- The paper introduces a three-dimensional taxonomy categorizing MMFMs by model family, interpretability technique, and application domain.
- It demonstrates that methods like linear probing, logit lens, and causal tracing reveal distinct patterns of cross-modal information integration.
- The survey outlines practical challenges—such as dataset curation, scalability, and circuit analysis—and proposes future research directions for robust MMFM interpretability.
Mechanistic Interpretability in Multi-Modal Foundation Models: A Comprehensive Survey
Introduction
The proliferation of multi-modal foundation models (MMFMs)—encompassing non-generative vision-LLMs, multimodal LLMs (MLLMs), and text-to-image diffusion models—has catalyzed a surge in research on their interpretability. While mechanistic interpretability for LLMs is relatively mature, MMFMs introduce unique challenges due to their cross-modal architectures and the complexity of their learned representations. This survey systematically reviews mechanistic interpretability methods for MMFMs, categorizing them by their origins (LLM-adapted vs. multimodal-specific), the model families they target, and their downstream applications.
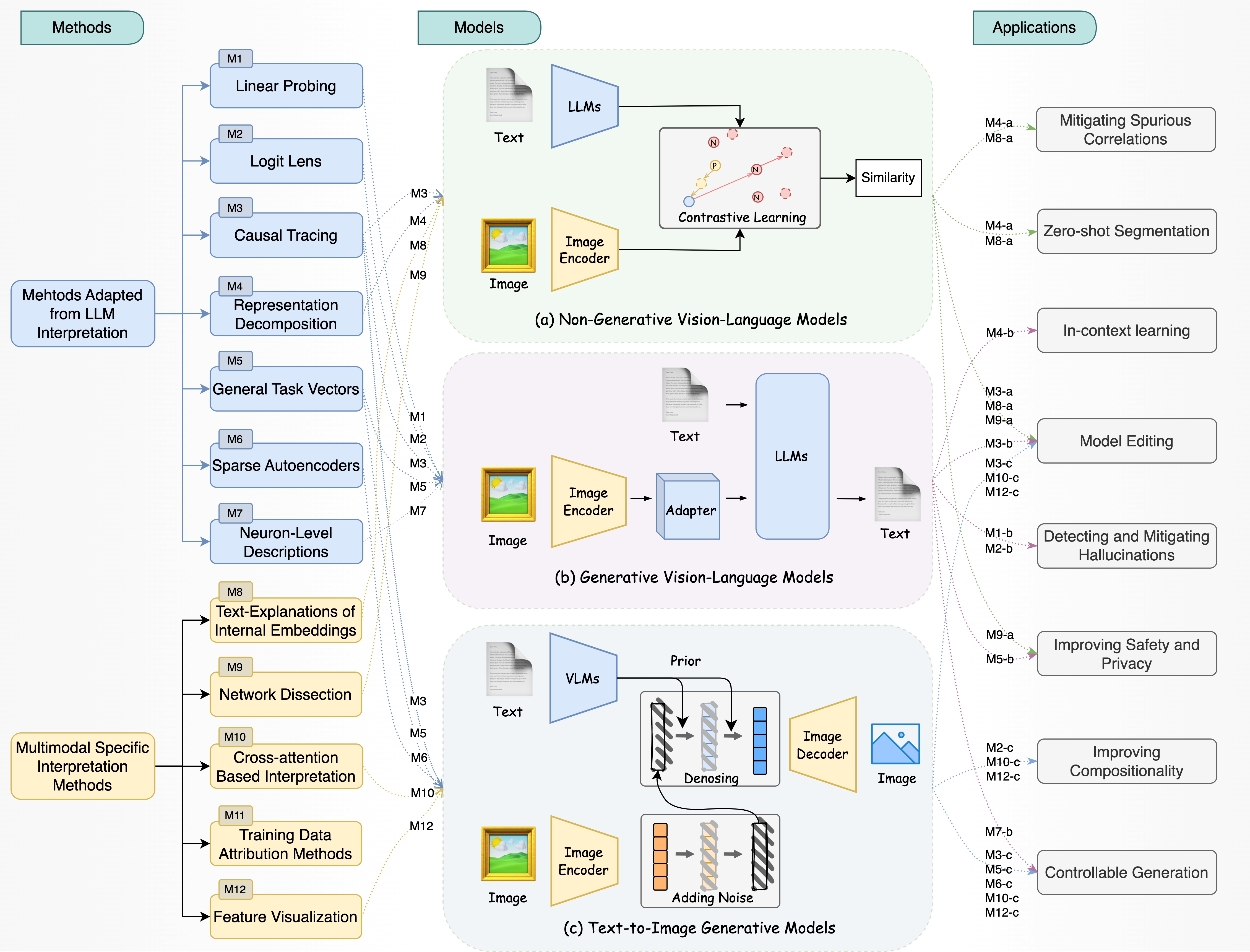
Figure 1: Taxonomy of mechanistic interpretability methods for MMFMs, distinguishing LLM-adapted and multimodal-specific techniques across three model families and their application domains.
Taxonomy and Model Families
The survey introduces a three-dimensional taxonomy: (1) model family (non-generative VLMs, MLLMs, diffusion models), (2) interpretability technique (LLM-adapted vs. multimodal-specific), and (3) application domain. This structure clarifies the landscape and highlights underexplored areas, such as mechanistic interpretability for unified vision-text generation models and advanced diffusion transformers.
- Non-generative VLMs (e.g., CLIP, ALIGN) employ separate text and vision encoders, primarily for retrieval and zero-shot classification.
- Text-to-image diffusion models (e.g., Stable Diffusion, SDXL, DALL·E 2) integrate text encoders and U-Net/transformer-based denoisers, supporting generative tasks and image editing.
- MLLMs (e.g., LLaVa, MiniGPT-4, BLIP-2) bridge vision encoders to LLMs via learned adapters, enabling VQA, captioning, and instruction following.
LLM-Adapted Mechanistic Interpretability Methods
Linear Probing
Linear probing, a supervised diagnostic tool, assesses the encoding of semantic or visual concepts in intermediate representations. In MMFMs, probing reveals that cross-modal interactions are often captured in intermediate layers, while upper layers may overfit to modality-specific or local details. The main limitation is the need for curated probing datasets and the scalability challenge across diverse architectures.
Logit Lens
The logit lens projects intermediate activations to the output vocabulary, enabling layer-wise tracking of model predictions. In MMFMs, early layers often yield more robust predictions to adversarial or misleading inputs, and logit lens analysis can facilitate anomaly detection and early exiting. Extensions include contextual embedding-based hallucination detection and attention lens variants for visual token analysis.
Causal Tracing and Circuit Analysis
Causal tracing, rooted in interventionist causal inference, identifies network components responsible for specific predictions by perturbing intermediate states. In MMFMs, causal tracing localizes knowledge of visual concepts, styles, or facts to specific layers or modules (e.g., cross-attention in diffusion models, bridge modules in MLLMs). Circuit analysis remains underdeveloped for MMFMs due to the complexity of cross-modal computational graphs.
Representation Decomposition
Representation decomposition dissects transformer layers into attention and MLP/FFN components, attributing semantic and factual knowledge to specific submodules. In MMFMs, this approach reveals hierarchical integration of modalities: shallow layers fuse modalities, intermediate layers encode global semantics, and deep layers refine task-specific details. In diffusion models, U-Net layer decomposition distinguishes semantic from denoising functions.
Task Vectors and Sparse Autoencoders
Task vectors, derived from supervised datasets, enable controlled editing of model behavior by adding directional embeddings to intermediate representations. In MMFMs, they support attribute control in image generation and editing. Sparse autoencoders (SAEs) provide an unsupervised alternative, discovering interpretable directions in representation space, but their efficacy for fine-grained control in MMFMs is not yet established.
Neuron-Level Analysis
Neuron-level methods, including gradient-based attribution and activation-based analysis, identify neurons encoding specific concepts or modalities. In MMFMs, these methods uncover domain- and modality-specific neurons, as well as "dead" or redundant units. However, the dynamics of neuron interactions, especially in generative settings, remain insufficiently explored.
Multimodal-Specific Interpretability Methods
Textual Explanations of Internal Embeddings
Techniques such as TextSpan and SpLiCE map internal embeddings or attention heads to human-interpretable textual concepts, primarily in CLIP-like models. These methods facilitate the identification of where knowledge is stored but are currently limited to simple concepts and specific architectures.
Network Dissection
Network Dissection (ND) aligns neuron activations with ground-truth concept annotations, assigning semantic labels to individual units. While effective for CNNs and CLIP, ND's generalization to diffusion models and advanced transformers is unproven.
Cross-Attention Analysis
Cross-attention layers, central to diffusion models and MLLMs, are analyzed to localize the flow of information between modalities. Mechanistic studies have shown that a small subset of cross-attention layers encode most of the knowledge required for style, object, or fact generation, enabling targeted model editing and compositionality improvements.
Training Data Attribution
Attribution methods trace the influence of training examples on specific predictions. For diffusion models, unlearning-based, gradient-based (e.g., K-FAC, TRAK), and training dynamics-based methods have been adapted, but scalability and retraining costs remain significant obstacles.
Feature Visualization
Feature visualization, including gradient-based heatmaps and relevance propagation, provides spatial explanations for model predictions. In MMFMs, these methods have been extended to visualize cross-modal interactions and the evolution of attention during diffusion steps.
Applications of Mechanistic Insights
In-Context Learning
Task vectors and mechanistic analysis have enabled compression of long prompts and transfer of in-context learning capabilities across modalities in MLLMs. However, the application of these techniques to more complex tasks remains open.
Model Editing
Mechanistic localization of knowledge enables efficient, targeted editing of MMFMs. For diffusion models, editing a small set of cross-attention layers can modify or remove specific visual concepts. In MLLMs, causal tracing and closed-form interventions allow for factual correction and knowledge injection.
Hallucination Detection and Mitigation
Mechanistic interpretability informs the detection and removal of hallucinated content, particularly in VQA and captioning tasks. Methods leveraging logit lens, attention analysis, and feature editing have shown promise, but comprehensive benchmarks for MMFMs are lacking.
Safety, Privacy, and Compositionality
Mechanistic tools support the ablation of harmful features, privacy risk assessment, and the improvement of compositional generalization. For example, SAEs and interpretable latent directions have been used to remove unwanted concepts and enhance safe generations in diffusion models.
Other Applications
Mechanistic insights facilitate controlled image generation, zero-shot segmentation, and the mitigation of spurious correlations by ablating or editing specific components identified through representation decomposition and textual explanations.
While the LLM community benefits from mature interpretability toolkits and benchmarks, MMFM interpretability tools are fragmented and lack unified evaluation standards. The survey identifies several open challenges:
- Mechanistic analysis of unified vision-text generation models and advanced diffusion transformers.
- Extension of circuit analysis and sparse autoencoder control to MMFMs.
- Scalable, retraining-free data attribution methods.
- Comprehensive benchmarks for interpretability and hallucination detection in MMFMs.
Conclusion
This survey provides a structured synthesis of mechanistic interpretability methods for MMFMs, highlighting the adaptability of LLM-based techniques, the emergence of multimodal-specific approaches, and the critical gaps in current understanding. The taxonomy and analysis presented serve as a roadmap for future research, emphasizing the need for scalable, generalizable, and application-driven interpretability frameworks. The implications extend to model safety, reliability, and the principled deployment of MMFMs in real-world systems.