ScaleCUA: Scaling Open-Source Computer Use Agents with Cross-Platform Data
Abstract: Vision-LLMs (VLMs) have enabled computer use agents (CUAs) that operate GUIs autonomously, showing great potential, yet progress is limited by the lack of large-scale, open-source computer use data and foundation models. In this work, we introduce ScaleCUA, a step toward scaling open-source CUAs. It offers a large-scale dataset spanning 6 operating systems and 3 task domains, built via a closed-loop pipeline uniting automated agents with human experts. Trained on this scaled-up data, ScaleCUA can operate seamlessly across platforms. Specifically, it delivers strong gains over baselines (+26.6 on WebArena-Lite-v2, +10.7 on ScreenSpot-Pro) and sets new state-of-the-art results (94.4% on MMBench-GUI L1-Hard, 60.6% on OSWorld-G, 47.4% on WebArena-Lite-v2). These findings underscore the power of data-driven scaling for general-purpose computer use agents. We will release data, models, and code to advance future research: https://github.com/OpenGVLab/ScaleCUA.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-English Summary of the Paper
1. What is this paper about?
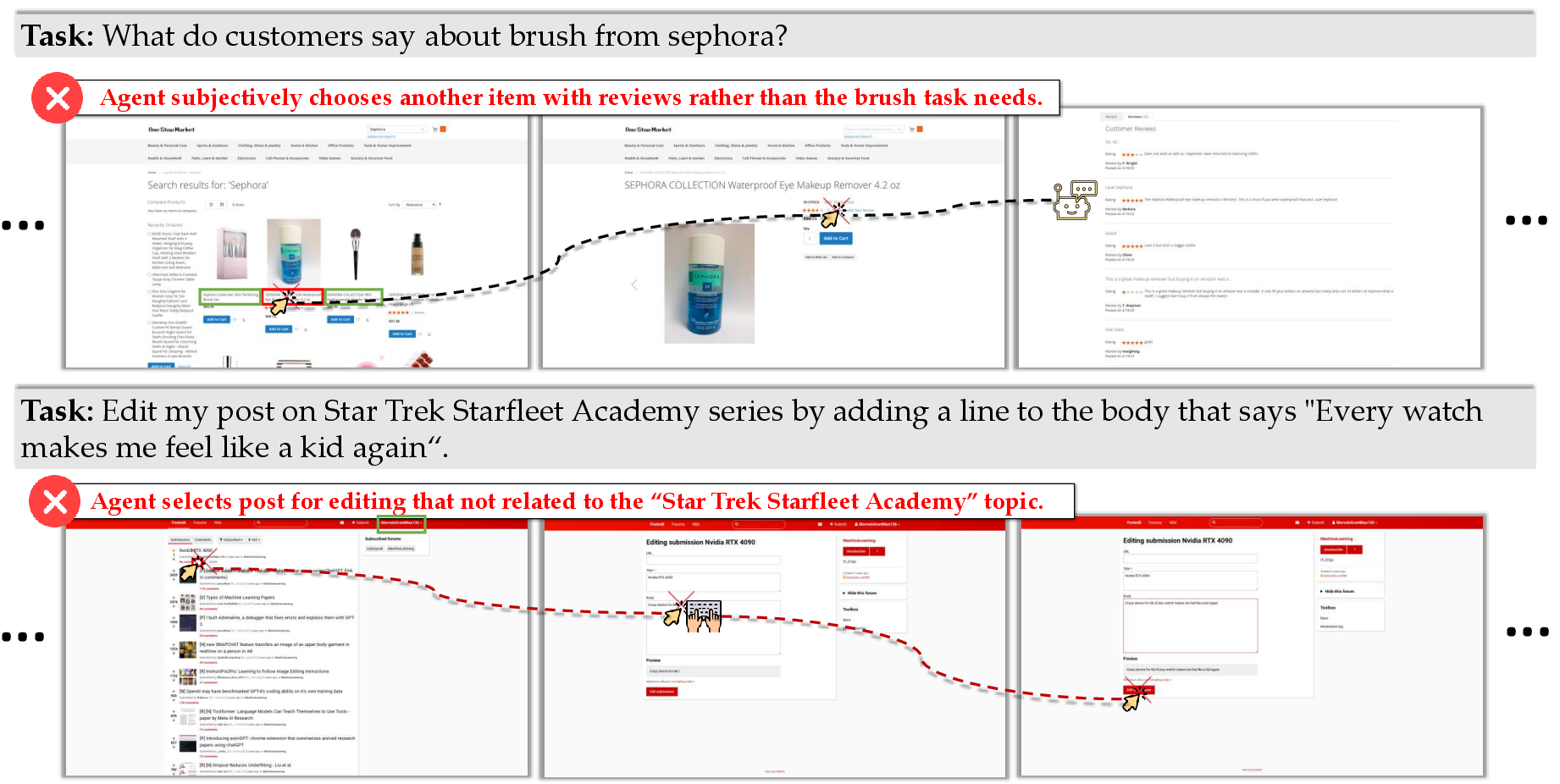
This paper is about teaching AI to use computers the way people do—by looking at the screen and clicking, typing, or dragging things on apps and websites. The team built big, open datasets and new AI models that can work across many platforms (Windows, macOS, Linux, Android, iOS, and the Web). Their goal is to make stronger, open tools that can control software on different devices, reliably and safely.
2. What questions did the researchers ask?
The researchers focused on a few simple questions:
- How can we get enough good-quality “how to use a computer” data so an AI can learn real software skills?
- Can one AI learn to work across many platforms (desktop, mobile, web) instead of only one?
- What’s the best way for an AI to act: just point to the right button, directly perform actions, or think through the plan step-by-step before acting?
- Does scaling up diverse data actually make these “computer-use agents” much better?
3. How did they do it? (Methods in everyday language)
Think of this project like training a smart helper that learns by watching screens and practicing actions.
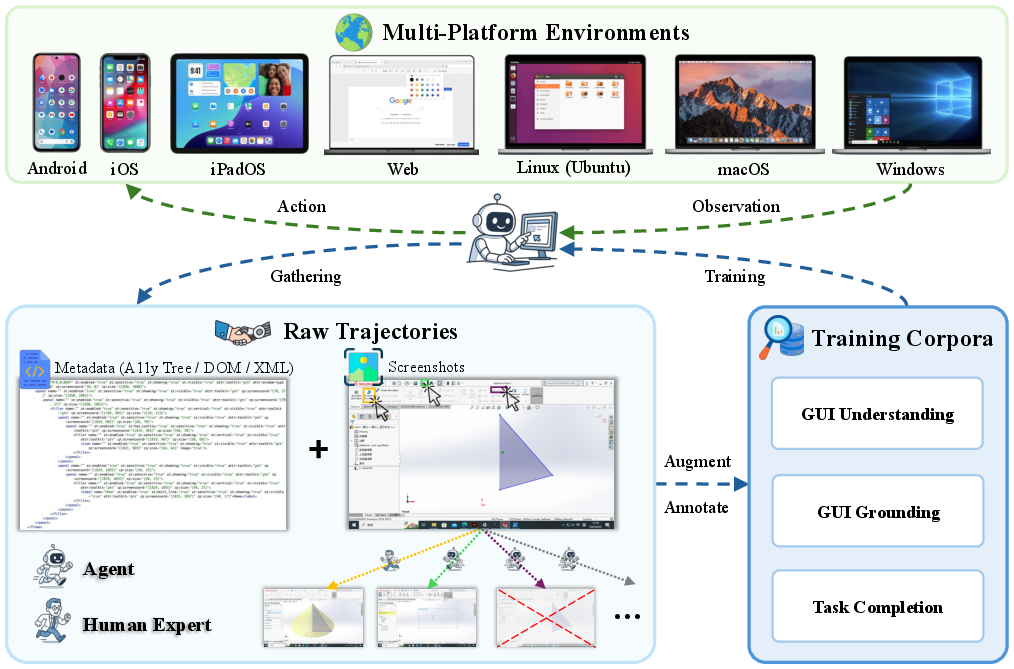
- Two-loop data pipeline (how they gathered training data):
- Agent–Environment Loop: Automated agents explore apps and websites, taking screenshots and trying actions. This is like sending a curious robot to “poke around” and see what’s there.
- Agent–Human Loop: Human experts also perform real tasks (like editing a document or changing settings) while the system records what happened. This adds high-quality, real-world examples.
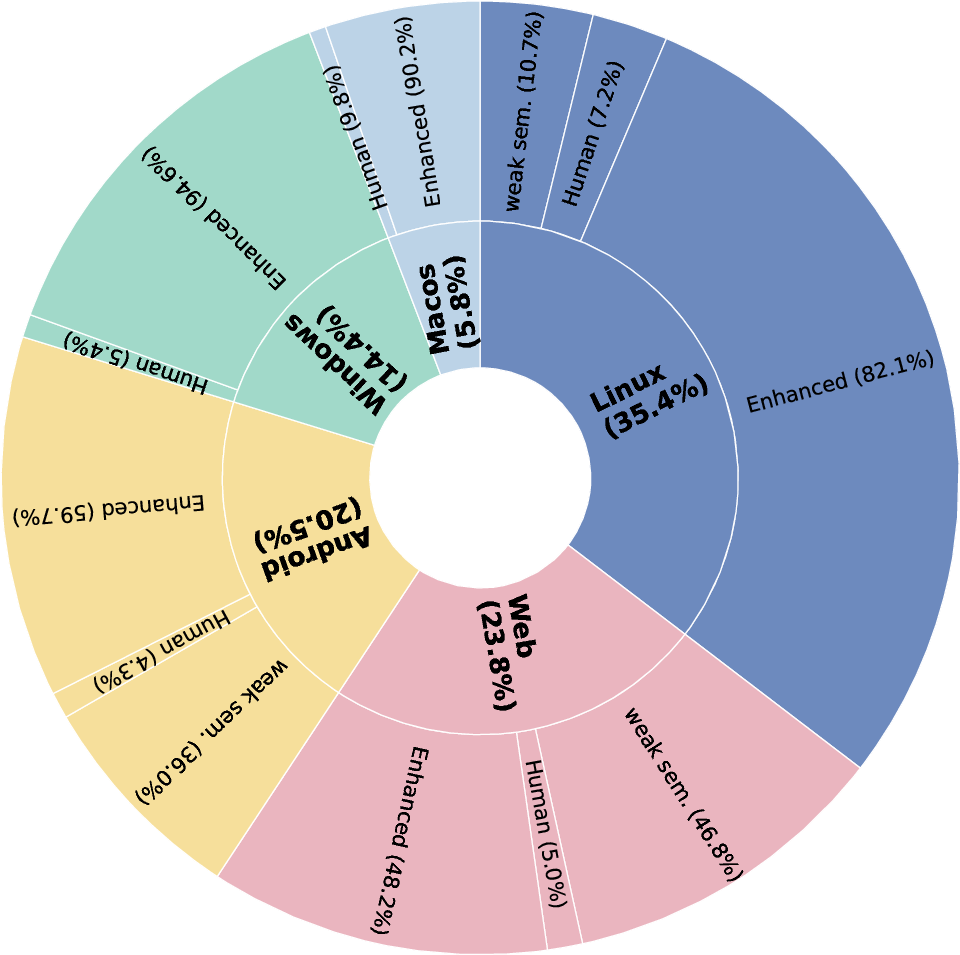
- What data they collected:
- Screenshots and “metadata” about the screen. Metadata is like a behind-the-scenes list of what’s on the screen—useful for screen readers—such as the Accessibility tree (A11y), the DOM on web pages, or app layout files. When this info is missing (for example, on iOS), they use a vision tool (OmniParser) to guess where buttons and text are.
- Three kinds of training tasks:
- GUI Understanding: Can the AI read what’s on screen, find text, describe layout, and notice changes? (About 471,000 examples)
- GUI Grounding: Can the AI find the exact spot to click or the box around an item based on a description like “Click the Settings gear”? (About 17.1 million labels—this is huge)
- Task Completion: Can the AI follow multi-step instructions to finish a job? They include “weakly labeled” explored paths and human-curated examples (about 19,000 total trajectories, averaging ~9 steps each).
- A unified action space (a universal remote for computers):
- They defined one consistent set of actions (click, type, scroll, long-press, open app, etc.) that works across desktop, mobile, and web. This makes training and using the AI much simpler.
- How they labeled so much data:
- They used strong AI annotators (like GPT-4o and Claude) to describe screens and elements, then applied data augmentation (cropping, resizing, etc.) to increase variety.
- The AI models they trained (called ScaleCUA):
- Built on top of a powerful vision-LLM (Qwen2.5-VL), they trained models that can see and read the screen and then act.
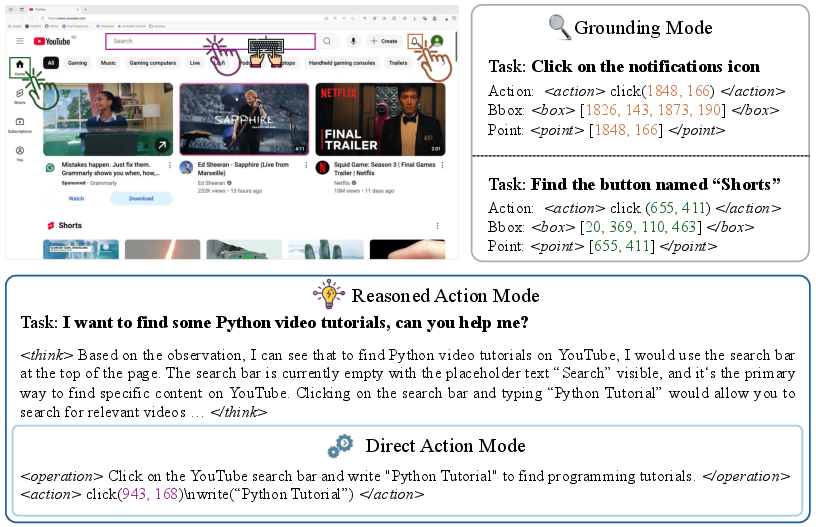
- Three ways the model can work:
- Grounding Mode: The model just finds the right place on the screen (like giving coordinates or a bounding box). This is handy when paired with a separate “planner” model.
- Direct Action Mode: The model directly clicks/types/etc. with minimal explanation. It’s fast and good for real-time tasks.
- Reasoned Action Mode: The model first writes a short thought process (why it’s doing something) and then acts. It’s slower but more reliable for tricky, multi-step tasks.
- Simple translations of technical terms:
- GUI: The visual stuff you see and interact with—windows, buttons, icons.
- Grounding: Matching words like “Open Settings” to the exact spot you must click.
- Trajectory: A replay of a task step-by-step, like a recipe of actions.
- Accessibility/DOM/Layouts: Hidden lists that describe what’s on a screen so tools (and AIs) can understand it better.
4. What did they find, and why is it important?
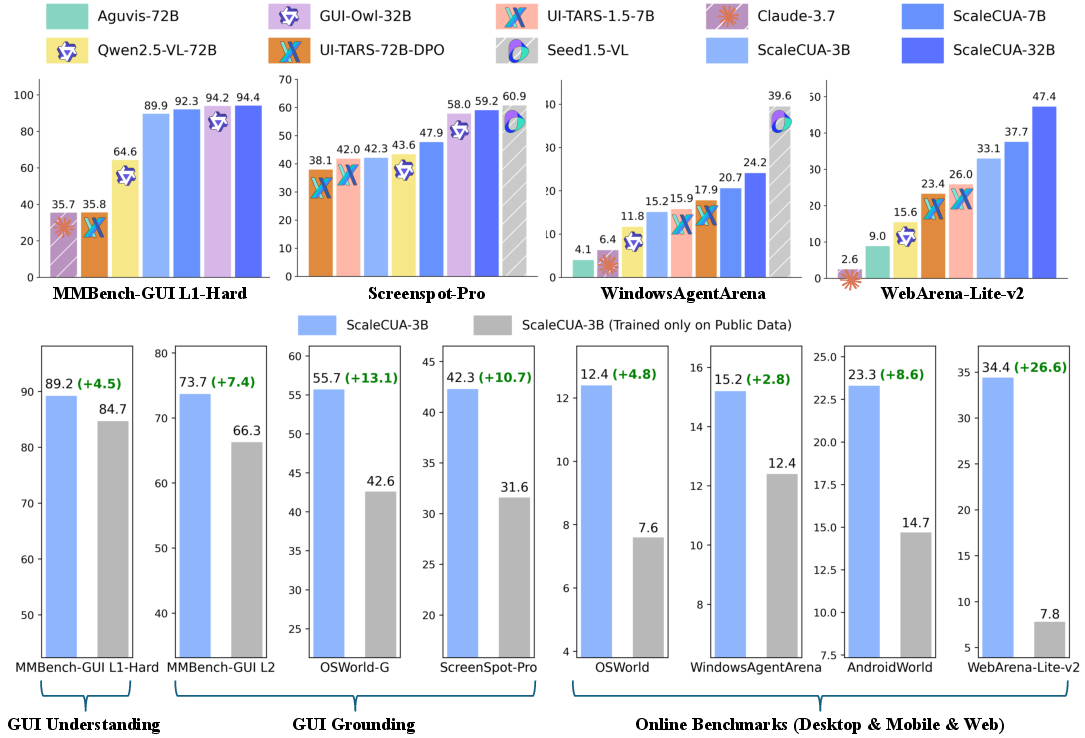
By collecting a lot of high-quality, cross-platform data and training on it, their AI agents got much better—often best-in-class—at using computers from screenshots alone.
Highlights:
- State-of-the-art on challenging GUI understanding and grounding tests:
- MMBench-GUI L1 Hard: 94.4% (top-tier performance in understanding complex screens)
- OSWorld-G: 60.6% (strong grounding on desktop tasks)
- ScreenSpot-Pro: large improvements over earlier baselines
- Big gains in real, interactive tasks:
- WebArena-Lite-v2: 47.4% success, a jump of +26.6 points over baselines
- Works across Windows, macOS, Linux, Android, iOS, and the Web with one unified interface.
- The three operating modes let the system adapt: fast direct control when speed matters, or careful “think-then-act” when accuracy matters.
Why this matters:
- In the past, these agents were limited by lack of data and didn’t generalize well. This paper shows that more and better cross-platform data really unlocks stronger, more reliable computer-use skills.
5. What’s the impact?
- Practical benefits:
- Better digital assistants that can actually help with real apps on different devices.
- More accessible tools for people who use assistive tech (since the AI understands and locates on-screen items well).
- Faster software testing and automation (the AI can learn to perform repetitive steps).
- Research benefits:
- They’re releasing the data, models, and code openly. This makes it easier for others to build on their work and push the field forward.
- Looking ahead:
- As apps and websites change, the data pipeline can keep collecting fresh examples.
- The three action modes give flexibility: pair with powerful planners, go fast for simple tasks, or reason deeply for complex ones.
- Care is still needed for privacy and safety (since the AI sees and controls screens), but this work shows a clear path to trustworthy, general-purpose “computer-use agents.”
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single consolidated list of what remains missing, uncertain, or unexplored in the paper, framed to be concrete and actionable for future research.
- Annotation provenance and quality: The dataset relies heavily on closed-source VLM annotators (GPT-4o, Claude); no reported human QA rates, inter-annotator agreement, or systematic bias analysis across platforms, domains, and languages.
- Metadata noise quantification: The paper notes missing attributes in A11y trees and reliance on OmniParser for iOS, but lacks quantitative measurements of bounding-box/attribute errors by platform and their downstream impact on grounding and task completion.
- Pure-visual design trade-offs: The decision to avoid A11y/DOM at inference is not compared against hybrid approaches; open whether combining structured signals with vision can improve reliability, latency, or long-horizon planning.
- Data coverage transparency: The corpus scale is presented, but app/site counts per platform, domain distribution (e.g., productivity vs entertainment), and coverage of common vs niche software are not documented, limiting assessment of generalization.
- Train–test leakage checks: There is no explicit analysis of potential content overlap between training data and evaluation benchmarks (OSWorld(-G), ScreenSpot variants, WebArena-Lite-v2), nor procedures to ensure disjoint app/version/site splits.
- Long-horizon interactions: Average trajectory length (~9 steps) and limited high-level goal trajectories may be insufficient for multi-window, cross-application workflows; need benchmarks and data for 50–100+ step tasks and recovery from detours.
- Weak-semantic trajectories: The effect of goal-free random-walk traces on planning is not isolated; open whether adding intent inference or synthetic high-level goals improves task completion and reduces spurious action sequences.
- Exploration strategy efficacy: Depth-first random exploration with heuristic pruning lacks coverage metrics (e.g., unique state ratio, transition graph diameter) and comparisons against curiosity, novelty, or skill-discovery exploration.
- Dataset obsolescence management: The paper notes rapid GUI evolution but provides no maintenance cadence, continual refresh strategy, or curriculum for continual learning to mitigate drift.
- Multilingual and RTL GUIs: Language coverage (e.g., Chinese, English, other scripts), RTL layouts, and mixed-language interfaces are not characterized; cross-lingual OCR/grounding and instruction-following robustness remain untested.
- Accessibility and theme robustness: No evaluation across accessibility settings (high contrast, large fonts, screen zoom), dark/light themes, or custom skins; need stress tests on DPI scaling (720p–4K), multi-monitor, and window tiling.
- Gesture/action coverage on mobile and desktop: The unified action space mentions some mobile-specific actions but does not clarify support for drag-and-drop, multi-touch gestures (pinch, rotate), long-scroll, hover, or IME complexities; coverage and accuracy benchmarks are needed.
- Secure and sensitive interactions: Handling of authentication (logins, 2FA), captchas, password fields, purchases, and OS permission prompts is not addressed; safety policies, sandboxing, and redaction of PII in released data remain unspecified.
- Error recovery and resilience: The agents’ ability to detect mistakes, backtrack, undo actions, and recover from unexpected UI states or modal dialogs is not analyzed; need standardized failure mode benchmarks and resilience metrics.
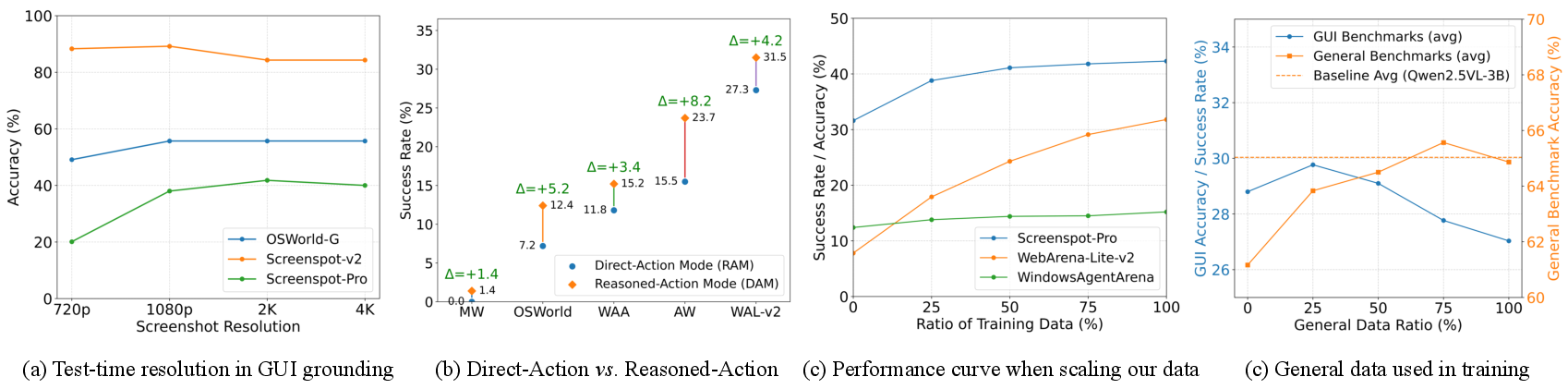
- Mode trade-offs (grounding vs direct vs reasoned): Latency, token cost, and success-rate trade-offs among the three inference paradigms are not quantified across platforms and tasks; guidance on when to use each mode remains anecdotal.
- Data mixture ratios: The chosen ratios of general-purpose vs GUI-specific data (25–75%) lack ablation and scaling law analyses; optimal mixtures for different model sizes and tasks are unknown.
- RL or online fine-tuning: Training relies on SFT; the gains from reinforcement learning, offline RL, or hybrid supervised+RL fine-tuning with environment feedback are unstudied.
- Memory design: The effectiveness of storing “low-level instruction” text vs structured memory/state machines for long-horizon tasks is not evaluated; open which memory designs best minimize latency while preserving context.
- Cross-platform transfer: No direct experiments training on one platform (e.g., Windows) and zero-shot testing on another (e.g., macOS/iOS) to quantify transferability of the unified action space.
- Resolution and device variability: Grounding was evaluated at fixed resolutions (e.g., 1080p, 2K); performance across varied DPI, scaling settings, window sizes, and device form factors (phones/tablets) is unreported.
- Temporal robustness to app updates: Lack of controlled tests on version changes, A/B UI experiments, or dynamic web content updates; need protocols to measure time-based generalization and adaptation.
- WebArena-Lite-v2 validity: The paper modifies the benchmark but does not provide independent validation that task pruning preserves difficulty and diversity; generalizability to other web suites (e.g., Mind2Web, WebShop) is untested.
- Grounding dataset biases: OSWorld-G screenshots are sampled by prior systems; risk of overfitting to “model-sampled” distributions remains; need human-sampled or random baselines for unbiased grounding evaluation.
- Per-domain error analysis: ScreenSpot-Pro categorizes usage domains, but a detailed failure taxonomy (e.g., icons vs text, toolbar vs context menu, dynamic overlays) is absent; actionable error breakdowns could guide data collection.
- Structured perception integration: No benchmarks comparing pure-vision vs vision+DOM/A11y fusion for disambiguating small targets, occlusions, or visually similar elements; hybrid methods could reduce click errors and latency.
- Safety and guardrails: No constraints or policy layer to prevent destructive actions (file deletion, settings changes), external transactions, or privacy breaches; need a safe action filter and incident logging.
- Deployment cost and throughput: Inference latency, GPU/CPU requirements, memory footprint, and throughput under real-time constraints (e.g., games) are not reported; engineering guidance for production deployment is missing.
- Human annotation protocol: Instructions given to expert annotators, consistency checks, and inter-annotator variability are not documented; reproducibility and annotation quality controls need specification.
- Reasoning correctness: The correctness and utility of “think” traces are not evaluated; open how often reasoning aligns with actions, reduces errors, or contributes to explainability without hallucinations.
- Non-standard input devices and layouts: Stylus, trackpad hover, hardware keyboards, multi-monitor setups, and window managers (tiling/stacking) are unaddressed; robustness to diverse input modalities remains unknown.
- Multi-agent orchestration: The paper mentions compatibility with agentic workflows, but does not quantify end-to-end performance, token budgets, or coordination overhead when combined with external planners/memories/tools.
- Licensing and ethics of released data: Data licensing terms, redistribution constraints, and compliance with app terms-of-service are not detailed; ethical review processes and consent for recorded GUIs are unclear.
Glossary
- Accessibility Trees (A11y Trees): Platform-provided hierarchical structures exposing UI elements and properties for accessibility and automation. "For desktop environments (Windows, Ubuntu, macOS), interface layouts and UI element coordinates are generally accessible via Accessibility Trees (A11y Trees)."
- Action grounding: Linking a textual instruction to a specific UI action on a target region or element. "and (3) action grounding connects spatial targets with low-level commands."
- Agent-Environment Interaction Loop: A data-collection loop where agents interact with GUIs by observing and acting to generate trajectories. "The Agent-Environment Interaction Loop enables automated agents to interact with diverse GUI environments"
- Agent-Human Hybrid Data Acquisition Loop: A collection process combining automated and expert demonstrations to ensure coverage and quality. "the Agent-Human Hybrid Data Acquisition Loop integrates expert-annotated trajectories to ensure coverage and quality."
- Agentic workflows: Multi-agent or tool-augmented processes coordinating planning, grounding, reflection, and memory for decision-making. "Despite strong performance, agentic workflows typically exhibit high computational latency and significant token consumption,"
- Bounding box grounding: Localizing a rectangular region corresponding to a UI target referred to in language. "(2) bounding box grounding localizes regions for region-based operations,"
- Chain-of-action-thought: Annotated sequences that interleave actions with intermediate reasoning steps. "AitZ constructs 18,643 screen-action pairs together with chain-of-action-thought annotations."
- Chain-of-thought: Intermediate natural language reasoning generated before deciding on an action. "Reasoned Action Mode refers to a chain-of-thought process before generating actions."
- Closed-loop pipeline: A data/agent training pipeline where outputs feed back into inputs for continual collection and improvement. "via a closed-loop pipeline uniting automated agents with human experts."
- Coordinate-referenced actions: Low-level controls that specify spatial coordinates (e.g., clicks) tied to grounded locations. "coordinate-referenced actions (e.g., click, doubleClick,moveTo, etc.),"
- Cross-Platform Interactive Data Pipeline: The paper’s two-loop framework for collecting GUI data across desktop, mobile, and web. "we present a Cross-Platform Interactive Data Pipeline composed of two synergistic loops."
- Data augmentation: Techniques to increase data diversity or robustness by transforming images, text, or trajectories. "and also explore data augmentations to further enhance diversity."
- Deduplication: Removing repeated or near-duplicate states/trajectories to improve dataset diversity and quality. "After deduplication, this simple method achieves substantially broader GUI coverage."
- Depth-first search (DFS): A graph/search strategy that explores one branch fully before backtracking, used here for GUI exploration. "Our rule-driven agents perform exploration using a depth-first search (DFS) strategy,"
- Direct Action Mode: An inference mode where the model outputs executable actions directly without intermediate reasoning. "Direct Action Mode requires the model to efficiently predict executable actions directly, without generating any intermediate reasoning steps or extraneous outputs."
- Docker containers: Lightweight virtualized environments for reproducible software execution and evaluation. "such as virtual machines or Docker containers."
- Document Object Model (DOM): The browser’s tree-structured representation of a web page used for element access and manipulation. "Web platforms provide element information through Document Object Model (DOM) structures rendered by browsers."
- End-to-end: Training or inference that maps inputs to outputs in a single model without modular decomposition. "native computer use agents~... integrate planning and grounding into a unified model trained end-to-end."
- Grounding Mode: An inference mode focused on localizing target UI elements (points/boxes) given language. "Grounding Mode represents the model only focuses on the UI element localization."
- Heuristic pruning: Rules or heuristics used to cut unpromising branches during search to improve efficiency. "To improve efficiency, heuristic pruning is applied to reduce redundant or uninformative branches during search."
- Inference paradigms: Distinct operational modes (grounding, direct action, reasoned action) for deploying the agent. "support three distinct inference paradigms to offer enhanced flexibility and compatibility with various agent frameworks"
- Long-horizon: Tasks requiring many sequential steps and sustained planning to complete. "offering 2,350 long-horizon open-ended tasks."
- Memory-augmented: Approaches that enhance decision-making by storing and using past information beyond immediate context. "across planning, reflection, and memory-augmented decision-making."
- Metadata: Structured auxiliary information (e.g., trees, layouts) accompanying screenshots or interactions. "metadata (e.g., A11y Trees, XLM, DOM structures, etc.),"
- Multimodal: Involving multiple data types (e.g., vision and language) for perception and reasoning. "curates a large-scale dataset with multimodal grounding and reasoning annotations"
- Native computer use agents: Single-model agents that jointly perceive, plan, and act, predicting low-level controls from pixels. "In contrast to modular agents, native computer use agents~... integrate planning and grounding into a unified model trained end-to-end."
- OCR: Optical Character Recognition; extracting text from images/screens for downstream understanding. "GUI Understanding with 471K examples covering regional captioning, OCR, and layout comprehension, etc.;"
- OmniParser: A vision-based tool to estimate UI element regions when structured layout data are missing. "we employ OmniParser~\citep{yu2025omniparser} to estimate bounding boxes of UI elements,"
- Planner–grounder paradigm: A modular agent design where a planner decides what to do and a grounder localizes targets. "These agents typically operate within the plannerâgrounder paradigm"
- Pixel-level perception: Fine-grained visual understanding at the level of screen pixels to enable precise interaction. "allowing agents~... to achieve pixel-level perception and interaction on graphical user interfaces."
- QA (Question Answering): Tasks where the model answers questions about a screen or UI elements. "These annotations support QA and grounding tasks."
- Random-walk agent: An exploration agent that selects actions stochastically to cover diverse states. "the second strategy utilized a ruleâdriven randomâwalk agent."
- Reasoned Action Mode: An inference mode that first generates an explicit rationale before outputting an action. "Reasoned Action Mode refers to a chain-of-thought process before generating actions."
- Screen Transition Captioning: Descriptions summarizing how a screen changes between states over time. "and Screen Transition Captioning to describe state changes over time."
- Selenium: A web automation framework that controls browsers via DOM-level operations. "Early approaches, such as Selenium\footnote{https://github.com/SeleniumHQ/selenium}, which leverages DOM parsing for web automation,"
- Supervised Fine-Tuning (SFT): Post-pretraining optimization using labeled data to align model behavior with tasks. "pre-training or SFT stages,"
- Token consumption: The number of model tokens processed, often driving cost and latency in LLM-based agents. "agentic workflows typically exhibit high computational latency and significant token consumption,"
- UI element localization: Predicting the position/region of a UI element referenced in an instruction. "supporting more accurate UI element localization;"
- Unified action space: A standardized set of cross-platform actions enabling consistent agent control across environments. "A unified action space allows agents to generalize core behaviors while retaining the flexibility to exploit environment-specific actions."
- vLLM: An optimized inference framework for serving large language/vision-LLMs efficiently. "we use vLLM\footnote{https://github.com/vllm-project/vllm}~\citep{kwon2023efficient} to deploy QwenVL models."
- Virtual machines: Isolated OS instances used to host and evaluate agents reproducibly. "such as virtual machines or Docker containers."
- Vision-LLMs (VLMs): Models that jointly process images and text to enable multimodal understanding and actions. "Vision-LLMs (VLMs) have enabled computer use agents (CUAs) that operate GUIs autonomously with great potential."
- Weak-semantic trajectories: Interaction sequences lacking explicit high-level goals but still useful for learning patterns. "with over 15K weak-semantic trajectories"
- XML layout files: Structured Android UI descriptions used to extract element positions and properties. "For Android applications, UI element locations are available through parsed XML layout files."
- XML tags: Markup wrappers used to format model outputs in a structured way. "The outputs generated by models are formatted in XML tags."
- GUI Grounding: Tasks that map natural language to the spatial locations of UI targets. "GUI Grounding with 17.1M training samples supporting more accurate UI element localization;"
- GUI Understanding: Perception and reasoning tasks over UI content, structure, and intent. "GUI Understanding with 471K examples covering regional captioning, OCR, and layout comprehension, etc.;"
Collections
Sign up for free to add this paper to one or more collections.

