- The paper presents a training-free framework that uses LLM-based planning and decoupling of attention mechanisms for precise text-to-audio generation.
- It employs a non-overlapping time-window strategy and contextual latent composition to ensure seamless audio transitions and global consistency.
- Experimental results show state-of-the-art timing alignment and audio quality on datasets like AudioCaps and MusicCaps.
FreeAudio: Training-Free Timing Planning for Controllable Long-Form Text-to-Audio Generation
Introduction
The paper "FreeAudio: Training-Free Timing Planning for Controllable Long-Form Text-to-Audio Generation" (2507.08557) introduces a novel framework for text-to-audio (T2A) generation that addresses the challenges of precise timing control and long-form audio synthesis. Current T2A models often face limitations due to the scarcity of temporally-aligned audio-text datasets, which restricts their ability to manage complex text prompts with precise timing requirements. FreeAudio provides a training-free solution that leverages LLMs for planning and a suite of techniques to achieve high-quality, long-duration audio generation. The work posits significant improvements over both training-based and training-free methods by innovatively decoupling and aggregating attention mechanisms.
Methodology
LLM Planning
The FreeAudio framework begins with an LLM-based planning stage where input text and timing prompts are parsed to generate a sequence of non-overlapping time windows, each linked to a refined prompt:
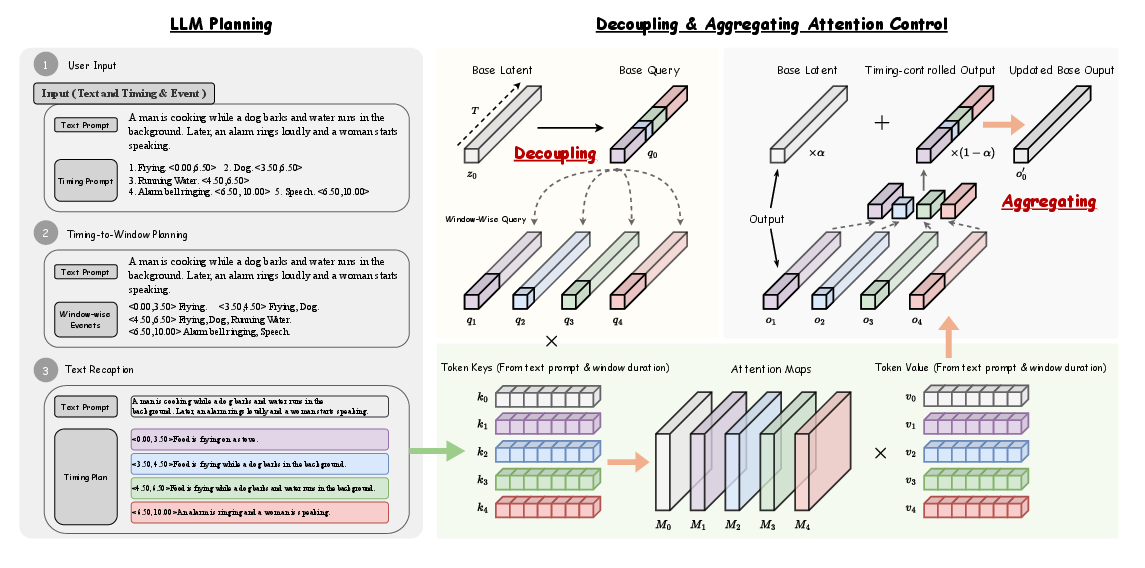
Figure 1: Left: Planning Stage, where the LLM parses the text prompt and timing prompts into a sequence of non-overlapping time windows, each associated with a recaptioned prompt. Right: Generation Stage, where the Decoupling {additional_guidance} Aggregating Attention Control aligns each recaptioned prompt with its corresponding time window, enabling precise timing control in attention layers.
This planning stage ensures that temporal overlaps and gaps in the input are accurately filled by leveraging the LLM's planning abilities, enabling the model to handle complex auditory sequences with coherent transitions.
Generation Technique
The generation phase employs Decoupling {content} Aggregating Attention Control, which allows for precise timing control by manipulating cross-attention and self-attention blocks. By segmenting and aligning audio outputs with the generated timing plan, FreeAudio achieves seamless transitions and consistent audio styles across different time windows.
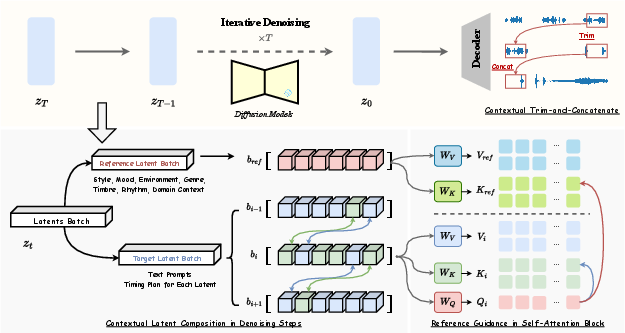
Figure 2: Top: Diffusion denoising process, where latents are progressively denoised and decoded into waveforms, followed by Contextual Cut-and-Concatenate to produce the final long-form audio. Bottom Left: Contextual Latent Composition, where overlapping regions between contextual latents are partially replaced to ensure smooth boundary transitions. Bottom Right: Reference Guidance in the self-attention block, where global consistency is preserved using features from reference latents.
Results and Evaluation
The paper provides extensive experimental evaluations demonstrating that FreeAudio achieves state-of-the-art performance among training-free methods and is on par with leading training-based approaches. The model shows significant improvements in timing alignment and audio generation quality across various datasets, including AudioCaps and MusicCaps, even in cases where standard models falter due to the lack of fine-grained temporal labels.
Quantitative results highlight FreeAudio's superiority in both objective metrics such as Fréchet Audio Distance (FAD) and subjective evaluations of audio quality and temporal precision. The innovative use of Contextual Latent Composition and Reference Guidance ensures global consistency even in long-duration outputs.
Implications and Future Work
FreeAudio's training-free approach offers a practical solution to some of the most challenging aspects of T2A generation, making it particularly valuable for applications in multimedia production and content creation. The methodologies introduced could inspire future work in enhancing temporal control in multimodal generative models without the heavy reliance on large, costly datasets.
In future research, further exploration into the scalability and adaptation of FreeAudio to broader, real-world scenarios is warranted. Investigating the integration of more sophisticated LLM capabilities and expanding the framework's application to other generative tasks could further solidify its utility in AI-driven content generation.
Conclusion
FreeAudio sets a new benchmark in controllable text-to-audio generation, balancing precision and quality without the need for conventional training. This paper not only provides a robust framework for solving current limitations in T2A synthesis but also lays the groundwork for future innovations in the field of audio generation.

