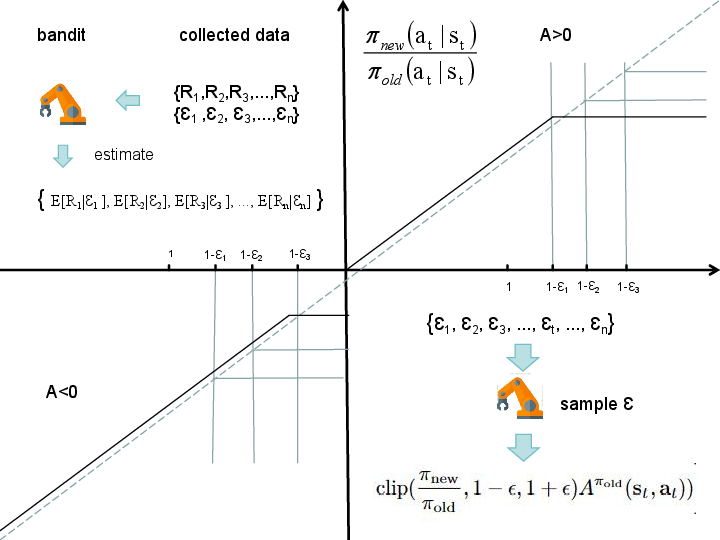
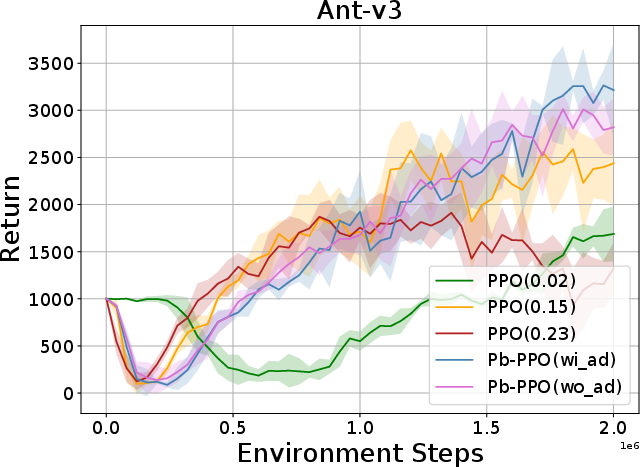
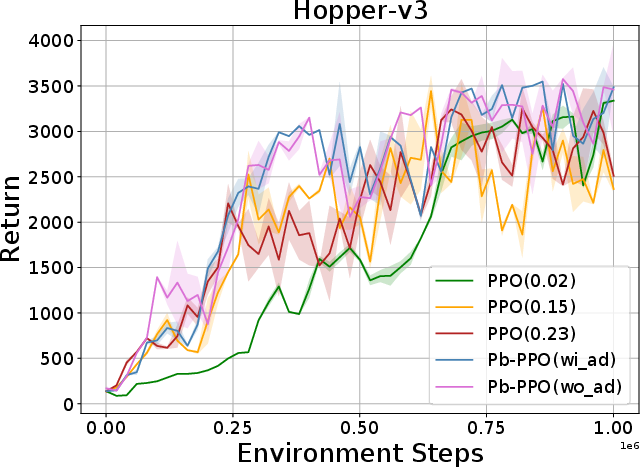
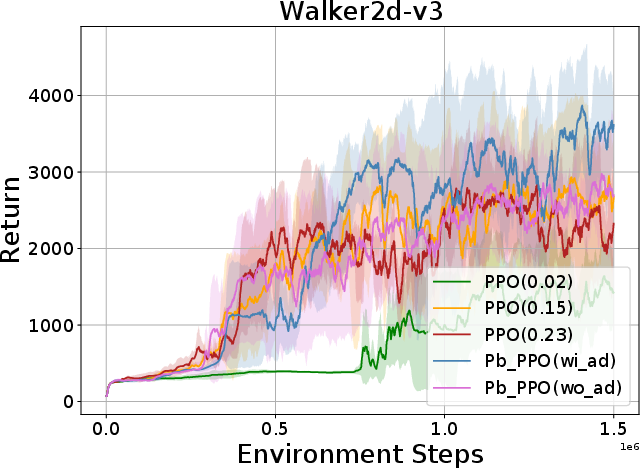
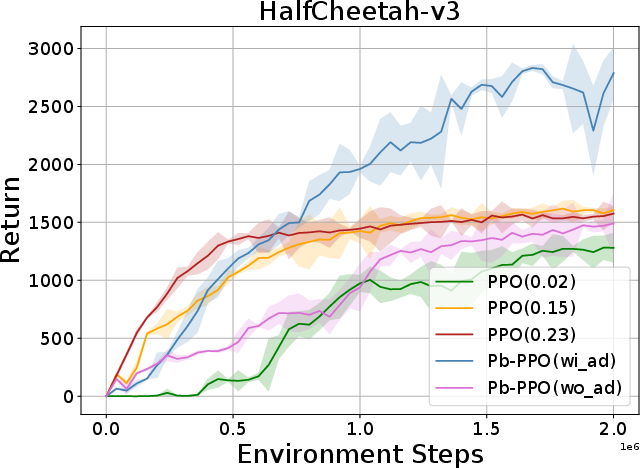
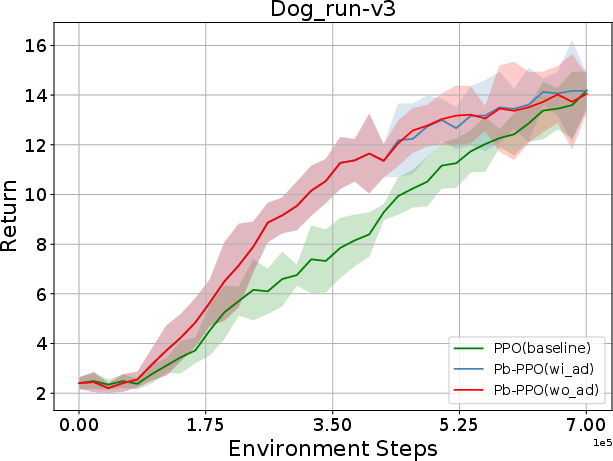
Abstract: Proximal Policy Optimization (PPO) has been broadly applied to robotics learning, showcasing stable training performance. However, the fixed clipping bound setting may limit the performance of PPO. Specifically, there is no theoretical proof that the optimal clipping bound remains consistent throughout the entire training process. Meanwhile, previous researches suggest that a fixed clipping bound restricts the policy's ability to explore. Therefore, many past studies have aimed to dynamically adjust the PPO clipping bound to enhance PPO's performance. However, the objective of these approaches are not directly aligned with the objective of reinforcement learning (RL) tasks, which is to maximize the cumulative Return. Unlike previous clipping approaches, we propose a bi-level proximal policy optimization objective that can dynamically adjust the clipping bound to better reflect the preference (maximizing Return) of these RL tasks. Based on this bi-level proximal policy optimization paradigm, we introduce a new algorithm named Preference based Proximal Policy Optimization (Pb-PPO). Pb-PPO utilizes a multi-armed bandit approach to refelect RL preference, recommending the clipping bound for PPO that can maximizes the current Return. Therefore, Pb-PPO results in greater stability and improved performance compared to PPO with a fixed clipping bound. We test Pb-PPO on locomotion benchmarks across multiple environments, including Gym-Mujoco and legged-gym. Additionally, we validate Pb-PPO on customized navigation tasks. Meanwhile, we conducted comparisons with PPO using various fixed clipping bounds and various of clipping approaches. The experimental results indicate that Pb-PPO demonstrates superior training performance compared to PPO and its variants. Our codebase has been released at : https://github.com/stevezhangzA/pb_ppo
- Openai gym, 2016.
- An adaptive clipping approach for proximal policy optimization, 2018.
- Approximately optimal approximate reinforcement learning. In International Conference on Machine Learning, 2002. URL https://api.semanticscholar.org/CorpusID:31442909.
- Continuous control with deep reinforcement learning, 2019.
- Playing atari with deep reinforcement learning, 2013.
- Human-level control through deep reinforcement learning. Nature, 518:529–533, 2015. URL https://api.semanticscholar.org/CorpusID:205242740.
- Dreamwaq: Learning robust quadrupedal locomotion with implicit terrain imagination via deep reinforcement learning, 2023.
- Trust region policy optimization, 2017a.
- Proximal policy optimization algorithms, 2017b.
- High-dimensional continuous control using generalized advantage estimation, 2018.
- Learning vision-guided quadrupedal locomotion end-to-end with cross-modal transformers, 2022.
- The surprising effectiveness of ppo in cooperative, multi-agent games, 2022.
- Behavior proximal policy optimization, 2023.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.