- The paper introduces the IFIM framework that unifies instruction-following and fill-in-the-middle code completion, achieving Pass@1 improvements up to 95.8%.
- It employs a two-stage process involving instruction dataset synthesis and fine-tuning with (prefix, instruction, suffix) triplets to accurately capture developer intentions.
- The method is backward-compatible, scalable across programming languages, and seamlessly integrates into developer workflows via IDE plugins.
Bridging Developer Instructions and Code Completion Through Instruction-Aware Fill-in-the-Middle Paradigm
Introduction
The paper introduces Instruction-aware Fill-in-the-Middle (IFIM), a novel instruction-tuning methodology for code LLMs that directly addresses the longstanding conflict between instruction-following and fill-in-the-middle (FIM) code completion capabilities. Existing code LLMs, typically pretrained with FIM objectives, excel at context-aware infilling but are suboptimal at leveraging developer-supplied natural language instructions. Conversely, instruction-tuned models, optimized for assistant-style code generation, often exhibit degraded FIM performance, manifesting in repeated suffixes or irrelevant completions. IFIM extends the FIM paradigm by explicitly incorporating an instruction section into the input, enabling models to learn from (prefix, instruction, suffix) triplets and thereby unify instruction-following with robust infilling.
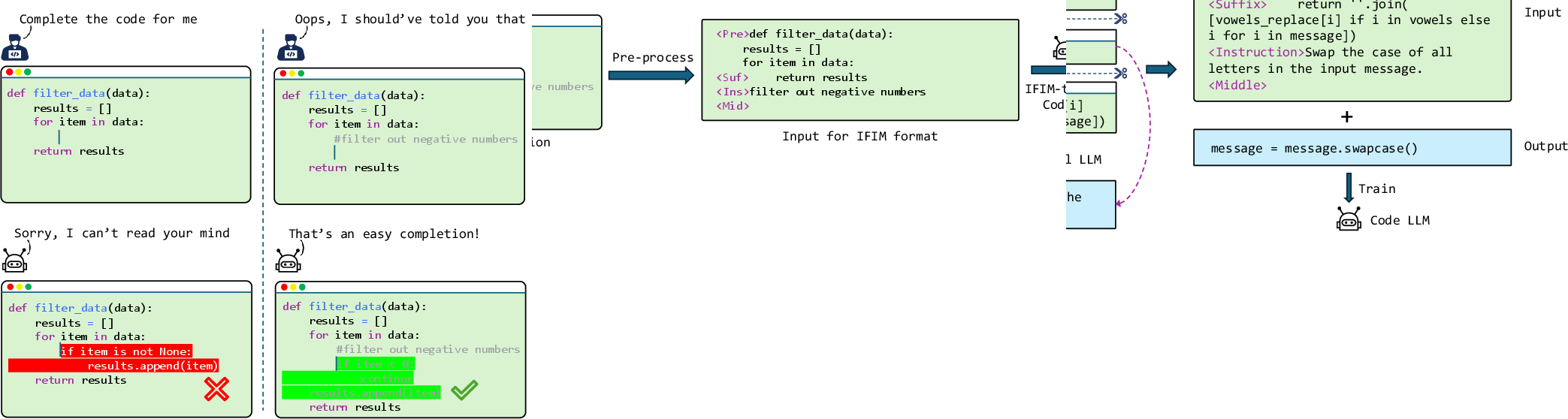
Figure 1: Guiding an LLM for code completion using instructive comments. Left: An ambiguous request leads to an unhelpful completion. Right: A specific comment clarifies the developer's intent, resulting in the desired code.
IFIM Framework and Implementation
The IFIM framework consists of two primary stages: instruction dataset synthesis and instruction-aware fine-tuning. The dataset is constructed by decomposing code samples into prefix, middle, and suffix segments, then prompting a high-capacity LLM (GPT-4o) to generate concise, intent-focused instructions for the middle segment. This yields a large-scale, multi-language dataset of (prefix, middle, suffix, instruction) tuples.
During fine-tuning, the model is trained to predict the middle segment conditioned on the prefix, suffix, and instruction, with the input sequence formatted according to empirically optimized IFIM modes (e.g., PSIM, PIMS). The instruction is delimited by a repurposed rare token to avoid vocabulary expansion and catastrophic forgetting. Ablation studies demonstrate that placing the instruction immediately before the middle segment maximizes instruction-following performance while preserving infilling capabilities.

Figure 2: The overall framework of IFIM, which consists of synthesizing an instruction dataset and performing an instruction tuning phase.
Usage and Integration in Developer Workflows
IFIM-trained models enable seamless integration of explicit developer instructions into code completion workflows. Instructions are embedded as specially marked inline comments (e.g., #!filter out negative numbers), which are parsed and formatted into IFIM input sequences by IDE plugins or client-side tools. This approach allows developers to guide code completion without context-switching to chat-based LLMs, maintaining workflow continuity and leveraging both implicit code context and explicit directives.

Figure 3: A usage example of IFIM-trained code LLMs, where the code context is first processed into IFIM format and then infilled by an IFIM-trained code LLM.
Experimental Results
Comprehensive experiments were conducted on Deepseek-Coder and Qwen2.5-Coder using benchmarks derived from HumanEval-infilling and RepoMasterEval, with and without instructions. IFIM variants consistently outperform base models in instruction-following, with Pass@1 scores on IHumanEval increasing from 84.6% to 93.6% (Deepseek-Coder) and 91.0% to 95.8% (Qwen2.5-Coder). On IRME, Deepseek-Coder's score nearly doubles from 10.9% to 21.1%. Notably, IFIM does not compromise FIM performance in the absence of instructions; in several cases, infilling accuracy is improved.
Ablation studies reveal that the I-before-M IFIM mode yields the highest gains, outperforming other modes by 4.1 percentage points on IHumanEval. Increasing the ratio of IFIM-formatted data in training further boosts instruction-following, with a 100% ratio being optimal. Critically, simply appending instructions as inline comments (CFIM) degrades performance, underscoring the necessity of structural separation in IFIM.
Theoretical and Practical Implications
IFIM resolves the trade-off between instruction-following and infilling by structurally unifying both capabilities in code LLMs. The explicit instruction component enables models to interpret developer intent with high fidelity, while the preservation of FIM structure ensures robust context-aware completion. This paradigm is backward-compatible with existing FIM-pretrained models and can be integrated into production code completion systems with minimal architectural changes.
The methodology is language-agnostic and scalable, with demonstrated efficacy on multi-billion parameter models. The use of synthetic instructions, while effective, opens avenues for leveraging "wild" data sources such as real-world comments, forum discussions, and completion logs, contingent on robust preprocessing.
Future Directions
Key future research directions include expanding the instruction dataset to cover more programming languages, exploring alternative instruction sources for greater diversity and realism, and scaling IFIM to larger model architectures. Further investigation into the generalization benefits observed in out-of-distribution tasks is warranted, as is the development of advanced filtering techniques for noisy instruction data.
Conclusion
IFIM represents a principled solution to the dual challenge of instruction-following and fill-in-the-middle code completion in LLMs. By structurally integrating explicit instructions into the FIM paradigm, IFIM-trained models achieve substantial improvements in both instruction adherence and infilling accuracy, validated across multiple benchmarks and model families. The approach is practical, extensible, and directly applicable to real-world developer workflows, laying the groundwork for more intelligent and responsive code completion systems.

