- The paper introduces a novel framework that improves interpretability by focusing on intra-modal token interactions.
- It employs Multi-Scale Explanation Aggregation (MSEA) to integrate spatial contexts in visual data for more coherent explanations.
- Activation Ranking Correlation (ARC) reduces spurious textual activations, achieving improvements up to 14.52% across benchmarks.
Explaining Multimodal LLMs via Intra-Modal Token Interactions
The study presented in this paper addresses a critical aspect of Multimodal LLMs (MLLMs): the interpretability of their internal decision-making processes. These models, while excelling in various vision-language tasks, remain opaque in terms of understanding their reasoning mechanisms. This work proposes novel techniques to enhance interpretability by focusing on intra-modal interactions, which have been largely overlooked by existing methods that concentrate on cross-modal attributions.
Introduction
MLLMs have achieved significant success across diverse tasks such as visual question answering and image captioning. However, the models' internal reasoning remains poorly understood, leading to limitations in diagnosing errors, improving model design, and ensuring safety and accountability. The existing focus on cross-modal attribution fails to adequately explain model predictions due to insufficient modeling of intra-modal dependencies. Particularly, visual modality explanations often miss spatial context, while textual modality explanations are susceptible to spurious activations caused by reliance on preceding tokens.
Proposed Framework
The paper introduces a framework designed to strengthen intra-modal interactions for more faithful and coherent interpretability in MLLMs. The two key components are:
Multi-Scale Explanation Aggregation (MSEA)
MSEA enhances visual interpretability by aggregating attributions over inputs at multiple scales. This approach dynamically adjusts receptive fields to produce holistic and spatially coherent visual explanations, addressing the limitation of fragmented representations due to isolated image patches.
Activation Ranking Correlation (ARC)
For the textual modality, ARC mitigates the influence of irrelevant preceding tokens. It measures relevance by aligning top-k prediction rankings, suppressing spurious activations from irrelevant contexts while preserving semantically coherent interactions. This improves the fidelity of attributions by focusing on relevant token interactions.
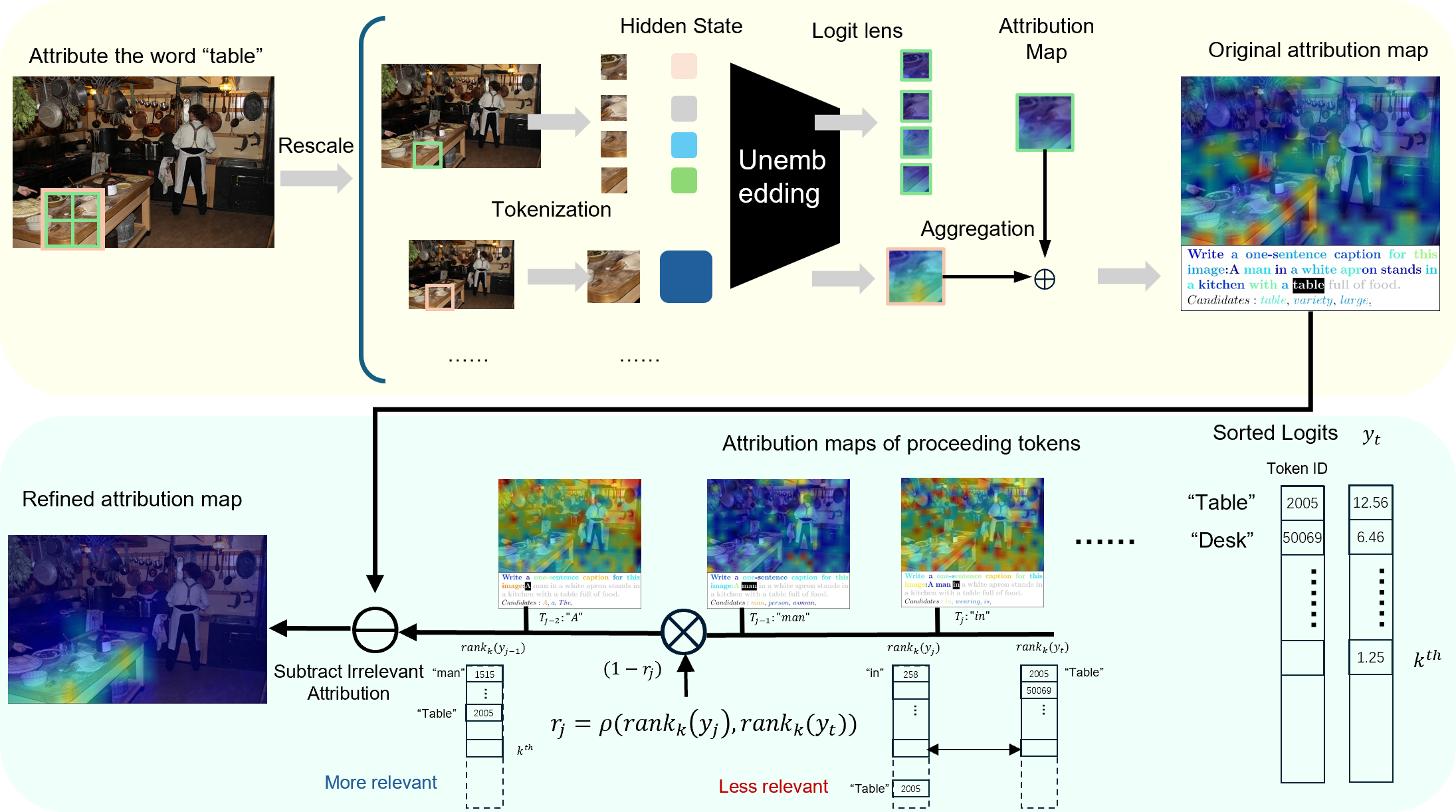
Figure 1: Overview of our proposed framework.
Experiments and Results
The proposed methods were evaluated on various MLLMs including LLaVA-1.5, Qwen2-VL, and InternVL2.5, across datasets such as COCO Caption, OpenPSG, and GranDf. The framework consistently outperformed existing interpretability methods, as demonstrated by improvements in metrics like Obj-IoU, Func-IoU, and F1-IoU:
- Overall, improvements ranged from 3.69% to 14.52% across different models and datasets.
- Significant reductions in noise and false positives were observed, particularly in Func-IoU, indicating the framework's robustness in suppressing irrelevant activations.
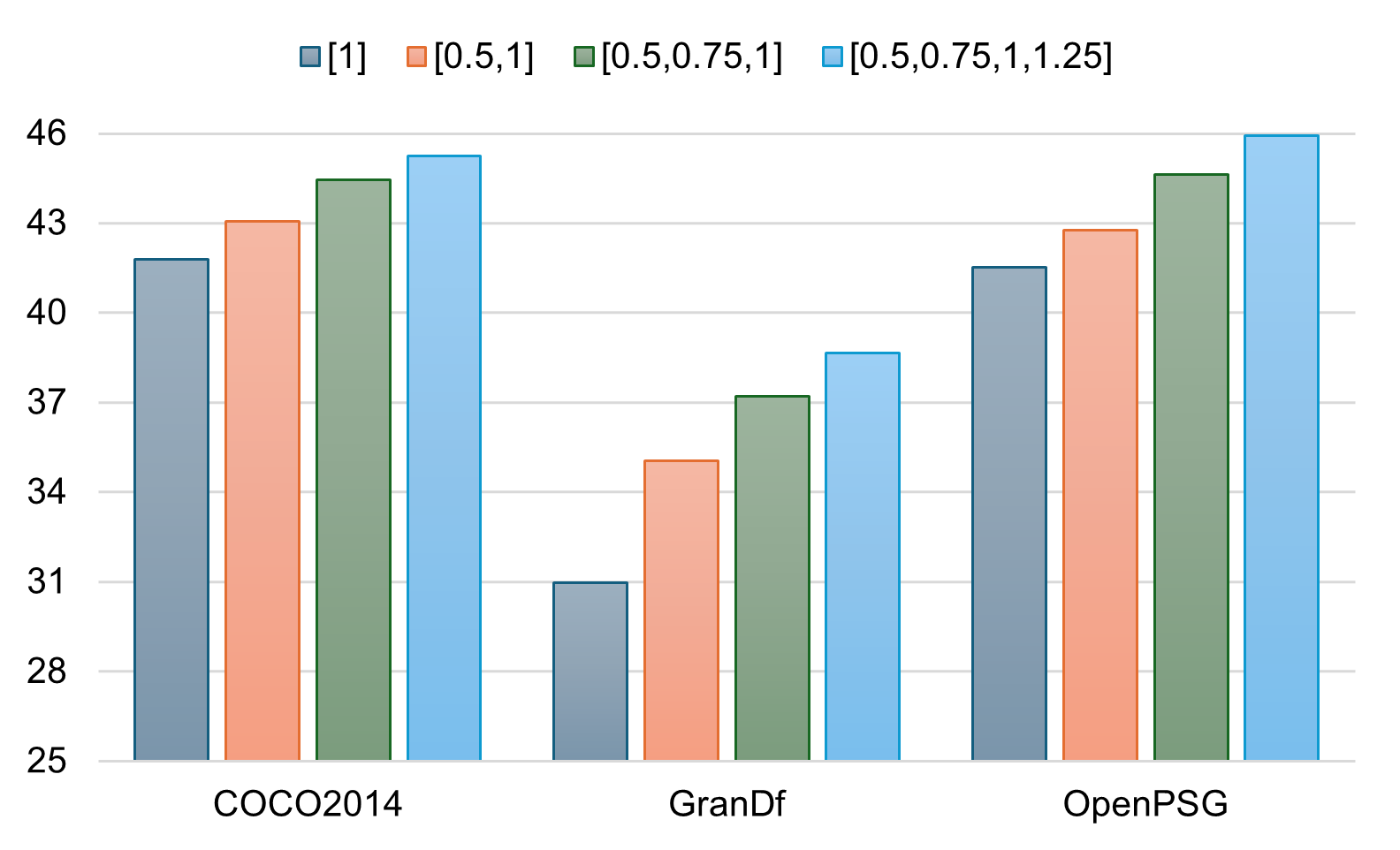
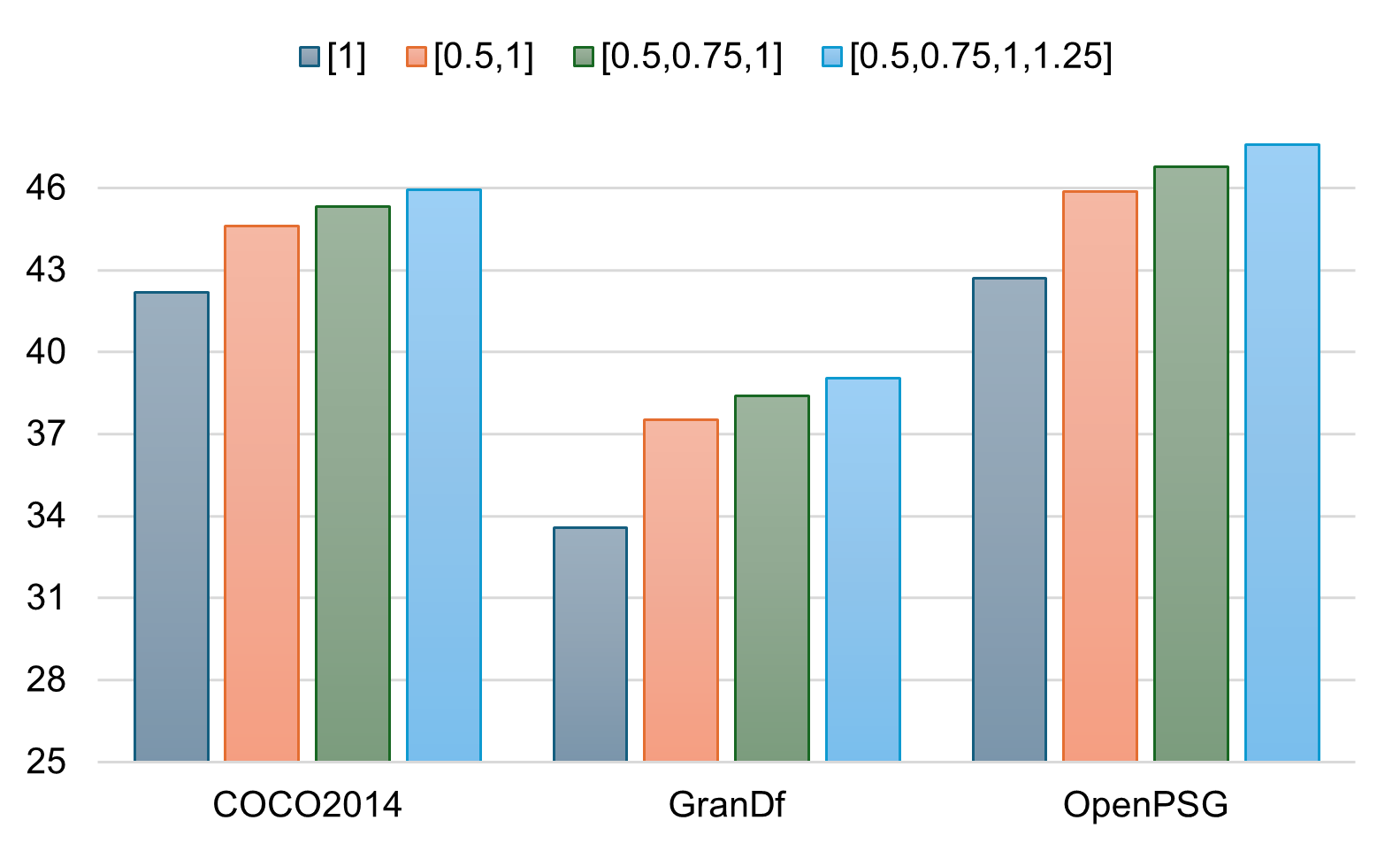
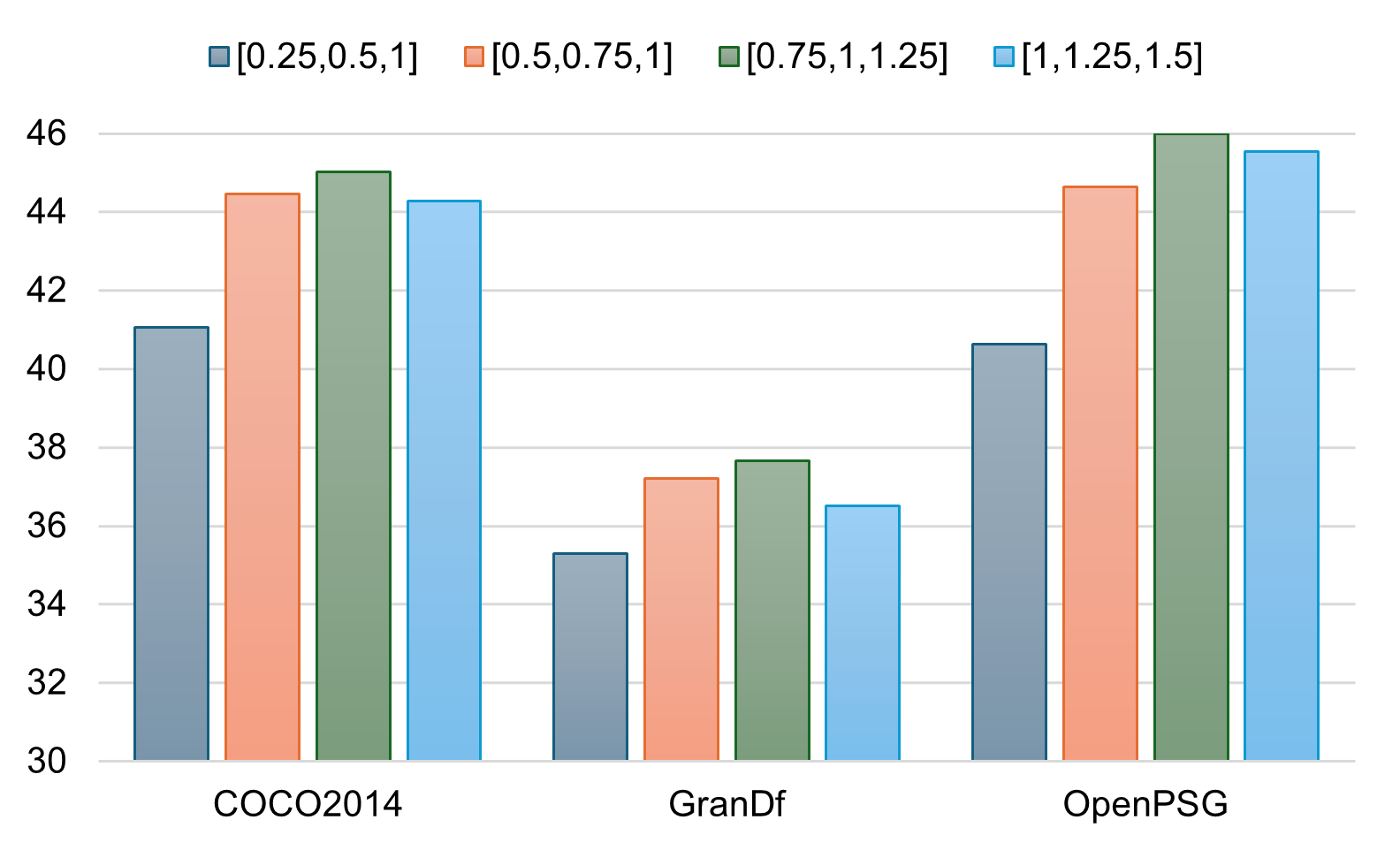
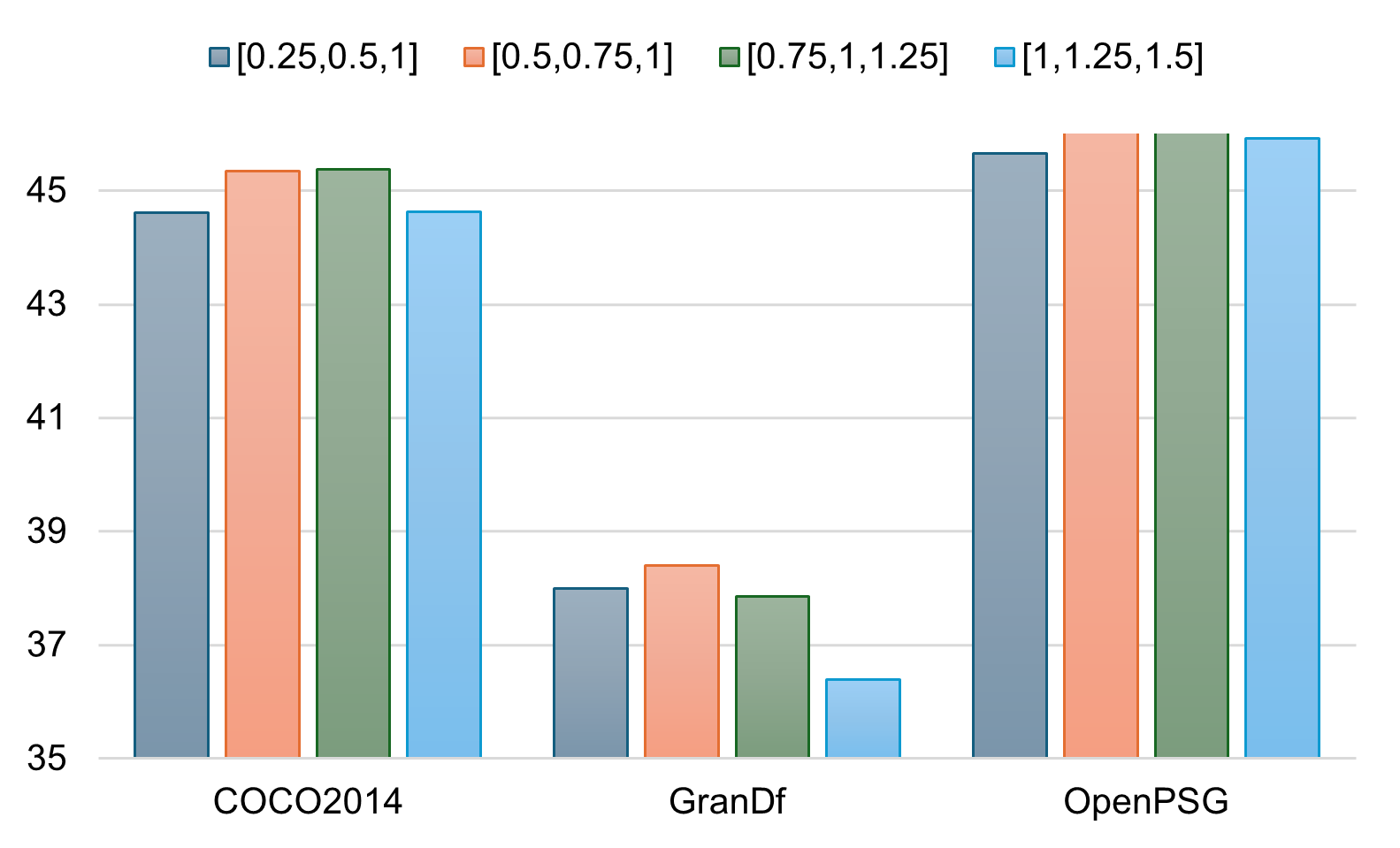
Figure 2: Performance sensitivity to scale factors.
Discussion
The integrations of MSEA and ARC not only improve attribution fidelity but also showcase the importance of modeling intra-modal dynamics within MLLMs. These enhancements allow for more precise diagnostics of model behavior, facilitating safer deployment in applications demanding high trust levels. The results suggest that integrating multi-scale spatial contexts, alongside effective contextual suppression mechanisms, yields significant improvements in model interpretability.
Conclusion
By addressing the overlooked aspect of intra-modal interactions, this research proposes significant advancements in the field of MLLM interpretability. The introduced methods, MSEA and ARC, demonstrate robust capability across models and tasks, enhancing the quality of explanations and enabling deeper insights into model behaviors. Future work could explore further fine-tuning of these methods and their integration into broader model architectures to enhance transparency in more complex AI systems.
Figure 3: Visualization of attribution maps generated using the Qwen2-VL-2B model.

Figure 4: Visualization of attribution maps generated using the LLaVA-1.5-7B model.