- The paper introduces Fin-R1, a 7B-parameter model trained via data distillation and reinforcement learning to enhance financial reasoning.
- It employs a two-stage pipeline combining Supervised Fine-Tuning and GRPO-based RL to refine decision-making and reasoning precision.
- Fin-R1 achieves state-of-the-art scores on benchmarks such as ConvFinQA (85.0) and FinQA (76.0), enabling cost-effective deployment.
Fin-R1: A Comprehensive Approach to Financial Reasoning Using Reinforcement Learning
Introduction
The application of LLMs in the domain of financial reasoning presents unique challenges tied to fragmented financial data, uncontrollable reasoning logic, and insufficient business generalization ability. "Fin-R1: A LLM for Financial Reasoning through Reinforcement Learning" introduces Fin-R1, a financial domain-specific LLM. Fin-R1's 7 billion parameter model is optimized using a two-stage training framework, significantly reducing deployment costs while enhancing its capability to tackle complex financial reasoning tasks.
Methodological Framework
Two-Stage Construction Framework
Fin-R1 is constructed through a robust two-stage framework:
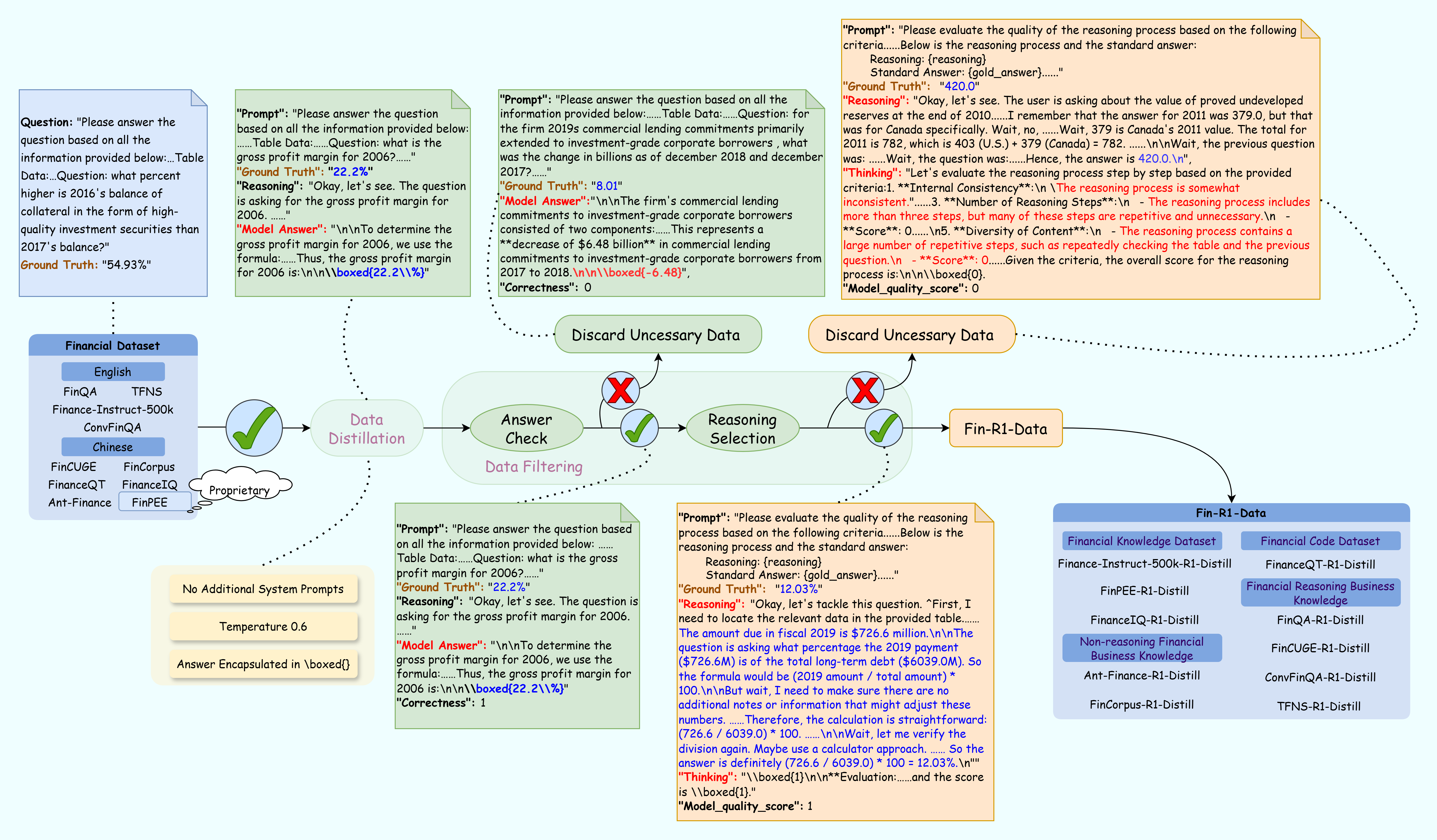
- Data Generation: This involves the creation of Fin-R1-Data, a high-quality dataset through data distillation and filtering techniques. The dataset is composed of approximately 60,091 complete chains of thought (CoT) spanning reasoning and non-reasoning scenarios.
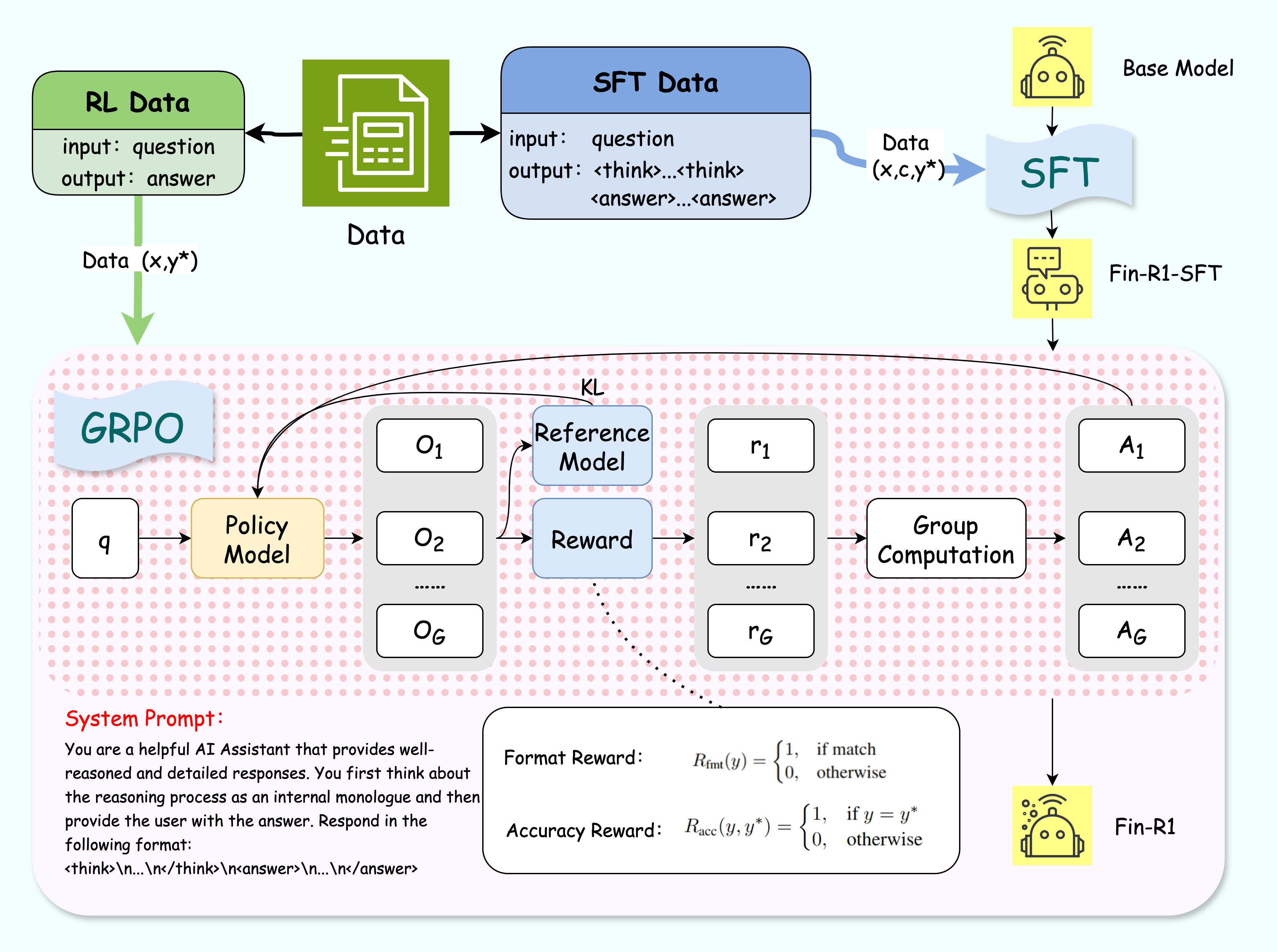
- Model Training: Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL), particularly employing GRPO (Group Relative Policy Optimization), are used to refine the model's decision-making processes and enhance its reasoning precision.
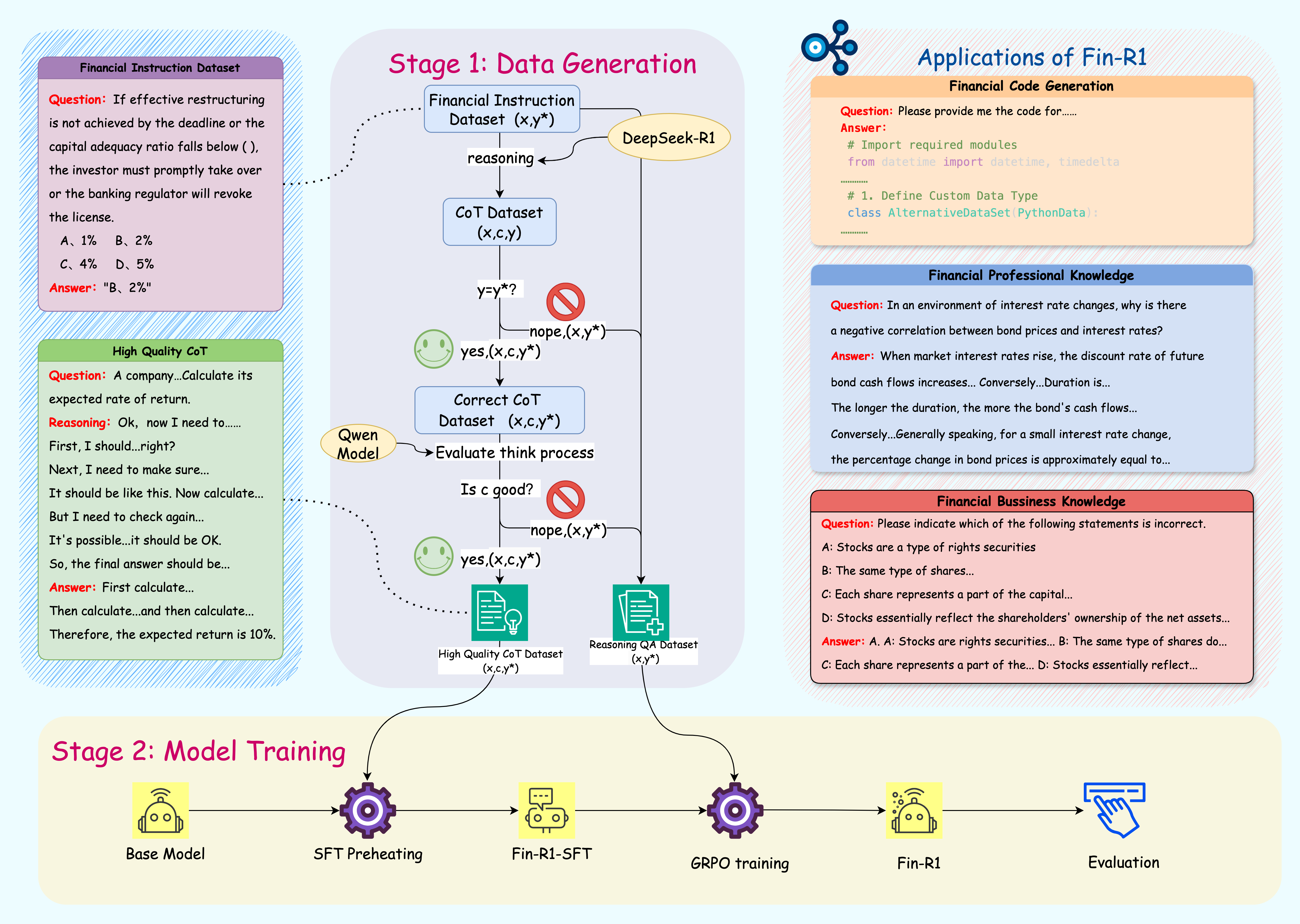
Figure 1: The pipeline for constructing Fin-R1. The diagram depicts the two-stage construction framework of Fin-R1.
Data Construction and Processing
The Fin-R1-Data integrates both open-source and proprietary datasets, providing a diverse range of financial contexts and tasks. A meticulous data construction pipeline is employed to ensure high data quality:
Training Methodology
Fin-R1 employs a combination of Supervised Fine-Tuning and Reinforcement Learning. The key elements include:
Experimental Evaluation
Evaluation Setup
The model's performance was validated using various financial benchmarks such as FinQA, ConvFinQA, Ant-Finance, TFNS, and Finance-Instruct-500k. Qwen2.5-72B-Instruct's judge performance was especially noted for its consistency in evaluations.
Results
Fin-R1 excelled across multiple tasks, achieving state-of-the-art scores of 85.0 in ConvFinQA and 76.0 in FinQA. Its compact structure allowed it to deliver superior performance using fewer computational resources compared to massive models like DeepSeek-R1-Distill-Llama-70B.


Figure 4: Heatmap comparison of reasoning scores between LLMs and human annotators.
Conclusion
The development of Fin-R1 demonstrates an effective model for integrating financial reasoning capabilities into LLMs, addressing challenges related to fragmented data and reasoning logic. Future directions include expanding dataset coverage and exploring multimodal architectures to further enhance FlexR1's performance and applicability in dynamic financial environments.
The implications of Fin-R1 are significant not only for enhancing automated reasoning capabilities but also for enforcing regulatory compliance and improving decision-making processes within the financial industry. Future work will focus on refining the model for broader financial applications, emphasizing integration with complex financial datasets and scenarios.