- The paper introduces Eagle, a framework that attributes autoregressive token generation in MLLMs to specific visual regions using necessity and sufficiency scores.
- The method employs a greedy search strategy to rank perceptual subregions, significantly outperforming baseline methods on localization and hallucination analysis in models like LLaVA-1.5.
- The framework quantifies modality reliance by measuring token probability changes with sequential visual input, offering insights for future improvements in interpretability and error mitigation.
Explaining Autoregressive Token Generation in Multimodal LLMs with Eagle
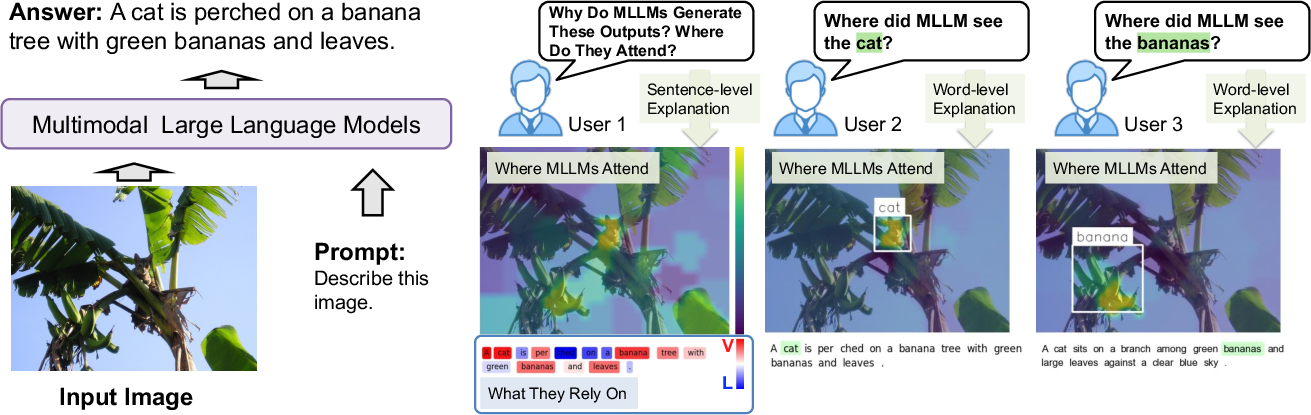
The paper "Where MLLMs Attend and What They Rely On: Explaining Autoregressive Token Generation" presents a new framework, Eagle, aimed at enhancing the interpretability of Multimodal LLMs (MLLMs) by providing insights into which perceptual regions drive token generation and investigating modality reliance.
Introduction
Multimodal LLMs have shown substantial progress by integrating visual and textual data to perform tasks like image captioning and visual question answering (VQA). However, the dependency of generated tokens on visual inputs remains insufficiently understood, complicating their interpretability and trustworthiness. MLLMs are prone to hallucinations, creating unsubstantiated outputs, a significant concern in critical fields like healthcare and autonomous driving. To counter this, the Eagle framework offers a lightweight black-box method to explain token generation in MLLMs by attributing tokens to compact perceptual regions and quantifying the contributions of language priors versus perceptual evidence. This framework uses an objective that considers sufficiency and necessity scores and is optimized via a greedy search strategy.
Eagle Framework
Eagle is designed to attribute any selected set of output tokens to specific perceptual regions. The framework is composed of several components that collectively enhance the interpretability of MLLMs.
- Submodular-inspired Objective: The insight score identifies regions sufficient to maximize token generation probability, while the necessity score reveals indispensable regions. Together, these form an objective function optimizing interpretability.
- Greedy Search: By iterating over candidate subregions and evaluating marginal gains, Eagle constructs an ordered ranking of subregions contributing to token generation.
- Modality Analysis: Eagle assesses whether token generation is more driven by language priors or perceptual evidence by tracking token probability evolution as perceptual regions are introduced sequentially.
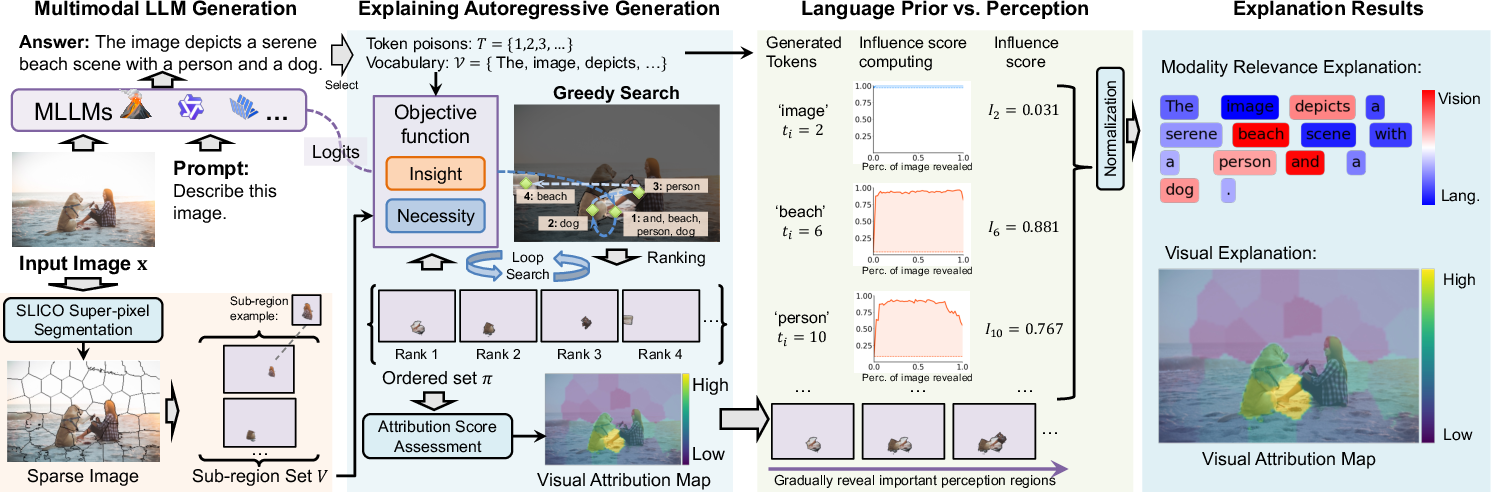
Figure 1: Overview of the proposed Eagle framework. The input image is first sparsified into sub-regions, then attributed via greedy search with the designed objective, and finally analyzed for modality relevance between language priors and perceptual evidence.
Experimental Evaluation
The framework was evaluated on models like LLaVA-1.5, Qwen2.5-VL, and InternVL3.5 using datasets such as MS COCO and MMVP. Eagle's performance was compared against existing methods such as LLaVA-CAM, IGOS++, and TAM.
Conclusion
Eagle offers an efficient solution to advance the interpretability of MLLMs by accurately attributing the generation of tokens to specific perceptual inputs and quantifying their reliance on different modalities. Despite its success, it faces scalability challenges and does not yet prevent hallucinations proactively. Future work could focus on enhancing the scalability of Eagle and leveraging its insights to develop methods for hallucination prevention.