- The paper presents a novel framework where SEAgent autonomously learns to master diverse software through experiential trial-and-error learning.
- It employs a unique curriculum generator and specialist-to-generalist strategy to progressively evolve task complexity and improve agent performance.
- Evaluation across multiple environments shows significant improvements in success rates (from 11.3% to 34.5%), demonstrating the efficacy of its self-evolving methodology.
SEAgent: Self-Evolving Computer Use Agent with Autonomous Learning from Experience
Introduction to SEAgent Framework
The SEAgent framework introduces an innovative approach to the development of Computer Use Agents (CUAs) capable of autonomously exploring and mastering unfamiliar software through experiential learning. Unlike traditional methods that rely heavily on human-labeled data, SEAgent leverages a self-evolving framework to autonomously learn and adapt to novel software environments. This includes exploring new software applications, learning through iterative trial-and-error, and progressively enhancing its capabilities by auto-generating and tackling tasks organized from simple to complex.
SEAgent's architecture includes a World State Model for precise trajectory assessments and a Curriculum Generator that autonomously develops increasingly complex tasks. Additionally, SEAgent utilizes a specialist-to-generalist training strategy that allows the integration of individual specialist agents' insights, resulting in a robust generalist CUA capable of continuous autonomous evolution.
Autonomous Exploration and Learning Pipeline
The SEAgent architecture enables CUAs to operate autonomously via a novel autonomous exploration and experiential learning pipeline. This involves several core components: the Actor Model for task execution, the World State Model for environmental feedback, and the Curriculum Generator for task evolution.
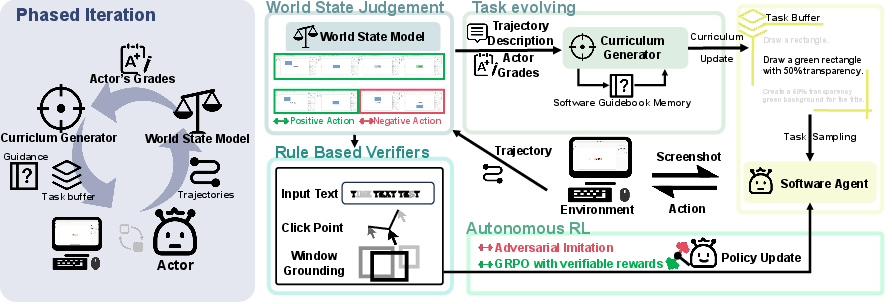
Figure 1: SEAgent autonomous exploration and experiential learning pipeline. Guided by tasks generated by the Curriculum Generator, the Actor Model is updated according to step-level rewards from the World State Model through verifiable reward functions tailored for different action types.
Key Components:
- Actor Model: Executes actions according to the current policy and derives lessons from the task feedback.
- World State Model: Provides detailed success/failure analyses and feedback for each action, enhancing experiential learning.
- Curriculum Generator: Develops a curriculum of tasks that progressively challenge the Actor Model, facilitating autonomy in exploration and learning.
Reinforcement Learning from Experience
SEAgent leverages Reinforcement Learning (RL) from experience to refine its actions and policies. It uses both adversarial imitation to penalize failure actions and Group Relative Policy Optimization (GRPO) to reward correct ones. This methodology diverges from traditional RL methods by emphasizing step-level learning, allowing CUAs to adaptively enhance their operational proficiency across diverse software environments.
Specialist-to-Generalist Training Strategy
One innovative aspect of SEAgent is its ability to convert specialized expertise into generalized proficiency. Initially, agents are trained as specialists in single software environments. This specialized knowledge is later generalized through supervised and reinforcement fine-tuning, allowing SEAgent to transcend the limitations of single-environment specialization and perform effectively across multiple applications.
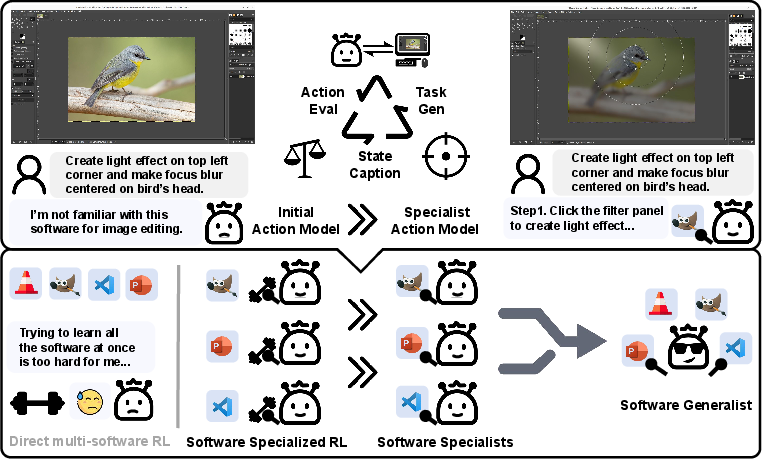
Figure 2: SEAgent enables computer use agents self-evolving in novel environments by autonomously exploring and learning from their own experiences without human intervention.
The effectiveness of SEAgent is demonstrated across multiple software environments, significantly outperforming previous CUAs by improving success rates from 11.3% to 34.5% in various tests. This notable enhancement is attributed to SEAgent’s self-evolution strategy and robust architecture, which integrates experiential learning with sophisticated task evolution processes. The training strategy, marked by the specialist-to-generalist transition, facilitates superior generalization capabilities compared to conventional RL models.

Figure 3: Self-evolved task instructions and success rate (SR) curves across different software. Tasks are progressively upgraded by the Curriculum Generator without human intervention, based on the evolving capabilities of the Actor Model at different training phases.
Conclusion
SEAgent exemplifies a progressive step forward in autonomous agent development, demonstrating substantial advancements in self-evolution and cross-environment adaptability of CUAs. Through the integration of autonomous exploration, experiential learning, and the specialist-to-generalist training strategy, SEAgent effectively transcends traditional reliance on human-labeled data and sets a precedent for future developments in autonomous technology and AI applications. The ability to autonomously generate tasks and adaptively refine policies augments the potential for CUAs across a myriad of applications and environments, marking a significant milestone in AI research and development.