- The paper demonstrates that text bias in MLLMs fundamentally arises from misaligned attention key spaces, where visual tokens are out-of-distribution relative to text keys.
- Methodologies such as PCA, t-SNE, MMD, and JS divergence quantify and visualize the persistent geometric separation between visual and textual features.
- Findings suggest that architectural interventions for key-space alignment are essential to mitigate modality gaps and improve multimodal reasoning.
Intrinsic Text Bias in Multimodal LLMs: An Attention Key-Space Perspective
Introduction
This paper investigates the origins of text bias in Multimodal LLMs (MLLMs), specifically focusing on the internal mechanisms of attention rather than external factors such as data imbalance or instruction tuning. The central hypothesis is that the attention key space, learned predominantly from text during pretraining, is inherently misaligned with visual features introduced via vision encoders and projectors. This misalignment results in visual key vectors being out-of-distribution (OOD) relative to the text key space, leading to systematically lower attention scores for visual tokens and, consequently, a pronounced text bias in multimodal reasoning.
Methodology
Model and Data Selection
The study analyzes two representative open-source MLLMs: LLaVA-1.5-7B (Vicuna-7B base with CLIP ViT-L/14 encoder and linear projection) and Qwen2.5-VL-7B (Q-Former adaptor with SigLIP backbone). Evaluation is conducted on the MMBench-CN and MMMU benchmarks, which provide diverse coverage across STEM, humanities, and real-world images with Chinese prompts. Token-level modality metadata is recorded to distinguish between image and text tokens during inference.
Attention Key Extraction and Analysis
Key vectors are extracted from selected decoder layers using hooks on the Key projection layer (K-proj). These vectors, representing the basis for attention similarity computation, are standardized and reduced in dimensionality via PCA (to 50 components) and further embedded into two dimensions using t-SNE for qualitative visualization. Quantitative divergence between modalities is assessed using Maximum Mean Discrepancy (MMD) and Jensen-Shannon (JS) divergence, with intra-modality controls to ensure measurement reliability.
Qualitative Analysis: t-SNE Visualization
t-SNE projections reveal a persistent geometric separation between visual and textual key vectors across all decoder layers and benchmarks. Visual tokens form compact clusters, while textual tokens occupy more diffuse and expansive manifolds. This separation persists even in deeper layers, with only mild drift observed as cross-attention blends modalities. Notably, visual tokens rarely penetrate high-density textual regions, indicating a robust and persistent modality gap.
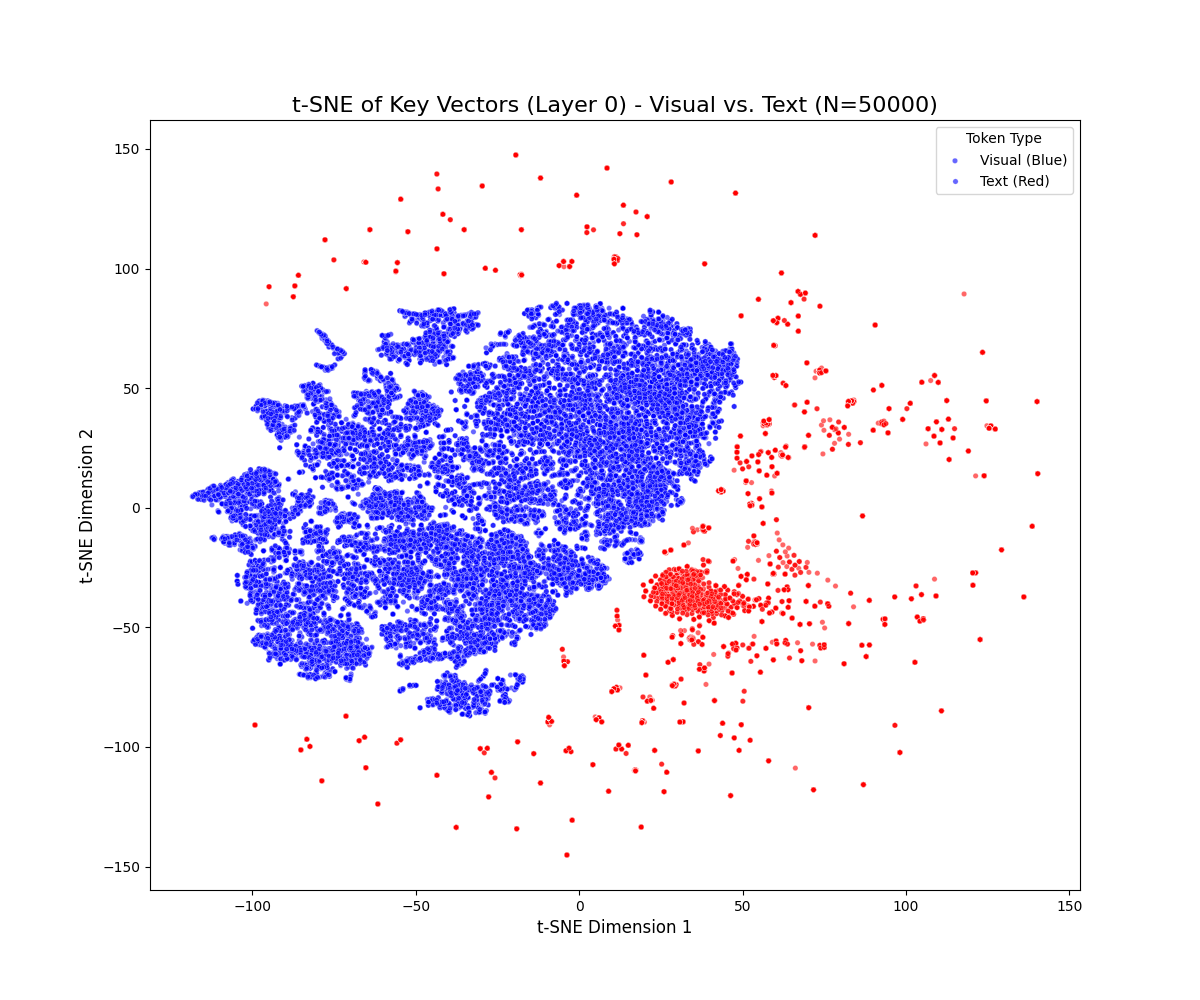
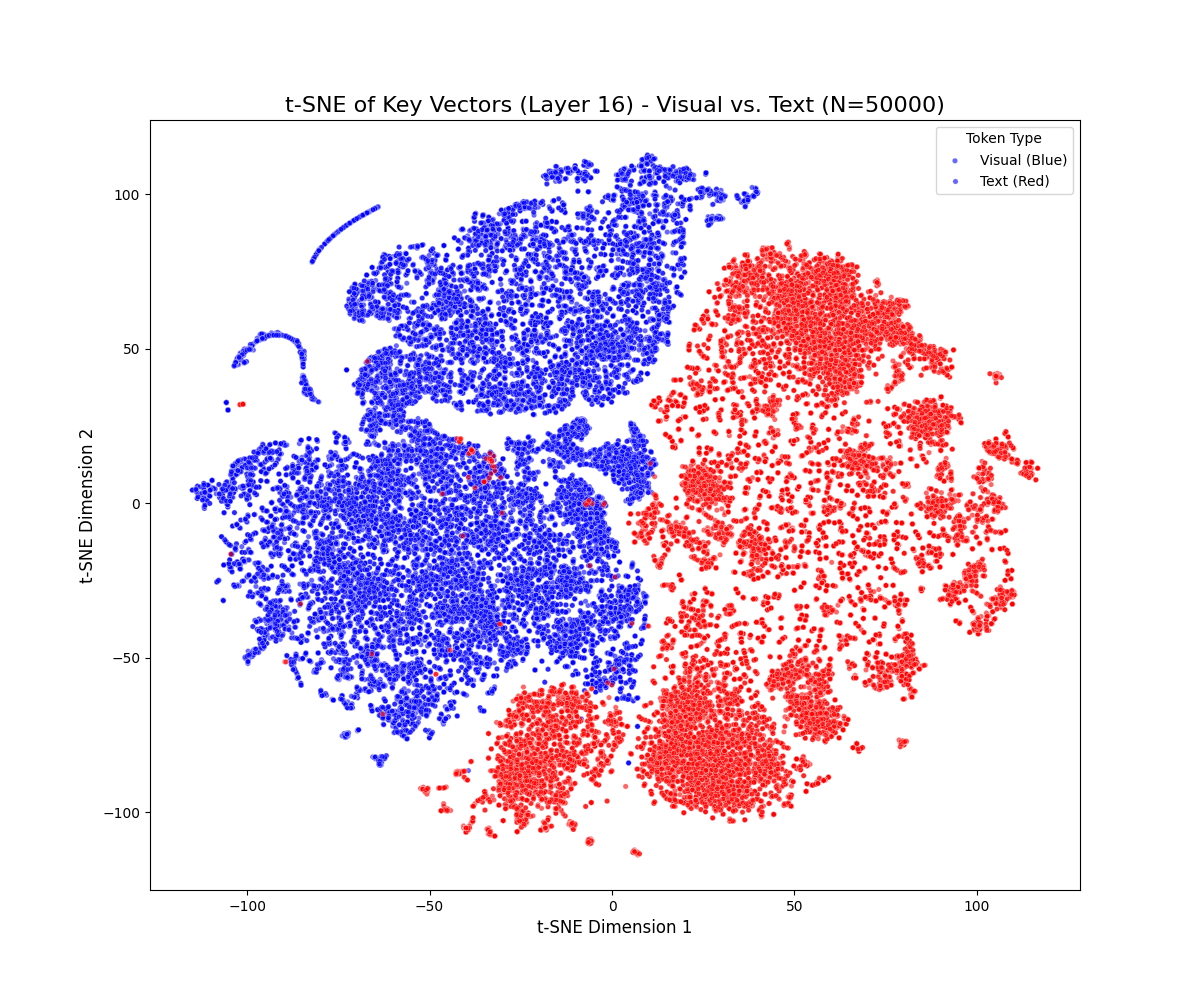
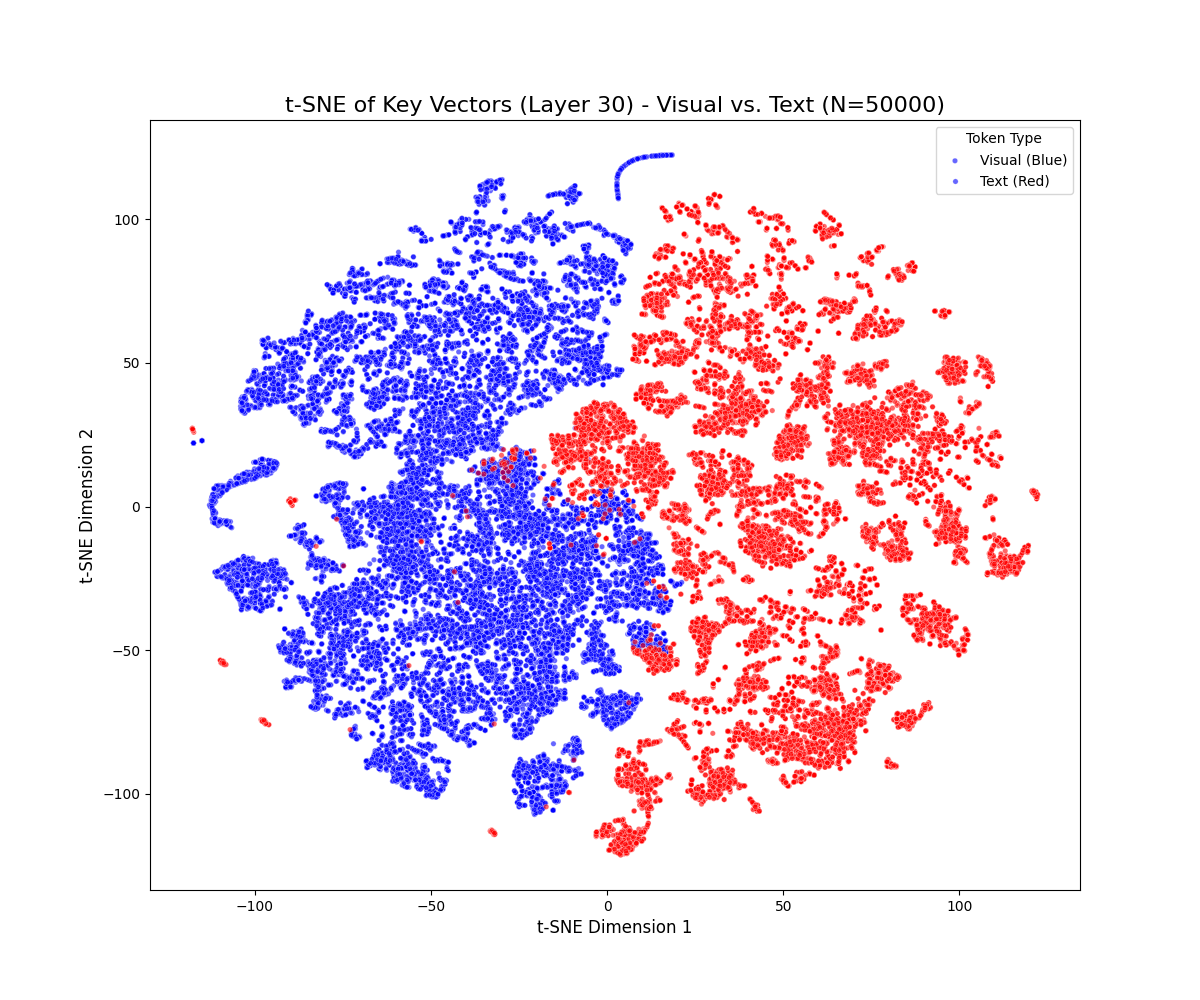
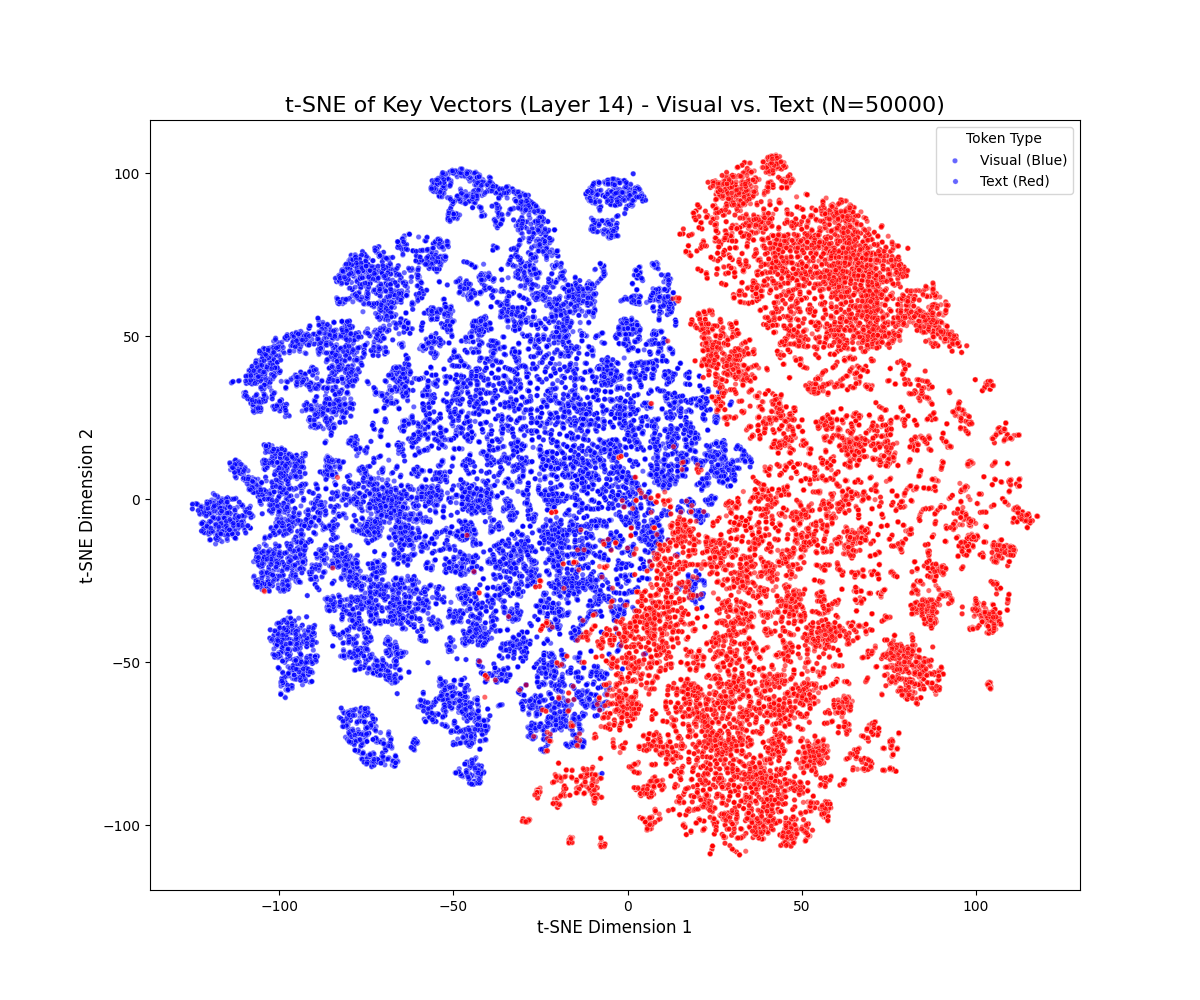
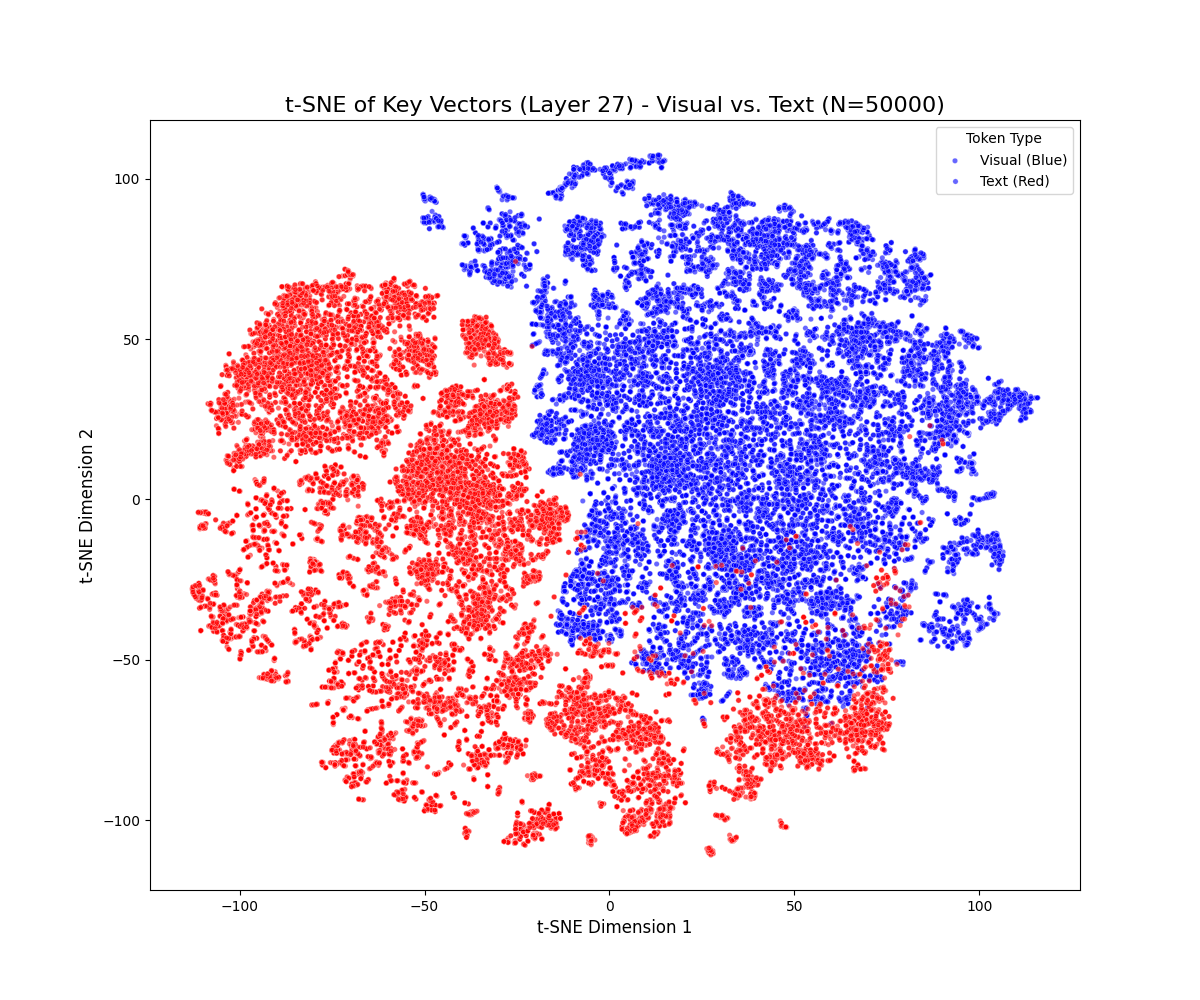
Figure 1: t-SNE projections of key vectors across early, middle, and late layers for LLaVA-1.5-7B (top) and Qwen2.5-VL-7B (bottom) on MMBench-CN and MMMU, demonstrating persistent modality separation.
Dataset-specific effects are observed: MMBench-CN, with longer textual prompts, produces elongated textual trajectories, while MMMU, with denser visual content, yields multiple visual sub-clusters. These results suggest that the modality gap is sensitive to both prompt length and visual diversity but remains a general property of the model architecture.
Quantitative Analysis: Divergence Metrics
Quantitative analysis using MMD and JS divergence confirms the qualitative findings. The mean MMD for cross-modality (Image vs. Text) comparisons is approximately 0.408 (std = 0.346), with a maximum observed value of 1.054 (LLaVA-1.5B, Layer 2). In contrast, intra-modality controls (Image vs. Image, Text vs. Text) yield mean MMD values near zero (0.012 and 0.053, respectively), several orders of magnitude lower than cross-modality comparisons. Permutation tests confirm that these differences are statistically significant (p<10−3).
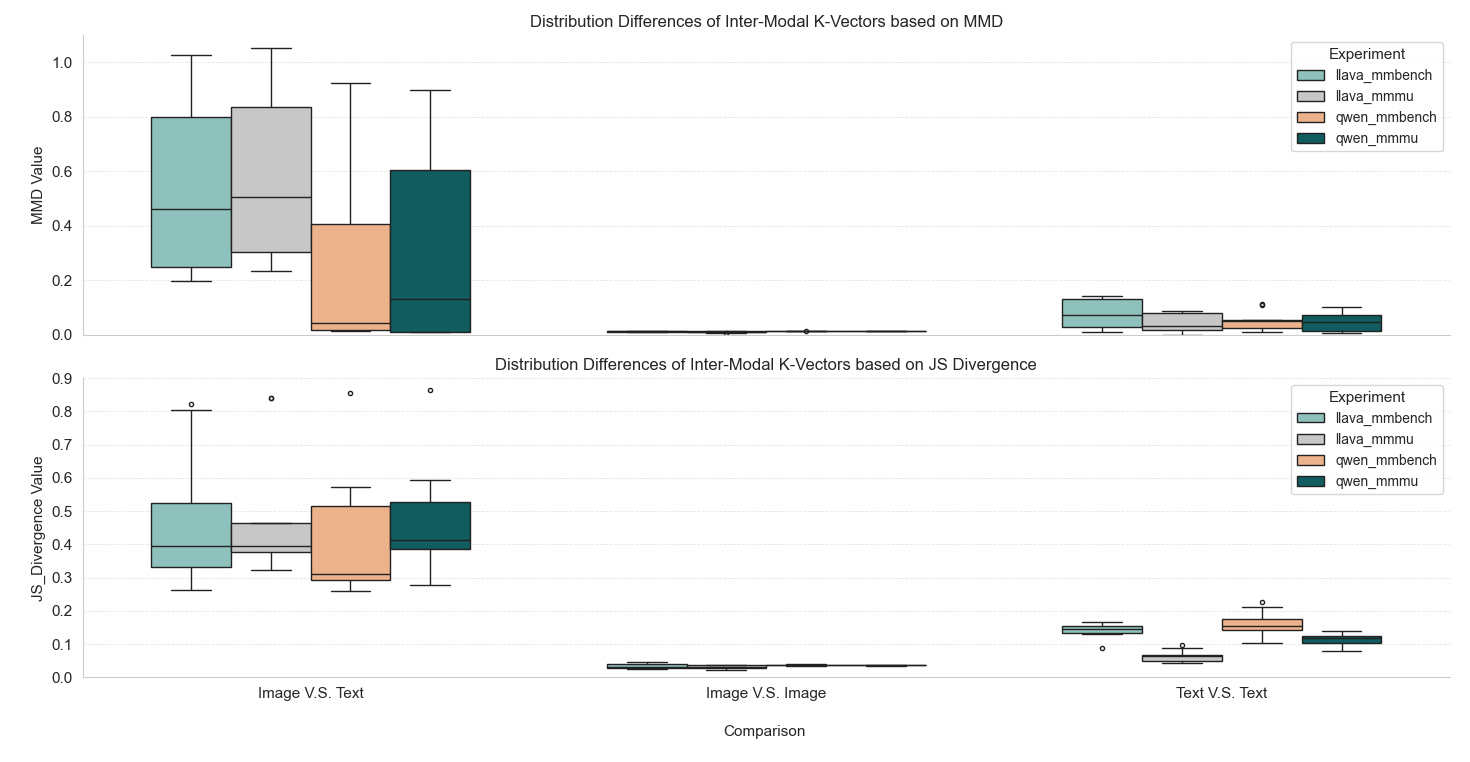
Figure 2: Distribution differences of inter-modal key vectors based on MMD and JS divergence, showing significant separation between cross-modality and intra-modality comparisons.
LLaVA, with its simple linear projection adaptor, exhibits a larger and more robust modality bias than Qwen, as evidenced by higher MMD values. While Qwen's Q-Former design partially reduces the mean feature distance, the JS divergence remains high (median ≈ 0.45), indicating persistent differences in feature distribution shape and density.
Implications and Theoretical Significance
The findings provide direct mechanistic evidence that text bias in MLLMs is rooted in the intrinsic misalignment of the attention key space, rather than being solely attributable to data-level factors. This has several important implications:
- Architectural Bottleneck: The modality gap is a consequence of the LLM backbone's text-centric pretraining, which shapes the key space to favor textual statistics. Visual features, introduced via projectors or adaptors, remain OOD and are systematically under-attended.
- Model Design: The degree of modality bias is sensitive to the choice of visual adaptor. Linear projections (as in LLaVA) exacerbate the gap, while more sophisticated adaptors (as in Qwen) can partially mitigate, but not eliminate, the bias.
- Evaluation and Benchmarking: The modality gap is robust across benchmarks and languages, indicating that it is a general property of current MLLM architectures.
- Remediation Strategies: Addressing text bias requires architectural interventions aimed at aligning the key spaces of different modalities, rather than relying solely on data balancing or prompt engineering.
Future Directions
The study suggests several avenues for future research:
- Key-Space Alignment: Developing training objectives or architectural modifications that explicitly align visual and textual key spaces within the attention mechanism.
- Cross-Modal Pretraining: Incorporating joint pretraining strategies that expose the model to both modalities from the outset, potentially reducing the OOD nature of visual keys.
- Interpretability: Leveraging attention-space analysis as a diagnostic tool for understanding and mitigating modality bias in MLLMs.
- Generalization: Extending the analysis to other modalities (e.g., audio, video) and larger-scale models to assess the universality of the observed phenomena.
Conclusion
This work demonstrates that the text bias observed in state-of-the-art MLLMs is fundamentally an architectural issue, arising from the misalignment of attention key spaces between modalities. Both qualitative and quantitative analyses provide strong evidence for a persistent and statistically significant modality gap, which is robust across models, layers, and benchmarks. The results underscore the need for architectural solutions targeting key-space alignment to achieve balanced and interpretable multimodal reasoning in future MLLMs.