- The paper introduces the Siren framework, which leverages collaborative RVQ transformers and reinforcement learning to address orthogonality and semantic degradation challenges.
- It distributes the RVQ code prediction task among multiple transformers with causal conditioning to improve interdependency and reduce learning friction.
- Experiments demonstrate that Siren outperforms existing language model and diffusion-based systems on benchmarks like AudioCaps, achieving state-of-the-art audio fidelity.
LLM Based Text-to-Audio Generation: Anti-Causally Aligned Collaborative Residual Transformers
Introduction
The work discusses the application of autoregressive LLMs (LMs) equipped with Residual Vector Quantization (RVQ) tokenizers in the field of text-to-audio (T2A) generation, and attempts to address their current limitations when compared to diffusion-based models. The authors acknowledge the benefits of higher audio reconstruction fidelity that come with increasing RVQ layers, but indicate the resulting complexity exceeds the generation capabilities of conventional LMs. The paper introduces the Siren framework, which leverages multiple isolated transformers alongside reinforcement learning for anti-causal alignment. This method aims to enhance audio synthesis fidelity, thus challenging the supremacy of diffusion models in T2A tasks.
Methodology
The authors of the paper identify two significant issues hindering the performance of RVQ-facilitated LMs: the orthogonality of features across RVQ layers, and the diminishing semantic richness in deeper layers. These problems affect both the training effectiveness of LMs and perpetuate exposure bias during autoregressive decoding.
To mitigate these issues, the Siren framework employs several key innovations. Siren distributes the RVQ code prediction task among multiple transformers—each tasked with a subset of the RVQ layers—in order to reduce the inherent learning friction within any single transformer. This is augmented through causal conditioning to preserve interdependency among RVQ codes. To further address semantic degradation and exposure bias, Siren implements reinforcement learning to align the outputs of the transformers, enhancing the fidelity and stability of generated audios.
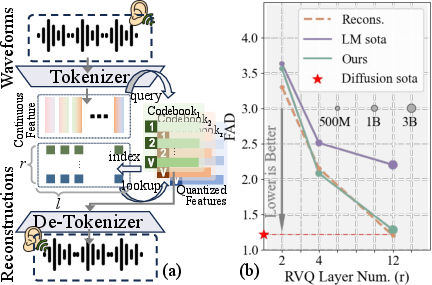
Figure 1: Residual Vector Quantization Process, showing the quantization sequences and their performance update as RVQ depth increases.
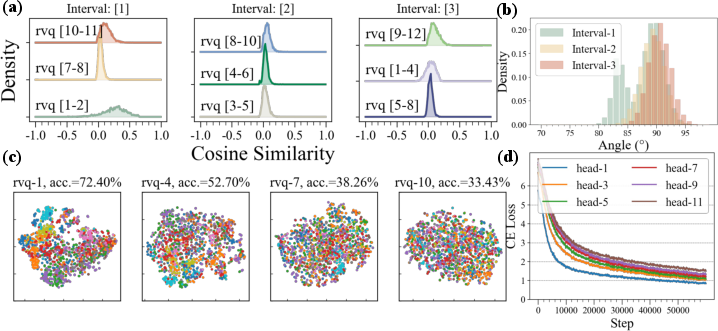
Figure 2: Demonstrates the orthogonality and semantic degradation challenges in RVQ with layer-specific feature distributions and learning curve disparities.
Experimental Results
The Siren framework was evaluated through extensive experimentation, demonstrating that it outperformed existing LM and diffusion-based T2A systems on key benchmarks like AudioCaps. By effectively bridging the representational gap between discrete LM tokens and continuous audio structures, Siren achieves superior fidelity in audio generation tasks. The framework showcases its ability to produce state-of-the-art audio outputs with enhanced clarity, aligning closer to diffusion model outputs, which have historically dominated due to their prowess in managing continuous data features.
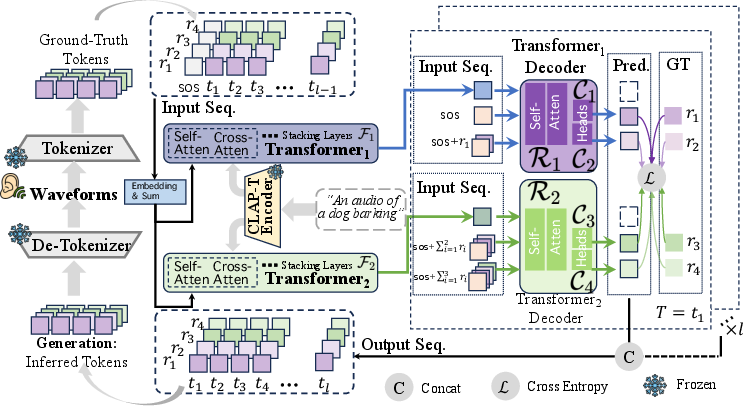
Figure 3: The pipeline of the proposed Siren framework, utilizing parallel transformers for efficient RVQ code predictions and audio waveform recovery.
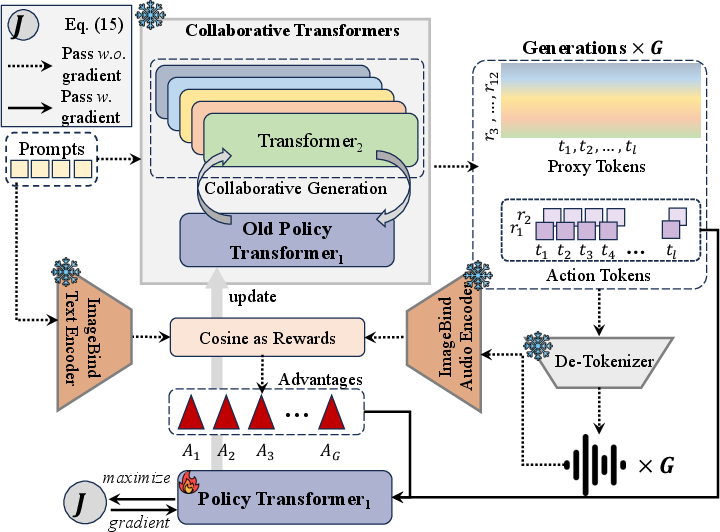
Figure 4: Reinforcement learning strategy in Siren used for aligning initial transformer outputs to enhance audio quality.
Implications and Future Directions
The advances presented by the Siren framework have notable implications in the T2A domain, suggesting LMs as viable competitors to diffusion models by harnessing collaborative and reinforcement learning strategies. This paradigm shift not only improves audio fidelity but also opens avenues for constructing more integrated, multi-modal generation frameworks that could extend beyond audio to synergize with visual and textual modalities.
Theoretically, future work may explore optimizing the collaborative training of transformers further, improving data efficiency and extending the application of anti-causal alignments in more granular sequence prediction tasks. Practically, enhancing tokenizer architecture to better capture high-level acoustic semantics appears to be a promising area for development, potentially reducing model size while maintaining output quality.
Conclusion
The research presents a comprehensive approach to overcoming the inherent challenges of applying LMs in T2A tasks. By resolving key barriers like RVQ feature orthogonality and semantic degradation through Siren's innovative framework, the paper sets a new benchmark for T2A systems, challenging diffusion models' dominance. Future advancements promise even greater integration across modalities, revolutionizing how audio generation is approached in AI research.