- The paper introduces a unified framework that integrates LLM reasoning with diffusion-based audio synthesis for generating long-form narrative audio.
- The system employs a progressive training paradigm, ensuring enhanced instruction-following, temporal alignment, and improved audio fidelity as validated on the AudioStory-10k benchmark.
- Ablation studies confirm that explicit event decomposition using semantic and residual tokens is critical for maintaining coherent scene transitions and emotional control.
AudioStory: A Unified Framework for Long-Form Narrative Audio Generation with LLMs
Motivation and Problem Definition
The generation of long-form narrative audio from complex, multimodal instructions remains a significant challenge in text-to-audio (TTA) research. While recent TTA models such as AudioLDM, TangoFlux, and Stable Audio have demonstrated high-fidelity synthesis for short audio clips, they lack mechanisms for temporal coherence, compositional reasoning, and consistent instruction-following over extended durations. The AudioStory framework directly addresses these limitations by integrating LLMs with diffusion-based audio generators in an end-to-end, instruction-following pipeline. The system is designed to decompose complex narrative instructions into temporally ordered sub-tasks, enabling the generation of coherent, multi-scene audio stories with explicit control over scene transitions, emotional tone, and event timing.
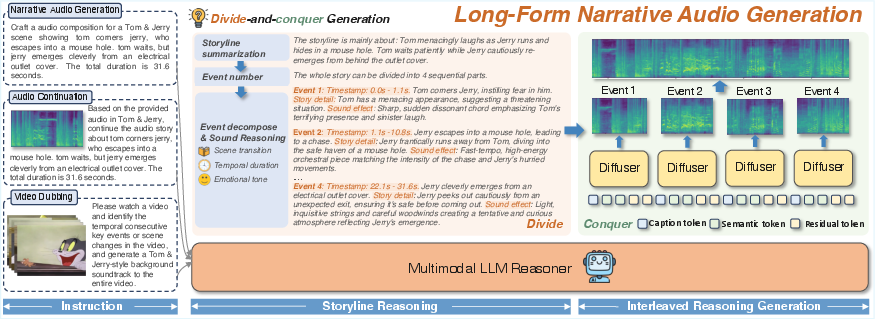
Figure 1: AudioStory decomposes multimodal instructions into a sequence of coherent audio segments, capturing scene transitions, emotional tone, and segment timestamps.
System Architecture and Decoupled Bridging Mechanism
AudioStory is architected as a unified understanding-generation model, with three principal components: (1) an LLM-based reasoning module, (2) a decoupled bridging mechanism, and (3) a DiT-based audio generator. The LLM first parses the multimodal instruction, decomposing it into a sequence of audio generation sub-tasks, each annotated with contextual cues such as timestamps and emotional tone. For each sub-task, the LLM generates both semantic tokens (encoding high-level audio semantics) and residual tokens (capturing low-level acoustic details and inter-event coherence). These tokens are fused and provided as conditioning inputs to the DiT, which synthesizes each audio segment.
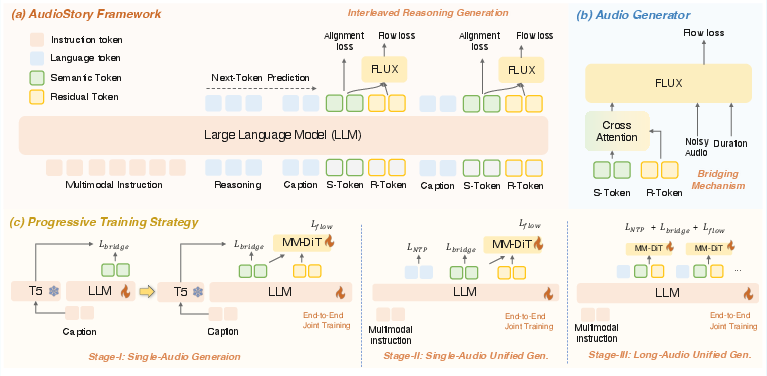
Figure 2: Overview of AudioStory, with LLM-based reasoning, decoupled bridging (semantic and residual tokens), and a three-stage progressive training strategy.
The decoupled bridging mechanism is a critical innovation. Unlike prior approaches that rely solely on text-based conditioning (e.g., T5 embeddings), AudioStory orthogonally disentangles semantic and residual information. Semantic tokens are supervised using textual features (e.g., Flan-T5), while residual tokens are optimized via the DiT loss to capture complementary low-level audio information. Multi-head cross-attention is employed to merge these tokens, ensuring both intra-event semantic alignment and inter-event temporal consistency.
Progressive End-to-End Training Paradigm
AudioStory employs a three-stage progressive training strategy to build synergy between understanding and generation:
- Stage I (Single-Audio Generation): The model learns to generate semantic tokens from captions, followed by joint regression of semantic and residual tokens, which are then used to condition the DiT for single-clip generation.
- Stage II (Unified Generation and Understanding): Audio understanding data is introduced, enabling the model to process audio inputs for comprehension tasks while maintaining generation capabilities.
- Stage III (Long-Audio Adaptation): The model is fine-tuned on multi-audio (long-form) datasets, leveraging interleaved reasoning to sequentially generate and align multiple audio segments.
This progressive approach is shown to be essential for mitigating task interference and maximizing the synergy between comprehension and generation. Notably, training generation first and then introducing understanding yields optimal results, while interleaved or reversed training orders degrade performance.
AudioStory-10k Benchmark and Evaluation Protocol
To support quantitative evaluation, the AudioStory-10k benchmark is introduced, comprising 10,000 annotated audio samples paired with narrative prompts across natural and animated sound domains. The dataset features fine-grained event annotations, timestamps, and reasoning trajectories, enabling comprehensive assessment of instruction-following, consistency, and generation quality. Evaluation metrics include CLAP score, FD, FAD, and Gemini-2.0-flash-based human-aligned scoring for instruction-following, consistency, and reasoning logic.
Empirical Results and Ablation Analysis
AudioStory demonstrates substantial improvements over both TTA and LLM-based baselines in long-form audio generation. On the AudioStory-10k benchmark, it achieves a 17.85% higher CLAP score for instruction-following compared to LLM+TTA models, and consistently outperforms in FD and FAD metrics for audio fidelity. The model is capable of generating coherent audio narratives up to 150 seconds, significantly exceeding the maximum durations of prior systems.
Ablation studies reveal several key findings:
- Interleaved Reasoning Generation: Removing reasoning or interleaved generation leads to severe degradation in instruction-following and audio quality, confirming the necessity of explicit event decomposition and segment-wise planning.
- Bridging Mechanism: Supervising semantic tokens with text features is more effective than audio features; residual tokens must be weakly supervised via the DiT loss to capture low-level details without introducing feature gaps.
- End-to-End Joint Training: Full unfreezing of DiT and the use of residual tokens are both essential for optimal performance and for mitigating conflicts between LLM and DiT during optimization.
- Residual Token Design: Eight residual tokens, merged via cross-attention, provide the best trade-off between information capacity and trainability.
Qualitative Analysis and Extended Applications
Qualitative cases illustrate AudioStory's ability to decompose complex instructions into temporally aligned audio events, accurately infer event durations, and maintain narrative and emotional coherence across segments.
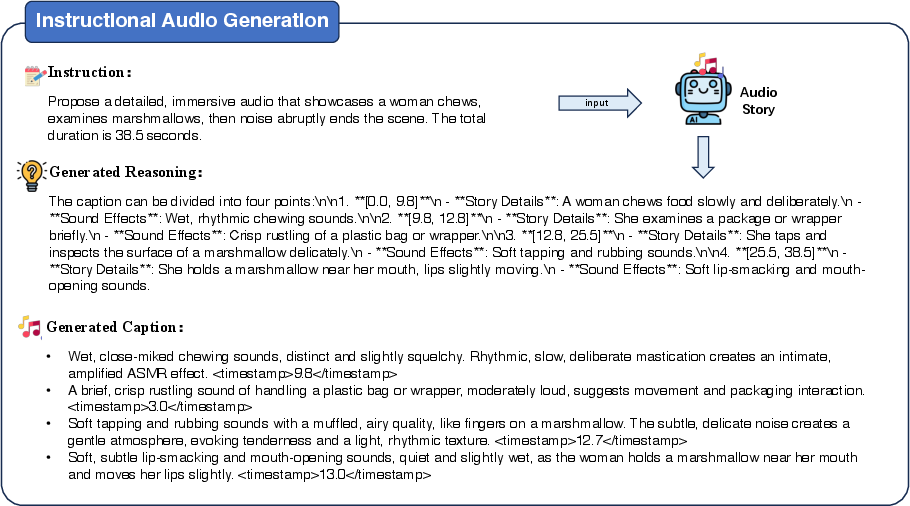
Figure 3: Qualitative case of long-form audio generation.
The framework generalizes to extended applications such as video dubbing and audio continuation. In video dubbing, AudioStory can process both video and instruction inputs, segment the narrative, and generate synchronized audio tracks aligned with visual content.
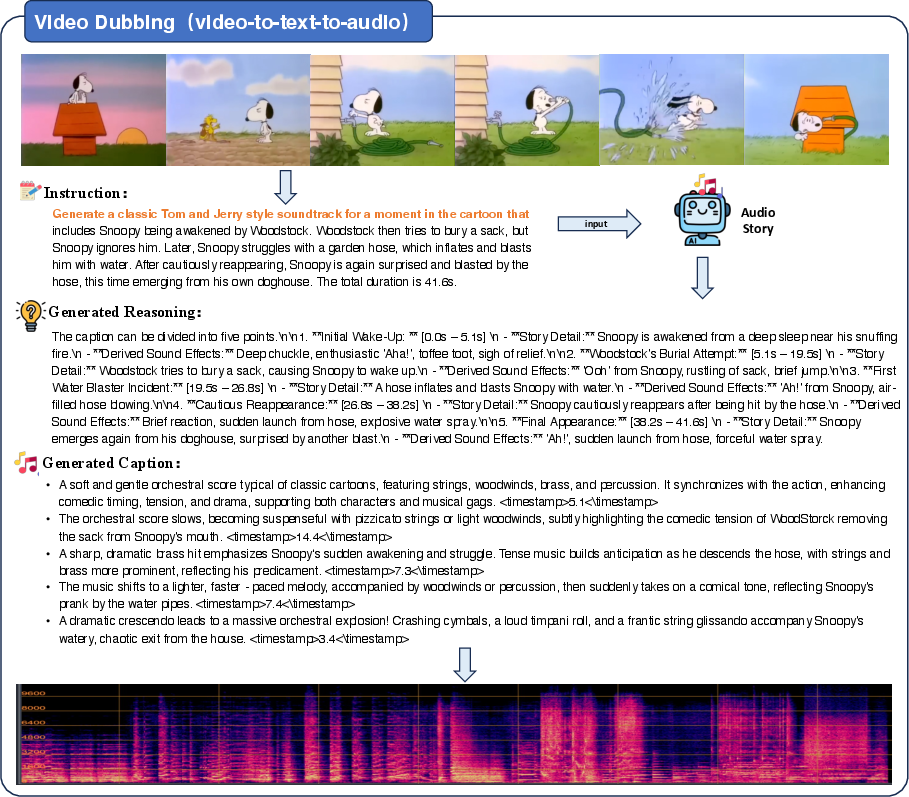
Figure 4: Case of naive video dubbing: captions extracted from video are used as instructions for audio generation.
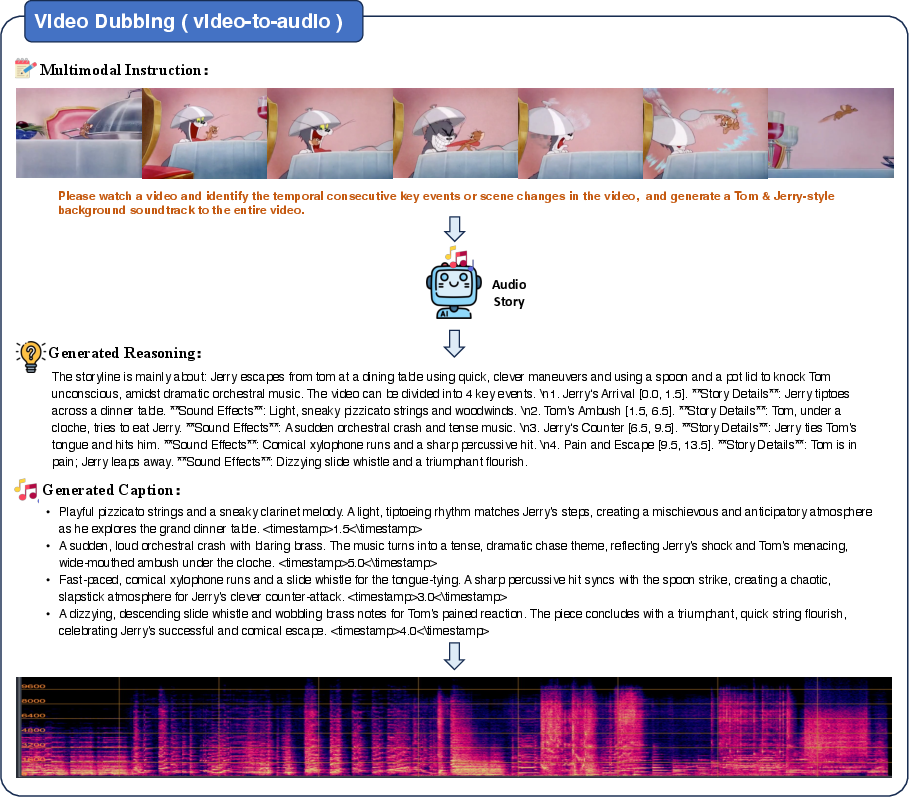
Figure 5: Case of video dubbing: the model parses the narrative into segments and generates aligned audio clips.
For audio continuation, the model reasons about the next events and generates temporally consistent extensions to existing audio streams.

Figure 6: Qualitative cases of audio continuation.
Implications and Future Directions
AudioStory establishes a new paradigm for long-form, instruction-followed audio generation by tightly integrating LLM-based reasoning with diffusion-based synthesis. The decoupled bridging mechanism and progressive training strategy are shown to be critical for achieving both high-fidelity and temporally coherent outputs. The release of AudioStory-10k provides a foundation for standardized evaluation and further research in narrative audio generation.
Practically, this framework enables applications in audiobook production, podcasting, interactive entertainment, and video post-production, where fine-grained control over narrative structure and audio consistency is required. Theoretically, the work highlights the importance of explicit reasoning and modular bridging in multimodal generative systems.
Future research directions include the integration of multiple audio generators to handle overlapping or polyphonic events, the development of fully autoregressive multimodal LLMs for unified text and audio generation, and deeper exploration of the synergy between audio understanding and generation within a single model.
Conclusion
AudioStory presents a unified, end-to-end framework for generating long-form narrative audio from complex multimodal instructions, leveraging LLM-based reasoning, a decoupled bridging mechanism, and progressive training. The system achieves state-of-the-art results in both instruction-following and audio fidelity, and its design principles provide a blueprint for future advances in multimodal generative AI. The AudioStory-10k benchmark further catalyzes progress by enabling rigorous, standardized evaluation of narrative audio generation systems.

