- The paper introduces TreeRL, integrating on-policy tree search (EPTree) to enhance LLM reasoning during RL training.
- It employs entropy-guided branching and process supervision to efficiently explore the reasoning space and assign rewards to intermediate steps.
- Experiments on math and code reasoning benchmarks show that TreeRL outperforms conventional multi-chain sampling and MCTS-based approaches.
TreeRL: Enhancing LLM Reasoning with On-Policy Tree Search
This paper introduces TreeRL, a novel reinforcement learning framework designed to improve the reasoning capabilities of LLMs by integrating on-policy tree search. Addressing the limitations of traditional independent chain sampling strategies, TreeRL leverages a new tree search method called EPTree to enhance exploration of the reasoning space and provide dense, on-policy process rewards during RL training, eliminating the need for a separate reward model. Experiments on math and code reasoning benchmarks demonstrate that TreeRL achieves superior performance compared to conventional ChainRL approaches.
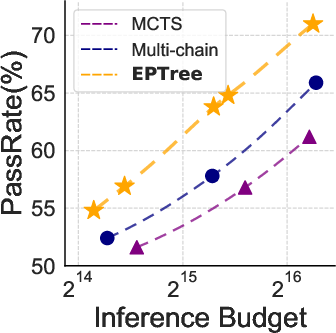
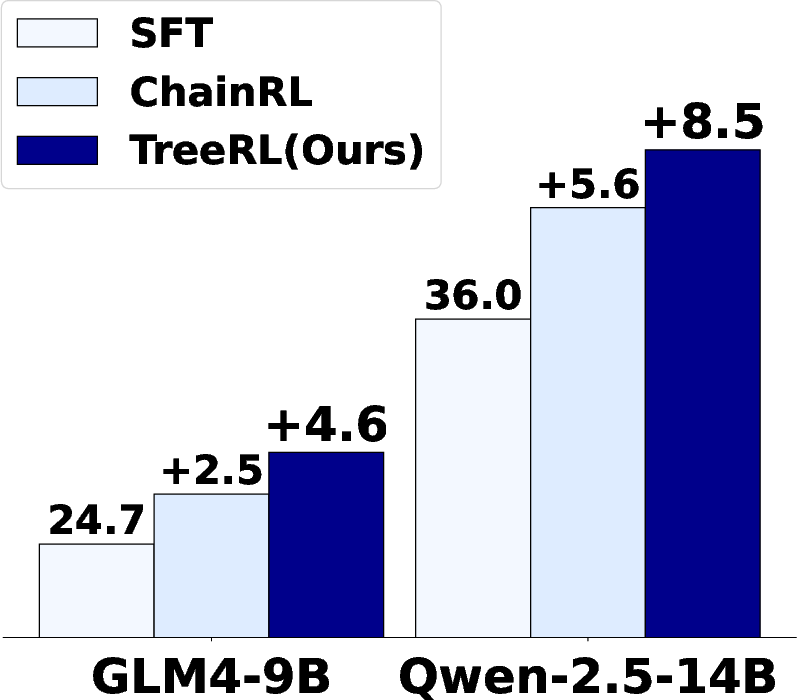
Figure 1: Left: Performance comparison of sampling strategies. EPTree consistently outperforms i.i.d multi-chain sampling and MCTS under different inference budgets. Right: TreeRL powered with EPTree demonstrates better performance than ChainRL with i.i.d multi-chain sampling.
Background and Motivation
LLMs have shown remarkable capabilities in complex reasoning tasks. RL has emerged as a promising method to improve LLM reasoning by optimizing the policy through reward feedback. However, current RL methods predominantly rely on independently sampling multiple trajectories and obtaining reward signals based on the final answers. Tree search, which has demonstrated success in domains like AlphaZero, remains underexplored in RL for LLM reasoning. Existing efforts have focused on using tree search to enhance inference-time performance or generate data for offline training. The paper argues that these offline approaches suffer from distribution shift and reward hacking, limiting the potential of on-policy RL training with tree search.
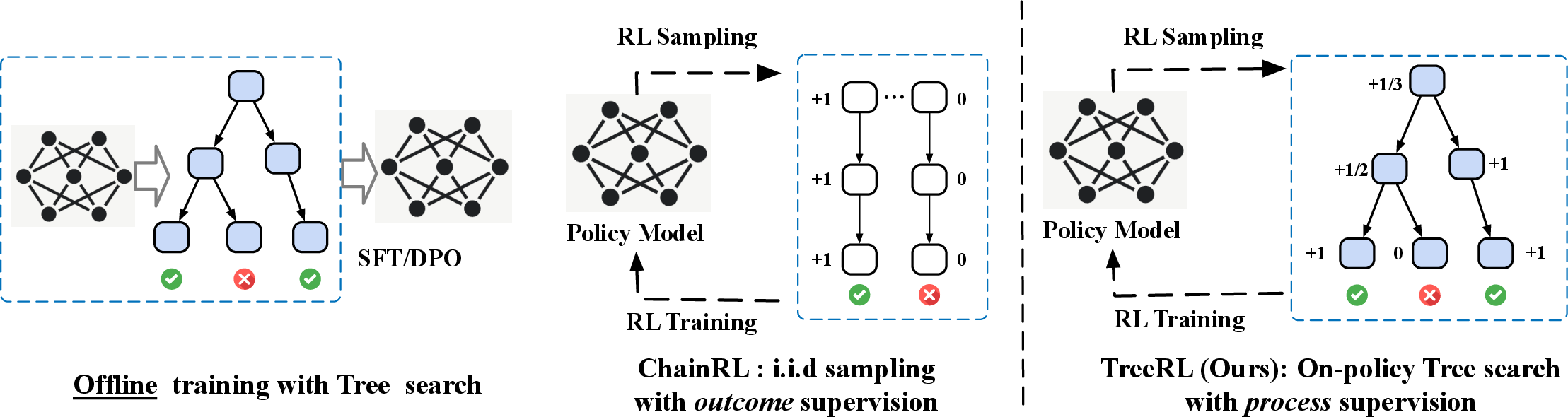
Figure 2: Illustration of offline training with tree search (Left), traditional ChainRL with online i.i.d multi-response sampling (Middle), and TreeRL with tree search (Right).
TreeRL Framework
The TreeRL framework addresses the limitations of existing approaches by incorporating on-policy tree search directly into the RL training loop. The framework consists of two key components:
- EPTree (Entropy-Guided Tree Search): An efficient tree search strategy that promotes exploration by branching from high-uncertainty intermediate steps rather than using random branching or step-by-step generation.
- Reinforcement Learning with Process Supervision: Integration of EPTree with RL, utilizing process supervision signals derived from the tree search to further optimize the policy.
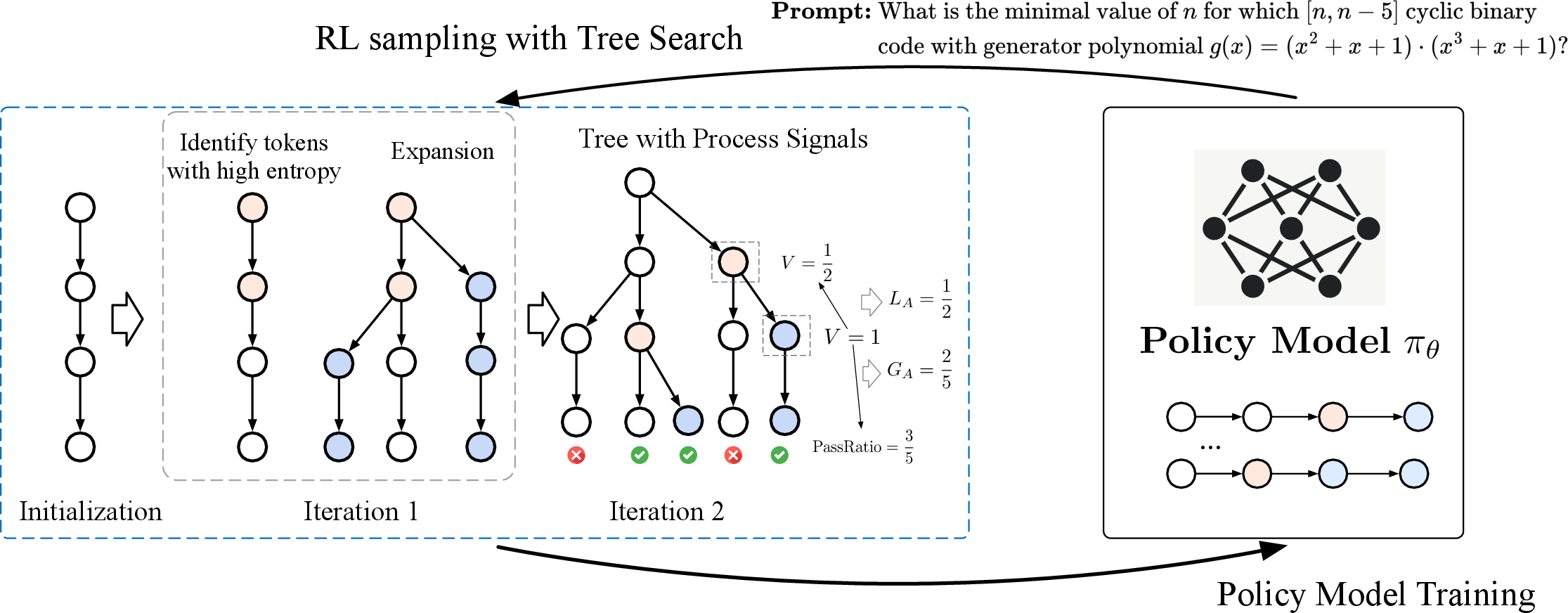
Figure 3: Illustration of TreeRL. In each iteration, TreeRL first performs a tree search using EPTree, progressively expanding branches from the top-N most uncertain tokens. The resulting tree, along with the process supervision signals derived from each step, is then fed into reinforcement learning to update the policy model.
EPTree: Entropy-Guided Tree Search
EPTree is designed to enhance search efficiency under a constrained generation token budget. Unlike traditional MCTS, which breaks answers into smaller steps, EPTree forks branches from the most uncertain intermediate tokens based on entropy. The algorithm operates as follows:
- Initialization: Generate M chains by sampling M responses from the policy model πθ for a given prompt.
- Forking Token Selection: Select the top-N tokens with the highest entropy values across the tree. Entropy is calculated as H(t)=−logπθ(t∣,<t).
- Expansion: Generate T different candidate responses from each forking point t.
- Iteration: Repeat the forking and expansion process for L iterations.
The resulting tree structure is denoted as an (M,N,L,T)-tree, where M is the number of parallel trees, N is the number of forked points per iteration, L is the number of iterations, and T is the branching factor. This approach allows EPTree to generate a larger number of diverse responses under the same inference cost compared to independent multi-chain sampling.
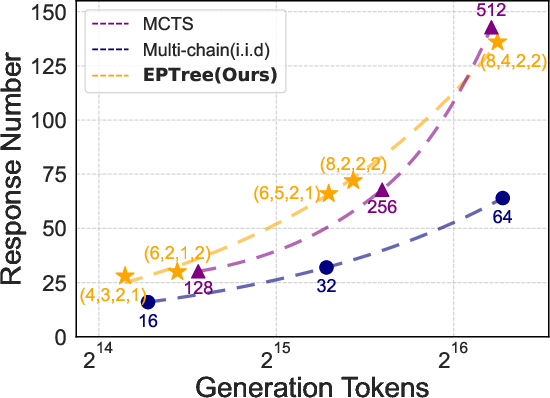
Figure 4: Generation diversity comparison of EPTree, MCTS, and i.i.d. multi-chain sampling. Both EPTree and MCTS produce approximately 2× different responses compared to i.i.d. multi-chain sampling.
Reinforcement Learning with Process Supervision
TreeRL leverages the tree structure generated by EPTree to provide fine-grained process supervision for intermediate steps during RL training. Each step in the tree is assigned a credit based on advantage, reflecting its contribution to reaching a correct solution. The process signal for a given reasoning step is calculated as a weighted sum of two components:
- Global Advantage: Reflects the step's potential over the overall correctness rate for the question, calculated as GA(sn)=V(sn)−V(root), where V(sn) is the value of step sn.
- Local Advantage: Quantifies the improvement the step provides compared to its parent step in the tree, calculated as LA(sn)=V(sn)−V(p(sn)).
The final reward for each step is computed as R(sn)=GA(sn)+LA(sn). The sequences extracted from the trees are used for RL training, with the reward for non-leaf steps downweighted to prevent overfitting.
Experimental Results
The paper evaluates TreeRL on challenging college-level and competition-level math and code reasoning benchmarks using Qwen and GLM models. The results demonstrate that TreeRL achieves superior performance compared to traditional independent multi-chain sampling.
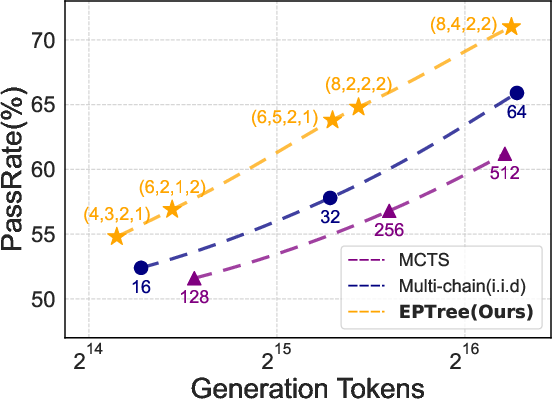
Figure 5: Search performance of EPTree, MCTS, and multi-chain sampling on Omni-MATH-500 using Qwen-2.5-14B-SFT. EPTree consistently outperforms all baselines under the different inference costs.
Key findings from the experiments include:
- EPTree consistently outperforms i.i.d multi-chain sampling and MCTS under different inference budgets.
- TreeRL, powered by EPTree, demonstrates better performance than ChainRL with i.i.d multi-chain sampling.
- Ablation studies confirm the effectiveness of entropy-based forking and the benefits of process supervision.
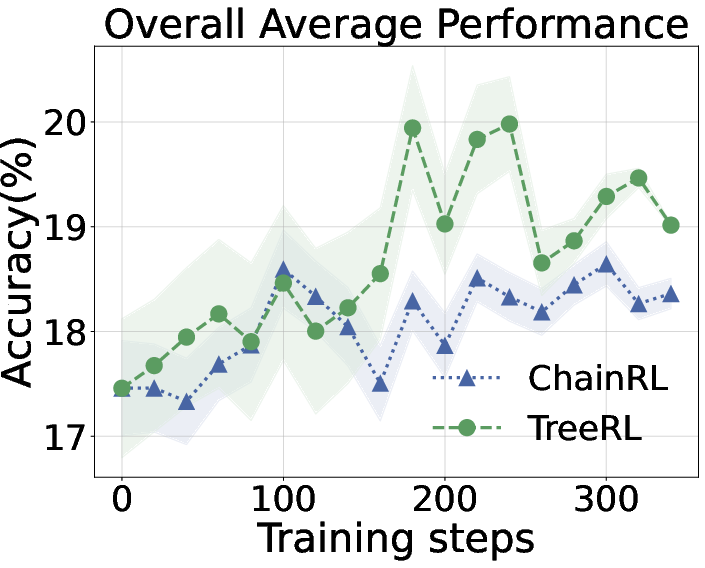
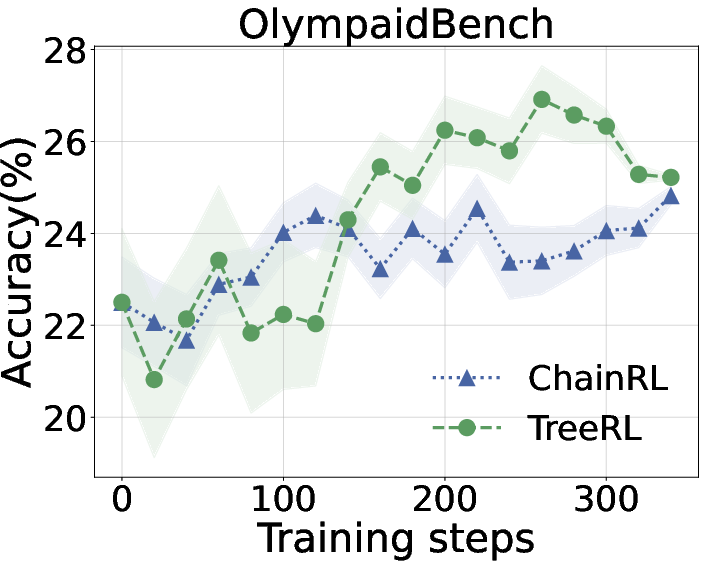
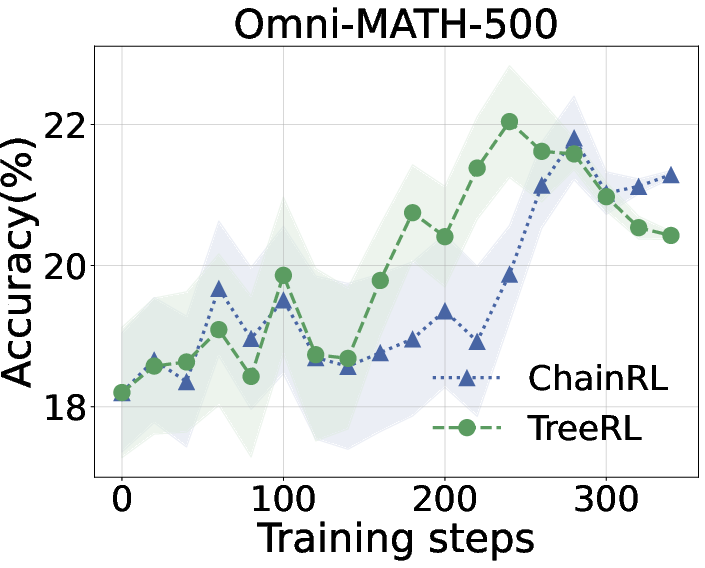
Figure 6: Performance comparison between TreeRL and ChainRL during training. We report the average performance across all six datasets (Left), OlympiadBench (Middle), and Omni-MATH-500 (Right). The results for the other benchmarks can be found in the \Cref{sec:appendix:other_benchmark}.
Implications and Future Directions
TreeRL represents a significant advancement in RL for LLM reasoning. The integration of on-policy tree search with process supervision offers a promising approach to improve the exploration of the reasoning space and enhance the training of LLMs. The results suggest that TreeRL could lead to more robust and reliable reasoning capabilities in LLMs.
Future research directions include:
- Exploring more sophisticated methods for assigning weights to different steps in the tree.
- Developing more meaningful process signals from the tree structure.
- Implementing step-level reward normalization.
- Optimizing LLM inference engines for tree search.
Conclusion
This work introduces TreeRL, a reinforcement learning approach that combines tree search with process supervision to enhance LLM reasoning. EPTree improves response diversity and performance over traditional methods like MCTS and i.i.d multi-chain sampling. Experiments on math reasoning tasks show that TreeRL outperforms existing techniques, highlighting the potential of RL with tree search to advance LLMs in complex reasoning tasks.

