- The paper introduces DeepSeek-Coder, a suite of open-source LLMs for code intelligence, trained on 2 trillion tokens across 87 languages.
- It employs innovations like Rotary Position Embedding, Grouped-Query-Attention, and FlashAttention v2, alongside a dual objective including Fill-In-the-Middle training.
- Empirical evaluations demonstrate superior performance on benchmarks such as HumanEval, MBPP, and CrossCodeEval, exceeding peers like CodeLlama-34B.
DeepSeek-Coder: Advancing Open-Source Code Intelligence with LLMs
Model Series and Architectural Innovations
DeepSeek-Coder introduces a suite of open-source LLMs for code intelligence, with parameter sizes ranging from 1.3B to 33B. These models are trained from scratch on a project-level, high-quality code corpus comprising 2 trillion tokens across 87 programming languages and are offered as both base and instruction-tuned variants. Architecturally, DeepSeek-Coder leverages a decoder-only Transformer with innovations such as Rotary Position Embedding (RoPE) for extended context, Grouped-Query-Attention (GQA) in large models for efficient attention computation, and FlashAttention v2 to further accelerate training and inference.
A defining aspect of DeepSeek-Coder's training is its dual objective: traditional next token prediction and the Fill-In-the-Middle (FIM) infilling paradigm. The FIM training objective substantially enhances code completion capabilities by preparing the models for infill tasks that are highly relevant for modern developer workflows. Experiments including ablation studies on FIM rates show that a 50% PSM (Prefix-Suffix-Middle) composition achieves the best trade-off between infilling and sequential code completion. These results are clearly evidenced by benchmark performance curves during pretraining.
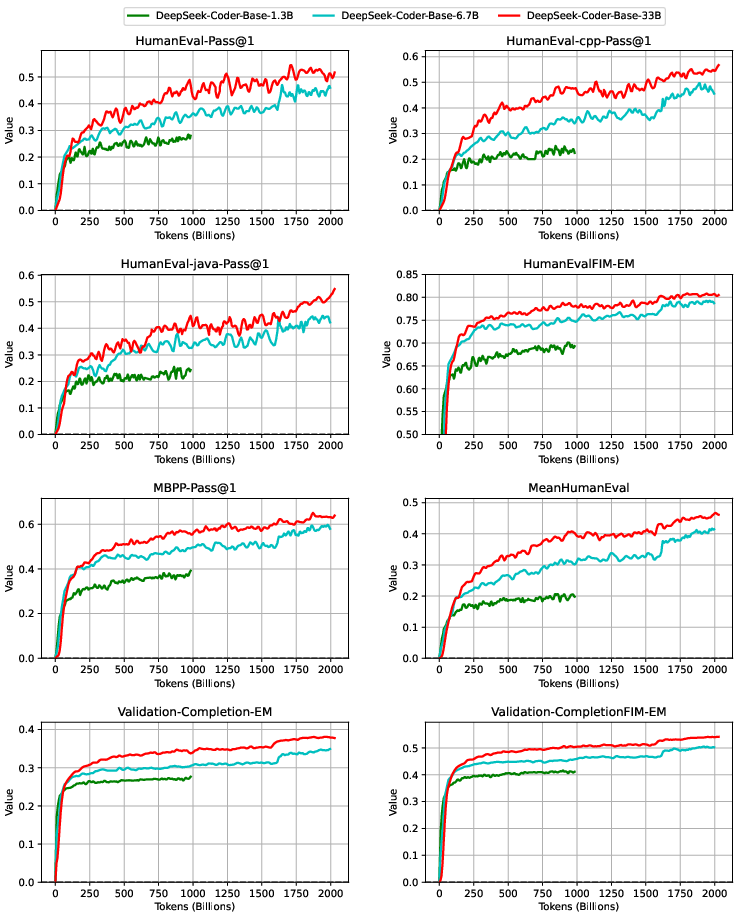
Figure 2: Benchmark curves for DeepSeek-Coder-Base during training, capturing performance improvements across code tasks.
Project-Level Data Engineering and Processing
The dataset curation pipeline for DeepSeek-Coder is meticulous, distinguishing itself by organizing training data at the repository (project) level rather than merely file level. The process involves large-scale code crawling, aggressive rule-based filtering, dependency parsing, repo-level deduplication, and multi-stage quality screening. Notably, dependency parsing employs a topological sort to maximize intra-repository context coherence, and deduplication is performed at the repository granularity to preserve structural and contextual integrity.

Figure 3: DeepSeek-Coder’s dataset creation pipeline, highlighting multi-stage filtering, dependency parsing, and repo-level deduplication.
The training mix is dominated by high-quality code (87%), with supplementary code-related English (10%) and Chinese (3%) corpora, further decontaminated by n-gram filtering against evaluation benchmarks to preclude test data leakage.
Evaluation: Code Generation, Completion, and Reasoning
DeepSeek-Coder’s empirical evaluation spans a spectrum of benchmarks, encompassing code generation (HumanEval, MBPP, DS-1000, LeetCode Contest), fill-in-the-middle completion tasks, cross-file code completion (CrossCodeEval), and program-aided math reasoning (GSM8K, MATH, SVAMP, etc.).
Code Generation
Across HumanEval and MBPP, DeepSeek-Coder-Base 33B achieves 56.1% and 66.0%, respectively—substantially outperforming the largest open-source peer, CodeLlama-34B, by 9–11 percentage points. DeepSeek-Coder-Base 6.7B also exhibits notably strong results, matching or exceeding models with far greater parameter counts.
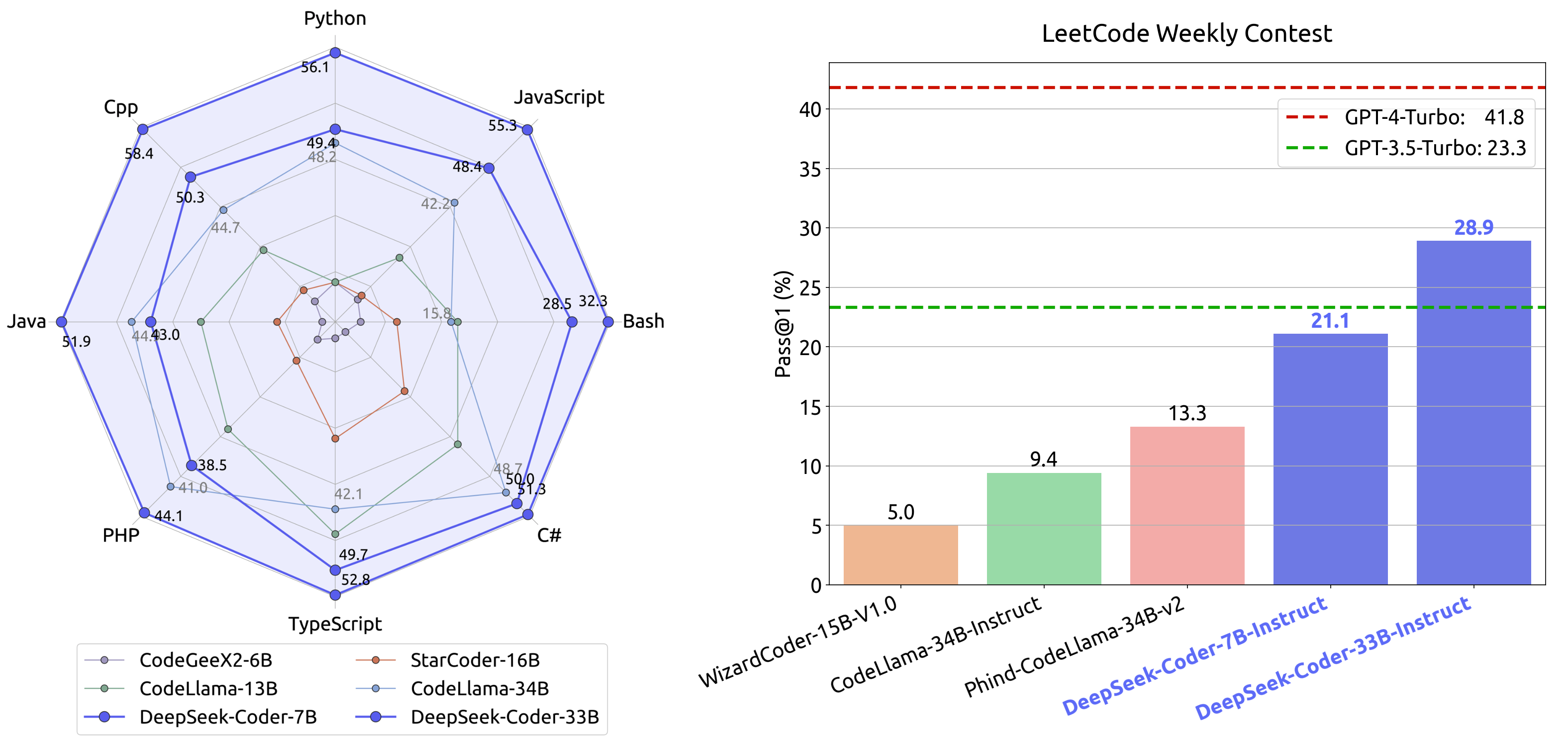
Figure 4: Comparative performance of DeepSeek-Coder and contemporary code LLMs across popular code generation benchmarks.
Fill-In-the-Middle (FIM) and Code Completion
In fill-in-the-middle tasks, DeepSeek-Coder demonstrates robust capabilities due to its FIM-mixed pretraining. Performance increases nearly linearly with scale, with 33B models achieving up to 81.2% mean accuracy on single-line infilling—exceeding previous open-source models of comparable or larger size.
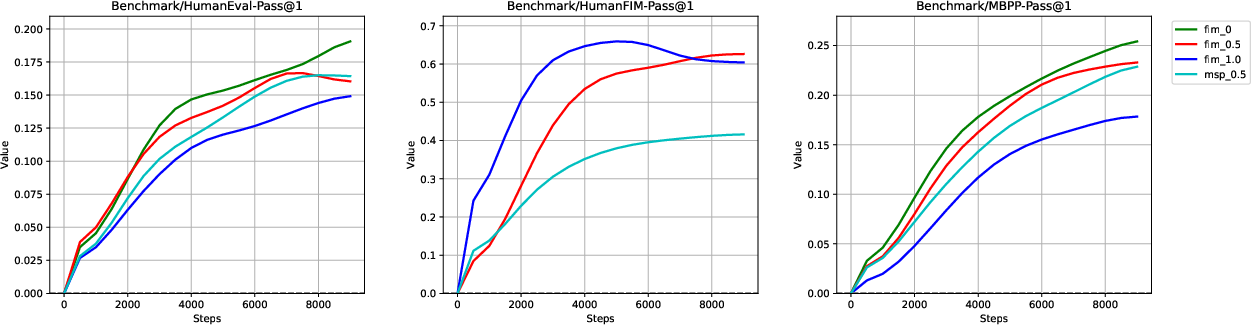
Figure 5: Ablation results for FIM objectives, showing the trade-off and optimal balance for code completion and infilling capacity.
Instruction Tuning and Multi-Turn Dialogue
Instruction tuning (DeepSeek-Coder-Instruct) delivers substantial gains in multi-turn code generation and understanding. The 33B instruct variant surpasses GPT-3.5-Turbo on HumanEval and LeetCode Contest benchmarks and approaches GPT-4-level performance in specific tasks.

Figure 6: DeepSeek-Coder-Instruct 33B responding in a multi-turn programming dialogue with consistent, high-fidelity outputs.
Complex Code Understanding
DeepSeek-Coder’s large context window (16K tokens) and project-level pretraining strategy provide meaningful advantages in cross-file code completion. Evaluated on the CrossCodeEval benchmark, DeepSeek-Coder outperforms all tested open-source baselines, clearly evidencing benefits from repository-level modeling and retrieval augmentation.
Math Reasoning and Generalization
Beyond coding, the models exhibit strong mathematical reasoning, especially after continued pretraining from a general LLM backbone (DeepSeek-LLM). DeepSeek-Coder-v1.5 achieves superior results in math and general language understanding tasks without sacrificing code generation performance—underscoring the importance of foundation model synergy for broad code intelligence.
Practical and Theoretical Implications
Practically, DeepSeek-Coder sets a new state-of-the-art for open-source LLMs in code-centric tasks, delivering performance competitive with (and in several domains, superior to) closed-source alternatives such as GPT-3.5 Turbo. Its refined data curation, effective FIM training, and long-context modeling collectively lead to models deployable not only for code completion but also for multi-turn programming assistants, cross-file reasoning, and program-based mathematical problem-solving.
Theoretically, the results articulate a robust case for project-level data organization, mixed training objectives, and context window extension as levers for scalable code intelligence. The demonstrated enhancements from initializing code models on generalist LLM backbones (DeepSeek-Coder-v1.5) suggest an inevitable convergence of code pretraining with state-of-the-art natural language and reasoning models.
Exemplary Scenario Demonstrations

Figure 7: DeepSeek-Coder-Instruct builds a Python student database and generates analytic code in a dialogue.

Figure 1: DeepSeek-Coder-Instruct solves an out-of-distribution LeetCode programming problem with fully functional code and explanation.
Conclusion
DeepSeek-Coder advances the state of open-source code LLMs by integrating large-scale, high-quality project-level training, sophisticated FIM and instructional objectives, and a scalable architecture with long-context support. The models exhibit strong empirical performance across standard code and reasoning benchmarks, demonstrating both practical usability and generalization beyond contemporary open models. DeepSeek-Coder’s methodology and results emphasize the future direction of code intelligence: project-level, context-rich, linguistically broad, and instruction-understanding LLMs that combine coding and reasoning for robust developer assistance and automated program synthesis.