- The paper demonstrates that integrating dual RAG pipelines with external fact-checking yields a 10.4% improvement in F1 score over individual methods.
- The framework employs a three-tier adaptive strategy using cosine similarity thresholds and confidence-weighted voting to enhance transparency and handle uncertainty.
- FinVet’s modular multi-agent design facilitates scalability and adaptability for real-world financial applications and regulatory oversight.
Introduction
The proliferation of financial misinformation poses significant risks to market stability, investor decision-making, and regulatory oversight. Traditional deep learning and LLM-based approaches for misinformation detection in finance have demonstrated strong classification performance but are limited by a lack of transparency, insufficient source attribution, and inadequate handling of uncertainty. The FinVet framework addresses these limitations by integrating dual Retrieval-Augmented Generation (RAG) pipelines with an external fact-checking agent, orchestrated through a confidence-weighted voting mechanism. This architecture is designed to provide evidence-backed, explainable, and robust financial claim verification.
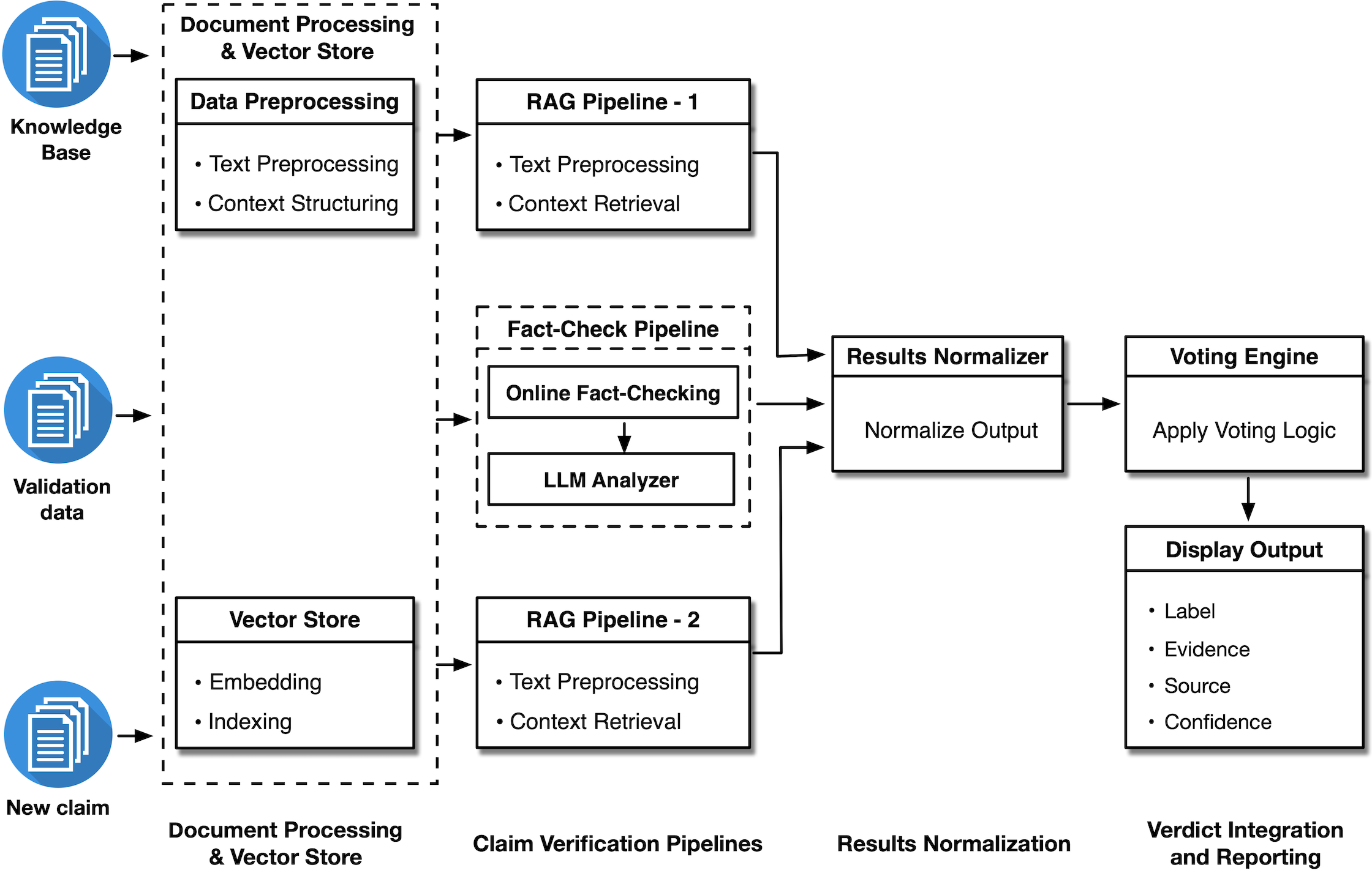
Figure 1: FinVet: A Collaborative Framework of RAG and External Fact-Checking Agents for Financial Misinformation Detection.
System Architecture
FinVet is structured as a multi-agent system comprising four primary components: (A) Data Processing and Vector Storage, (B) Claim Verification Pipelines, (C) Results Normalization, and (D) Verdict Integration and Reporting.
Data Processing and Vector Storage
Financial texts are decomposed into claim–evidence pairs, embedded using all-MiniLM-L6-v2 to generate 384-dimensional semantic vectors, and indexed via FAISS (IVFFlat). This enables efficient, high-precision retrieval of relevant evidence for downstream verification.
Claim Verification Pipelines
FinVet employs three independent verification pipelines:
- RAG Pipeline-1: Utilizes LLaMA-3.3-70B-Instruct for retrieval-augmented claim verification.
- RAG Pipeline-2: Employs Mixtral-8x7B-Instruct-v0.1, leveraging a Mixture-of-Experts architecture for complementary reasoning.
- Fact-Check Pipeline: Interfaces with the Google Fact Check API for external verification, with fallback to LLaMA-3.3-70B-Instruct for role-based LLM analysis when no external match is found.
Each RAG pipeline implements a three-tier adaptive processing strategy based on cosine similarity between the claim and retrieved evidence:
- High Similarity (≥0.6): Direct metadata extraction; label, evidence, and source are taken from the retrieved document.
- Moderate Similarity (0.4≤s<0.6): Hybrid context-model reasoning; the LLM evaluates the claim using retrieved context, with confidence as the mean of similarity and model self-assessment.
- Low Similarity (<0.4): Role-based prompting; the LLM generates evidence and verdict from multiple expert perspectives, with source marked as "Parametric Knowledge".
The Fact-Check Pipeline prioritizes external fact-check verdicts (confidence 1.0) and otherwise falls back to LLM-based analysis.
Results Normalization and Verdict Integration
Outputs from all pipelines are normalized to a unified schema (label, evidence, source, confidence). Verdict integration is performed via a hierarchical, confidence-weighted voting mechanism:
- If the Fact-Check Pipeline returns an external verdict, it is prioritized.
- Otherwise, the result with the highest confidence across all pipelines is selected.
- If all confidences are zero, the system returns "NEI" (Not Enough Information), explicitly flagging uncertainty.
Experimental Evaluation
Dataset and Baselines
FinVet was evaluated on the FinFact dataset, partitioned into 85% training and 15% testing splits. The vector store was populated with the training set, and all models were accessed via the Hugging Face API. Baselines included standalone RAG (LLaMA-3.3-70B), zero-shot and chain-of-thought (CoT) GPT-3.5-turbo, and ablated versions of the FinVet architecture.
FinVet achieved an F1 score of 0.85, representing a 10.4% improvement over the best individual pipeline (Fact-Check Pipeline, F1=0.77) and a 37% improvement over standalone RAG approaches (F1=0.62). Zero-shot GPT-3.5 and CoT prompting performed substantially worse (F1=0.51 and 0.45, respectively), highlighting the limitations of parametric-only reasoning in this domain.
Ablation studies confirmed the additive value of each component: integrating both RAG pipelines and fact-checking yields the highest performance, with each individual pipeline contributing incrementally to overall accuracy and robustness.
Explainability and Transparency
FinVet outputs not only a claim label but also supporting evidence, explicit source attribution, and a calibrated confidence score. The system is designed to flag uncertainty via "NEI" when evidence is insufficient, avoiding unwarranted classifications. This level of transparency is critical for high-stakes financial applications, where auditability and decision traceability are essential.
Implementation Considerations
- Computational Requirements: The framework relies on large LLMs (LLaMA-3.3-70B, Mixtral-8x7B) and efficient vector search (FAISS). Inference latency and cost can be mitigated by the three-tier adaptive processing, which invokes complex reasoning only when necessary.
- Extensibility: The modular architecture allows for the integration of additional RAG pipelines, domain-specific knowledge bases, or alternative fact-checking APIs.
- Bias and Fairness: The system's performance is contingent on the diversity and quality of the underlying knowledge base and external fact-checking sources. Regular audits and the inclusion of multiple, heterogeneous sources are recommended to mitigate bias.
- Deployment: For production, GPU-backed inference and scalable vector storage are required. The system can be deployed as a microservice, with APIs for claim submission and verdict retrieval.
Implications and Future Directions
FinVet demonstrates that hybrid architectures combining RAG, external fact-checking, and confidence-based integration outperform both standalone and parametric-only approaches for financial misinformation detection. The explicit handling of uncertainty and transparent reporting align with regulatory and ethical requirements in finance.
Future work should focus on:
- Expanding the knowledge base with regulatory filings, earnings reports, and multilingual sources.
- Fine-tuning LLMs on financial-domain instruction datasets.
- Incorporating user feedback loops for continuous improvement.
- Developing semantic-aware evaluation metrics for evidence quality and contextual relevance.
Conclusion
FinVet establishes a new standard for explainable, robust, and high-accuracy financial misinformation detection by integrating diverse verification pathways and prioritizing transparency. Its empirical performance and architectural flexibility make it a strong candidate for deployment in financial institutions, regulatory bodies, and oversight organizations seeking auditable and trustworthy AI-driven claim verification.

