- The paper demonstrates that planning and reflection processes in CUAs significantly increase overall task latency.
- The study introduces OSWorld-Human, a manually annotated dataset that benchmarks human task trajectories for improved efficiency measurement.
- Evaluations using weighted efficiency scores reveal that CUAs, despite high accuracy, underperform human-like efficiency due to cumulative LLM call delays.
Benchmarking the Efficiency of Computer-Use Agents
The paper "OSWorld-Human: Benchmarking the Efficiency of Computer-Use Agents" (2506.16042) addresses the critical issue of latency in computer-use agents (CUAs). While existing research has primarily focused on improving the accuracy of these agents, this study highlights the often-overlooked aspect of temporal efficiency, demonstrating that state-of-the-art CUAs can take significantly longer than humans to complete even simple tasks. To address this, the paper presents a detailed analysis of latency bottlenecks in a representative CUA system and introduces OSWorld-Human, a manually annotated dataset of human task trajectories, to serve as a benchmark for evaluating and improving the efficiency of future CUAs.
Background and Motivation for Computer-Use Agents
Computer-use agents (CUAs) are AI systems designed to interact with computer systems autonomously, mirroring human interaction with operating systems, applications, and web browsers. These agents hold promise for automating digital workflows, improving accessibility, and providing a challenging benchmark for general AI capabilities. CUAs leverage LLMs and multimodal models (LMMs) to perceive their environment through screenshots, accessibility trees, and techniques like Set-of-Marks. They execute actions by simulating human interactions such as mouse movements, clicks, and keyboard inputs, using planning and reasoning loops powered by techniques like Chain-of-Thought or ReAct. Despite advancements in accuracy, latency remains a significant barrier to practical application, with CUAs often taking much longer than humans to complete the same tasks.
Analyzing Latency in Computer-Use Agents
The study begins by analyzing the performance of Agent S2, a leading open-source system, on a subset of tasks from the OSWorld benchmark. Agent S2's process involves retrieving relevant documents, planning steps, grounding actions (finding coordinates), executing actions, taking screenshots, and reflecting on progress.

Figure 1: Timeline view of an OS task successfully completed by Agent S2.
Figure 1 illustrates a timeline of Agent S2 completing a task, revealing that planning and reflection steps, which rely on LLM calls, consume the majority of time. A breakdown of time spent on each stage by application shows that planning and reflection account for 75% to 94% of the total task latency.
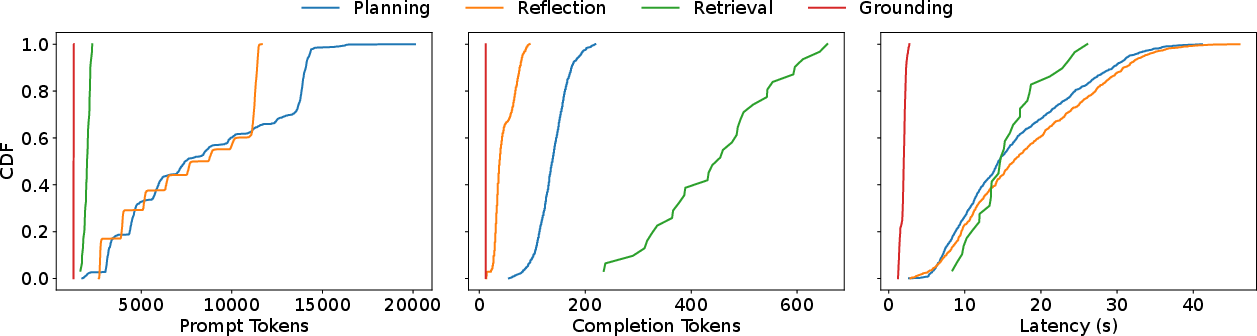
Figure 2: Comparison of prompt tokens, completion tokens, and latency for different types of calls to an LLM.
Further analysis of LLM calls at different steps in the agent's trajectory indicates that latency and prompt length increase in later steps due to the accumulation of historical data in the prompts. Comparing different types of LLM calls (planning, reflection, retrieval, grounding) reveals that planning, reflection, and retrieval calls take longer due to the use of large models.
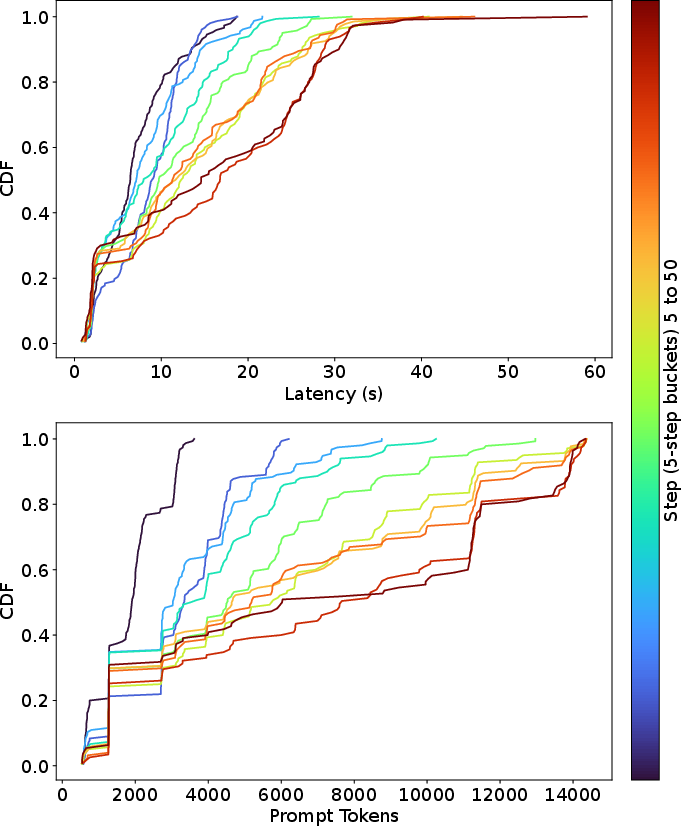
Figure 3: Probability distribution of latency and prompt tokens for a single step.
The probability distribution of latency and prompt tokens for a single step (Figure 3) further emphasizes this trend, showing that LLM calls become more demanding as the agent progresses through the task.
The Impact of Observation Types on Latency
The paper investigates how different observation types—screenshots, accessibility (A11y) trees, and Set-of-Marks (SoM)—affect task latency.
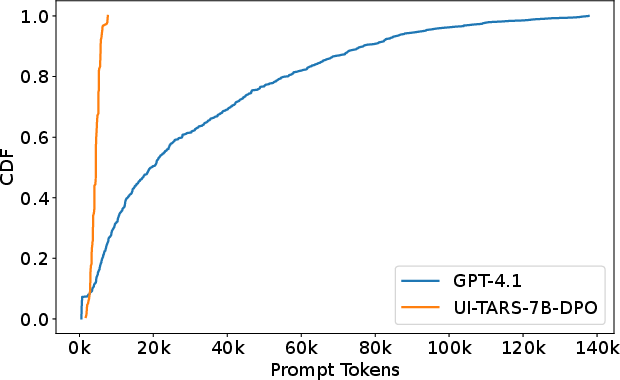
Figure 4: Prompt token distribution when including the a11y tree, separated by model.
The inclusion of A11y trees generally increases per-task latency due to the time required to generate the tree and the increased token count in prompts (Figure 4). This effect varies by application, with visually rich applications like LibreOffice experiencing a more significant impact.
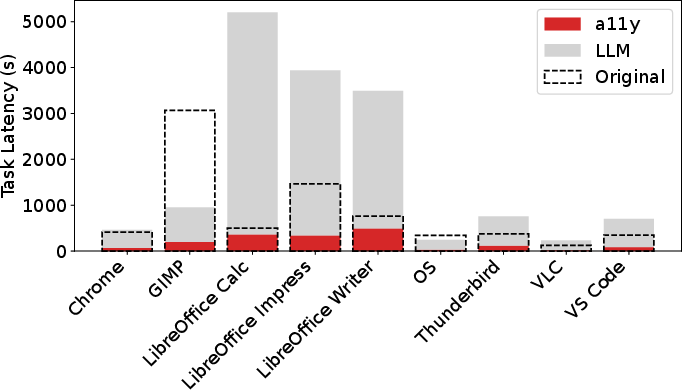
Figure 5: End-to-end task latency for each application. Dashed box represents screenshot-only latency while colored bars show the breakdown when including the a11y tree.
End-to-end task latency (Figure 5) increases substantially with A11y trees. A comparison of the number of steps taken for each task across observation types reveals that adding A11y trees can increase the number of steps for most applications.
Introducing OSWorld-Human: A Human-Generated Trajectory Dataset
To address the issue of inefficient task completion by CUAs, the authors introduce OSWorld-Human, a manually annotated version of OSWorld that provides minimal human-perceived steps for task completion. The construction of OSWorld-Human involved seeking, performing, and verifying ground-truth trajectories for all OSWorld tasks, using existing sources where available and manual identification for ambiguous cases. The dataset includes both single-action and grouped-action trajectories, where grouped actions represent sequences that can be performed consecutively without intervening observations or predictions. A weighted efficiency score (WES) is introduced to evaluate CUAs based on both success rate and the efficiency of their task completion.
Evaluation of CUAs Using OSWorld-Human
The paper evaluates several CUAs on OSWorld-Human, measuring their performance using the weighted efficiency score (WES). The results show that even the best-performing agents on the original OSWorld benchmark exhibit significantly reduced efficiency when evaluated against human-generated trajectories.
The best-performing baselines on OSWorld also performs the best on both single-action and grouped-action WES+. However, the absolute performance value is drastically reduced. Agent S2 w/ Gemini 2.5 holds the highest score on single-action WES+ (28.2\%) and grouped-action WES+ (17.4%), a 1.5and2.4 reduction respectively from the comparative OSWorld score of 41.4%. Interpreting WES− is also straightforward: how much of the allotted budget does an agent use. The top performing system on WES− is UI-TARS-72B-DPO, which scores −0.16.
Conclusion and Future Directions
The paper concludes by emphasizing the critical need to address latency issues in computer-use agents to enable their widespread adoption and practical utility. The findings highlight the dominance of LLM calls as a latency bottleneck and demonstrate the potential for improving efficiency by minimizing the number of steps required for task completion. The introduction of OSWorld-Human provides a valuable resource for future research aimed at developing more efficient and practical CUAs. The results suggest that future research should focus on optimizing LLM usage, improving action planning, and leveraging more efficient observation methods to reduce the temporal overhead of computer-use agents.

