- The paper demonstrates that replacing lengthy chain-of-thought with NoThinking maintains competitive accuracy while reducing token usage by up to 5.1x.
- It employs empirical analysis comparing Thinking and NoThinking across benchmarks in math problem-solving, coding, and other reasoning tasks.
- The study highlights practical benefits in latency and resource allocation when integrating NoThinking with parallel sampling methods.
"Reasoning Models Can Be Effective Without Thinking" Overview
The paper challenges the prevailing approach in contemporary reasoning models which incorporate explicit, lengthy "thinking" processes before generating solutions. The investigation focuses on whether these extensive thought sequences are necessary by introducing a streamlined method termed "NoThinking."
Motivation and Background
Recent advancements in LLMs, such as DeepSeek-R1 and OpenAI o1, have delivered significant improvements in reasoning by leveraging increased inference-time compute. These models typically execute prolonged chains of thought before arriving at the solution, increasing token usage and latency. However, prior explorations have only made strides in reducing token usage through methods like RL or fine-tuning on various CoT traces, without removing the explicit thinking process altogether.
Key Concepts
The core proposition is to bypass the explicit thinking steps entirely. By generating the final solution directly after a prefabricated dummy "thinking box," the paper posits that the elimination of verbose thinking processes could be surprisingly efficient, notably in terms of accuracy-cost tradeoffs.
- Thinking vs. NoThinking Paradigm:
- Thinking: Involves traditional models that rely on generating a structured reasoning trace followed by the solution.
- NoThinking: Uses simple prompts to prefill the reasoning template, skipping over the expansive chain of thoughts.
Experimental Framework
The empirical analysis compared Thinking and NoThinking using state-of-the-art reasoning models like DeepSeek-R1-Distill-Qwen across various benchmarks (math problem-solving, coding, etc.).
Metrics Used:
- Pass@k: Measures the likelihood of obtaining at least one correct answer in k attempts.

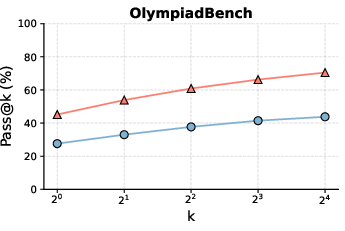
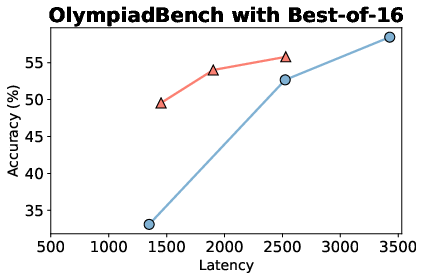
Figure 1: Performance comparison of Thinking vs. NoThinking showcasing effectiveness across several datasets.
Results and Analysis
- Token Efficiency: NoThinking demonstrates substantial token savings (2.0â5.1x fewer tokens), effectively matching or exceeding Thinking for pass@k metrics.
- Accuracy Improvements: In constrained settings, NoThinking surpasses Thinking particularly when k increases, indicating the production of more diverse outputs.
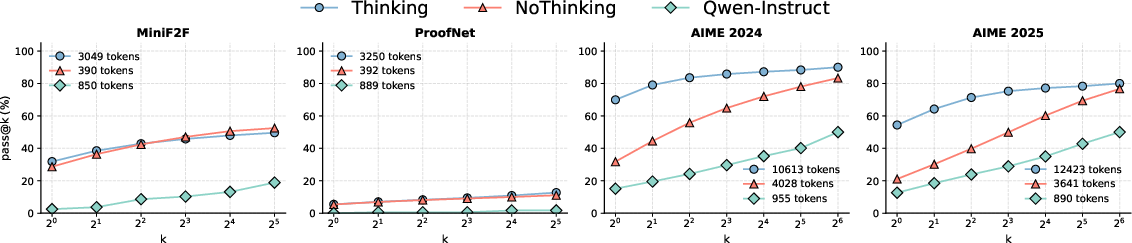
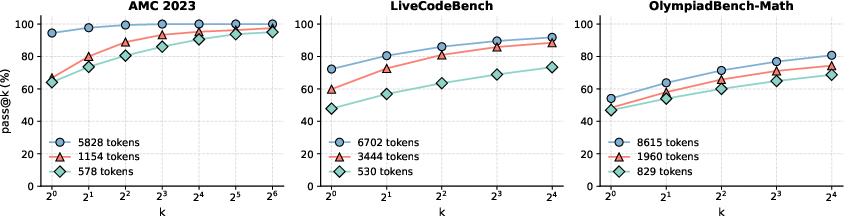
Figure 2: Pass@k results, indicating NoThinking's increased efficiency over Thinking.
Parallel Scaling and Latency
By integrating NoThinking with parallel sampling methods, the model exploits its efficient pass@k performance. The parallel approach not only reduces latency compared to conventional Thinking but also enhances resource utilization, providing better accuracy-latency tradeoffs.
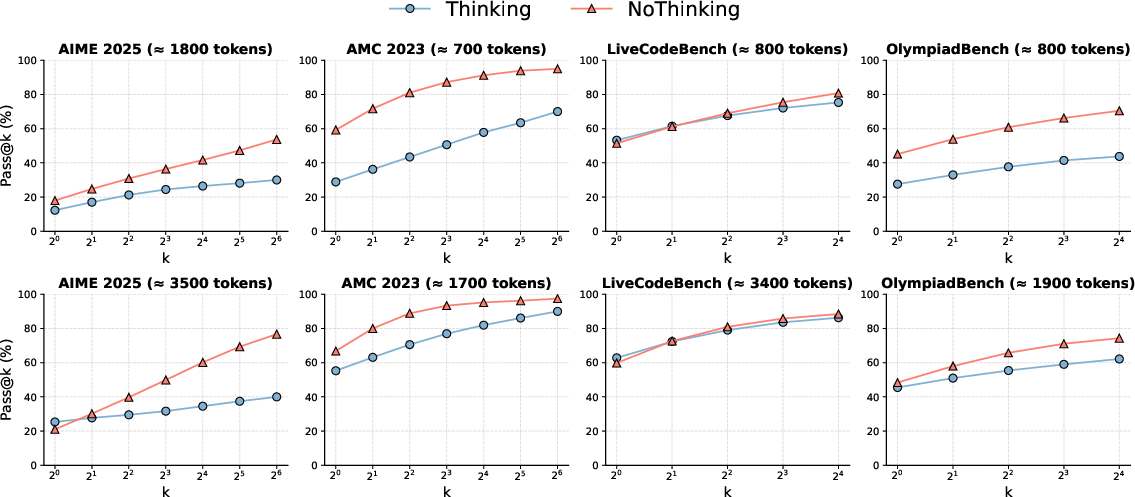
Figure 3: Comparison of latency and accuracy between parallel and sequential inferencing methods.
Practical Implications and Future Directions
The paper suggests that the necessity of extensive thinking processes in reasoning could be reconsidered. It offers a baseline for establishing robust reasoning capabilities within LLMs under low-resource constraints. Future explorations could include applying similar strategies to closed-source models and other decision-making platforms.
Conclusion
The investigation concludes that explicit, long-form thinking processes in LLMs are not inherently essential for achieving high performance on reasoning tasks. Utilizing a lean NoThinking approach provides competitive accuracy-cost benefits, reshaping the perspective on LLM efficiency in real-world applications.

