- The paper demonstrates that structural assumptions in LLM post-training reduce RL benefits to those of supervised fine-tuning.
- The study reveals that the GRPO algorithm simplifies to iterative supervised fine-tuning, yielding comparable performance on benchmarks like GSM8K.
- Experiments highlight a length bias from uniform reward distribution, inadvertently encouraging verbosity over genuine reasoning.
Analyzing the Structural Assumptions of RL Post-training for LLMs
Introduction
The paper "RL in Name Only? Analyzing the Structural Assumptions in RL post-training for LLMs" investigates the assumptions underlying the application of Reinforcement Learning (RL) for the post-training of LLMs. The research dissects the structural assumptions made when framing LLM token generation as a Markov Decision Process (MDP) and illustrates how these assumptions may render RL-based training equivalent to supervised fine-tuning under specific conditions. This paper emphasizes examining GRPO in LLM post-training and its extension into supervised models.
Structural Assumptions of LLM-MDP
The analysis focuses on the two prevalent structural assumptions in LLM-MDP framework:
- States as Sequences of Actions: Each state is defined as a concatenation of previously generated tokens. As a consequence, the state explicitly includes the historical context of actions taken to reach it.
- Terminal Reward with Equal Credit Assignment: Rewards are assigned only at the terminal state based on the sequence's correctness. The credit assignment divides the terminal reward uniformly across tokens in the sequence, deviating from typical RL setups where intermediate states influence decisions.
These assumptions simplify the MDP to a degenerate form where the model effectively operates as a supervised learning framework, demonstrating that genuine reasoning improvements attributed to RL may be overestimated.
GRPO as Iterative Supervised Fine-Tuning
The paper then elaborates on how the Group Relative Policy Optimization (GRPO) algorithm, commonly used for RL-based post-training, reduces to iterative supervised fine-tuning (F-ISFT) under these structural assumptions. It shows that:
- Objective Simplification: The objective function of GRPO can be deconstructed to represent a form of supervised learning, particularly when considering both positive (correct solutions) and negative (incorrect solutions) samples.
- Empirical Equivalence: In experiments using benchmarks like GSM8K and Countdown and base models such as Qwen-2.5, iterative supervised fine-tuning achieved performances comparable to GRPO, suggesting minimal genuine gains from RL in this context.
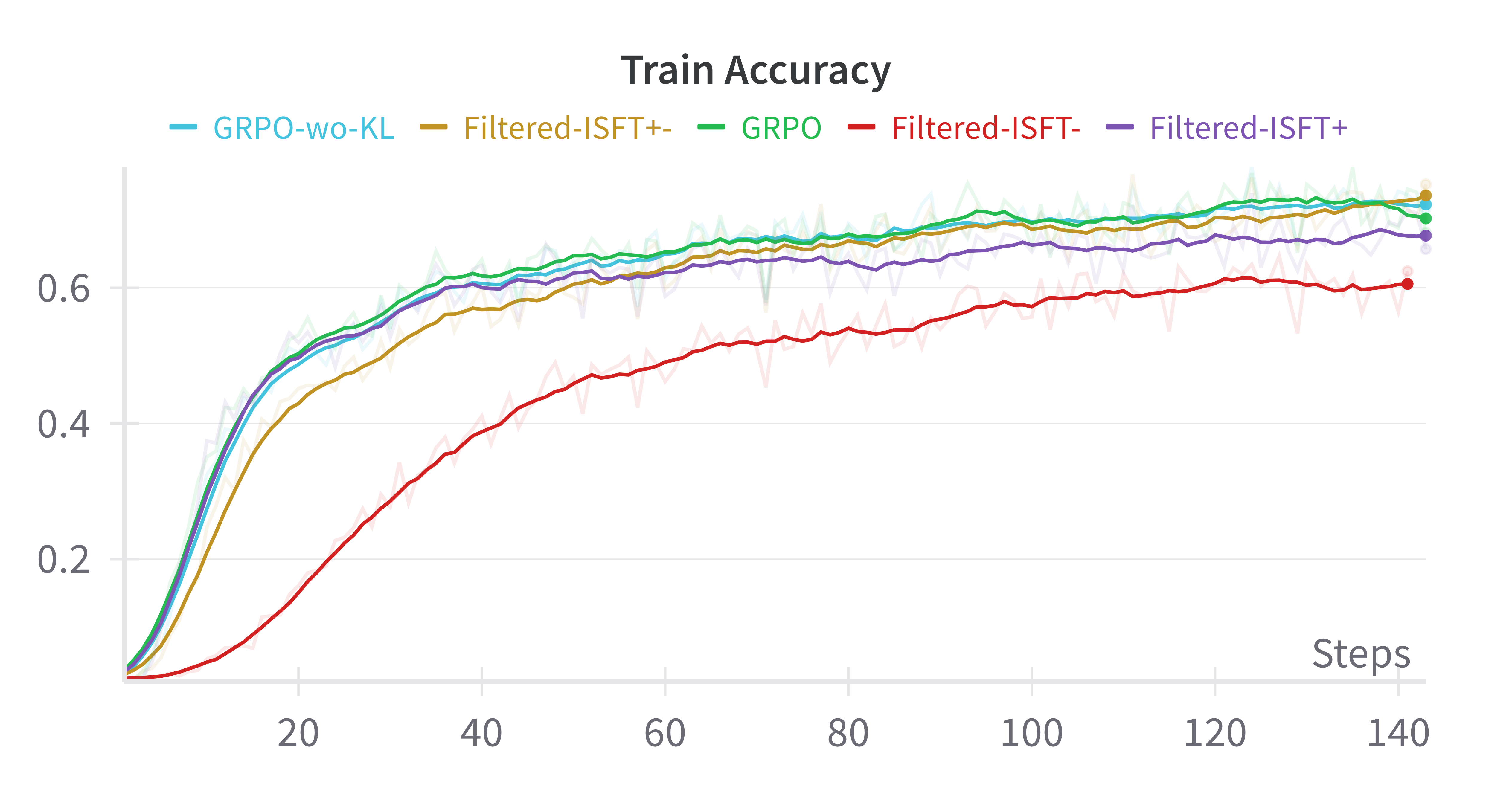
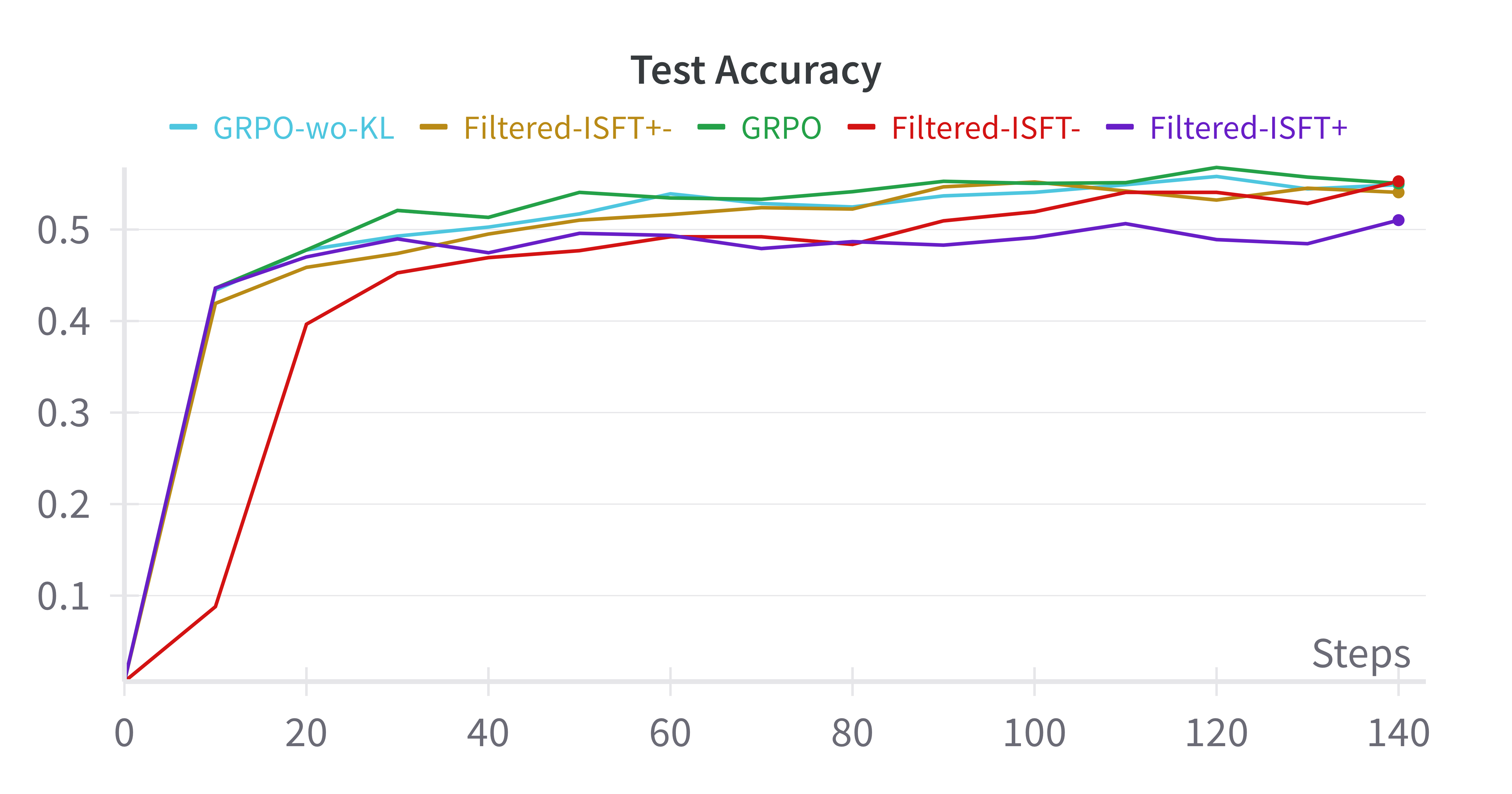
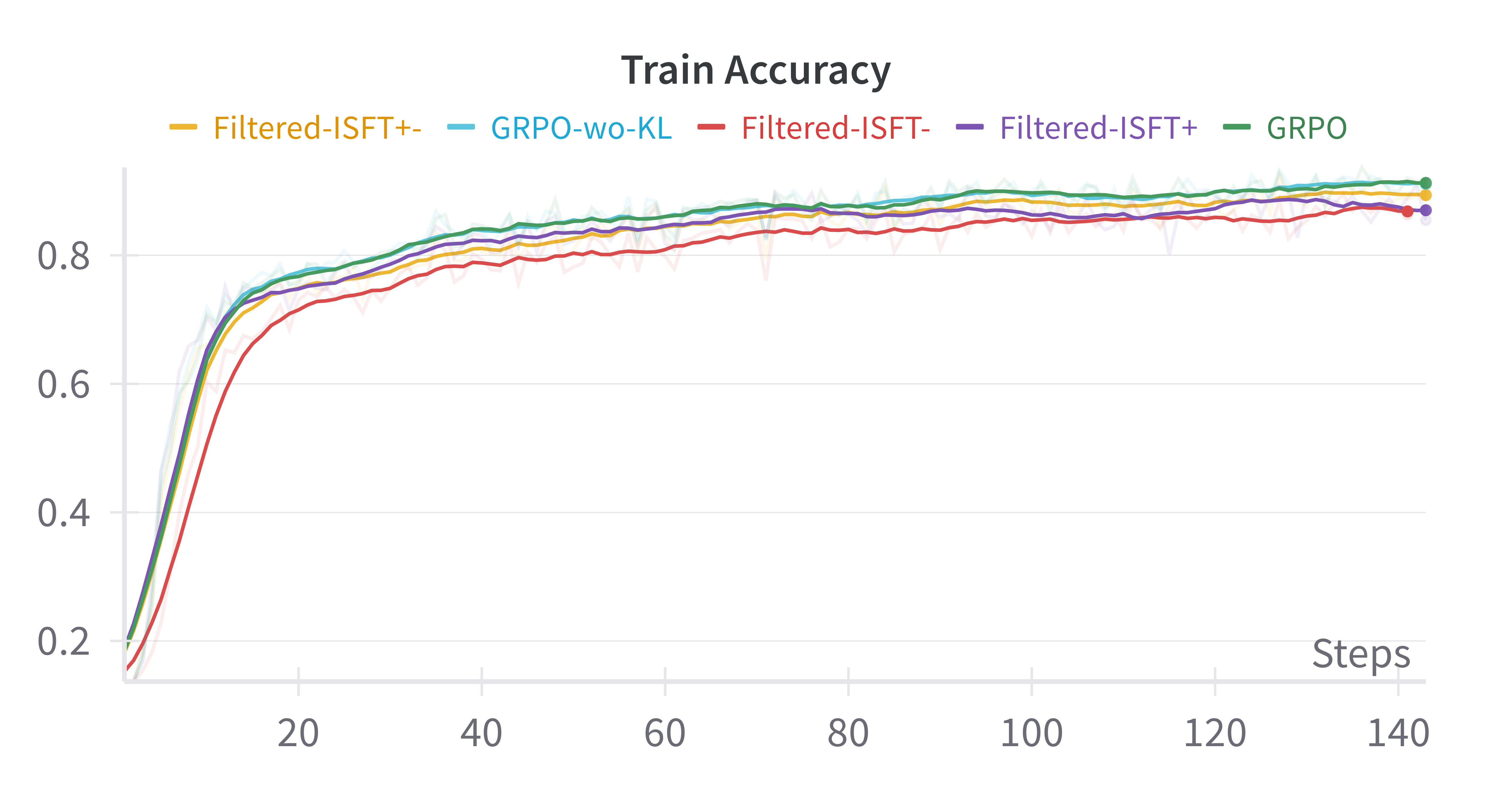
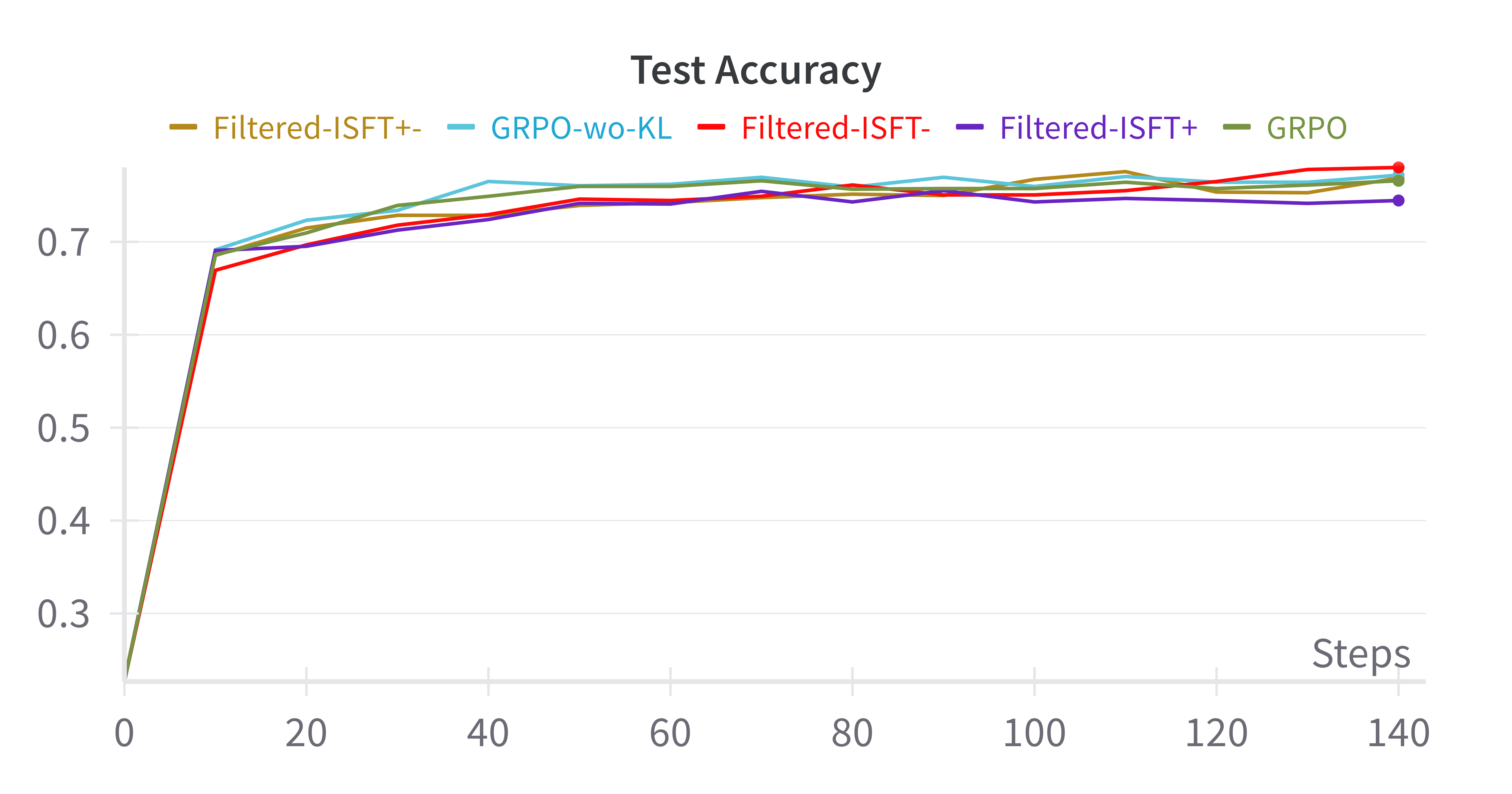
Figure 1: Base-Model:Qwen-2.5-0.5B
Length Bias in RL Models
The paper highlights that the RL framework, particularly GRPO, inadvertently biases models toward longer response sequences. This conclusion arises from distributing relative advantage scores uniformly across tokens, resulting in longer responses.
- Correct Responses vs. Incorrect Responses: For correct answers, shorter responses achieve higher per-token rewards, while longer incorrect responses minimize per-token penalties. This leads to the unintended encouragement of verbosity, often misattributed to improved reasoning.
Experimental Analysis
Experiments reveal the superficial advantages of RL over well-tuned supervised methods. Performance comparisons across training methodologies and model architectures demonstrate:
- Comparable Results: Filtered-ISFT, using both positive and negative samples, paralleled GRPO results, questioning the necessity of RL for performance improvements.
- Training Dynamics: An empirical analysis showed that observed increases in average response length during RL training were primarily due to structural assumptions, not evolved reasoning capabilities.
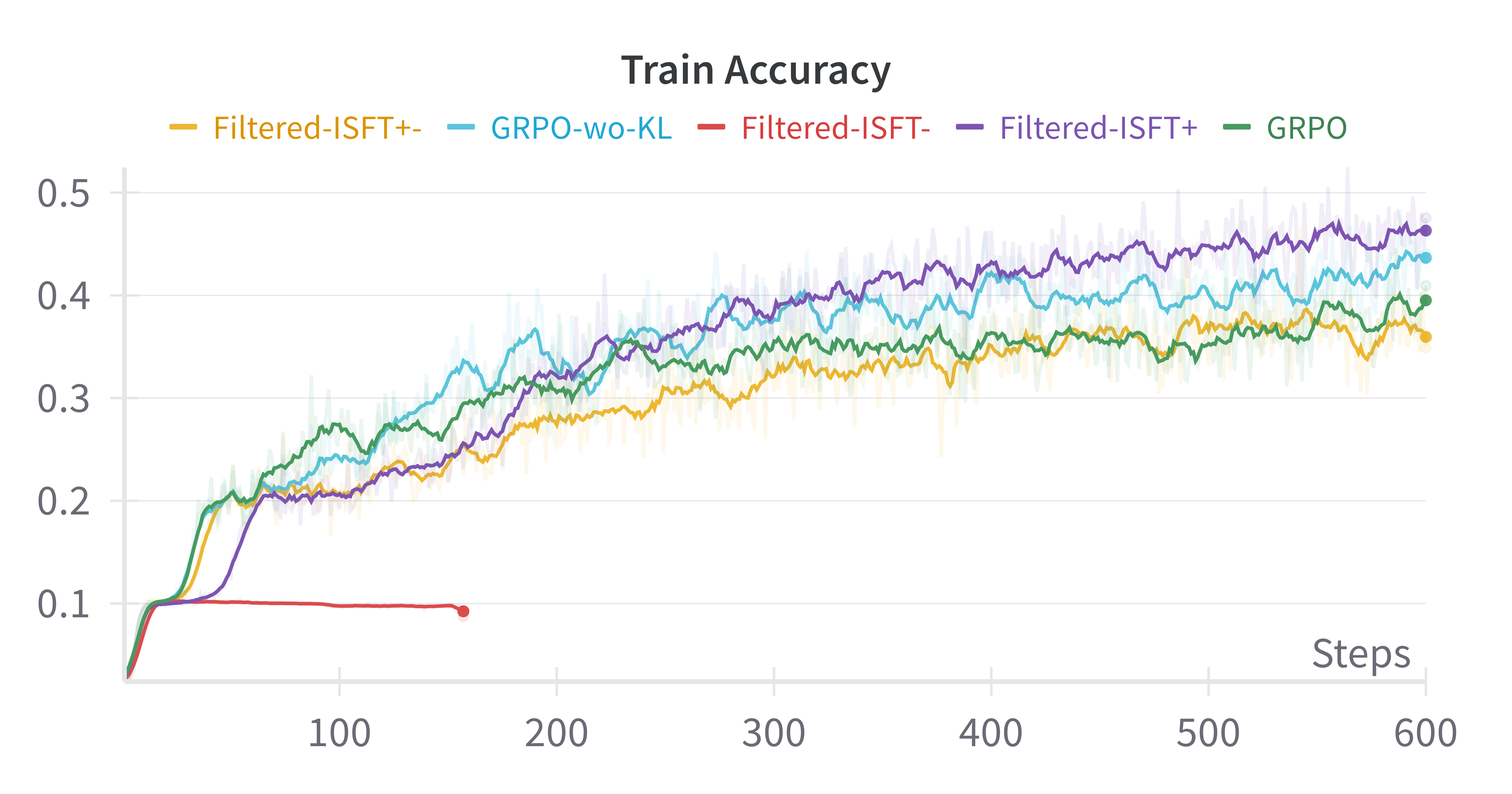
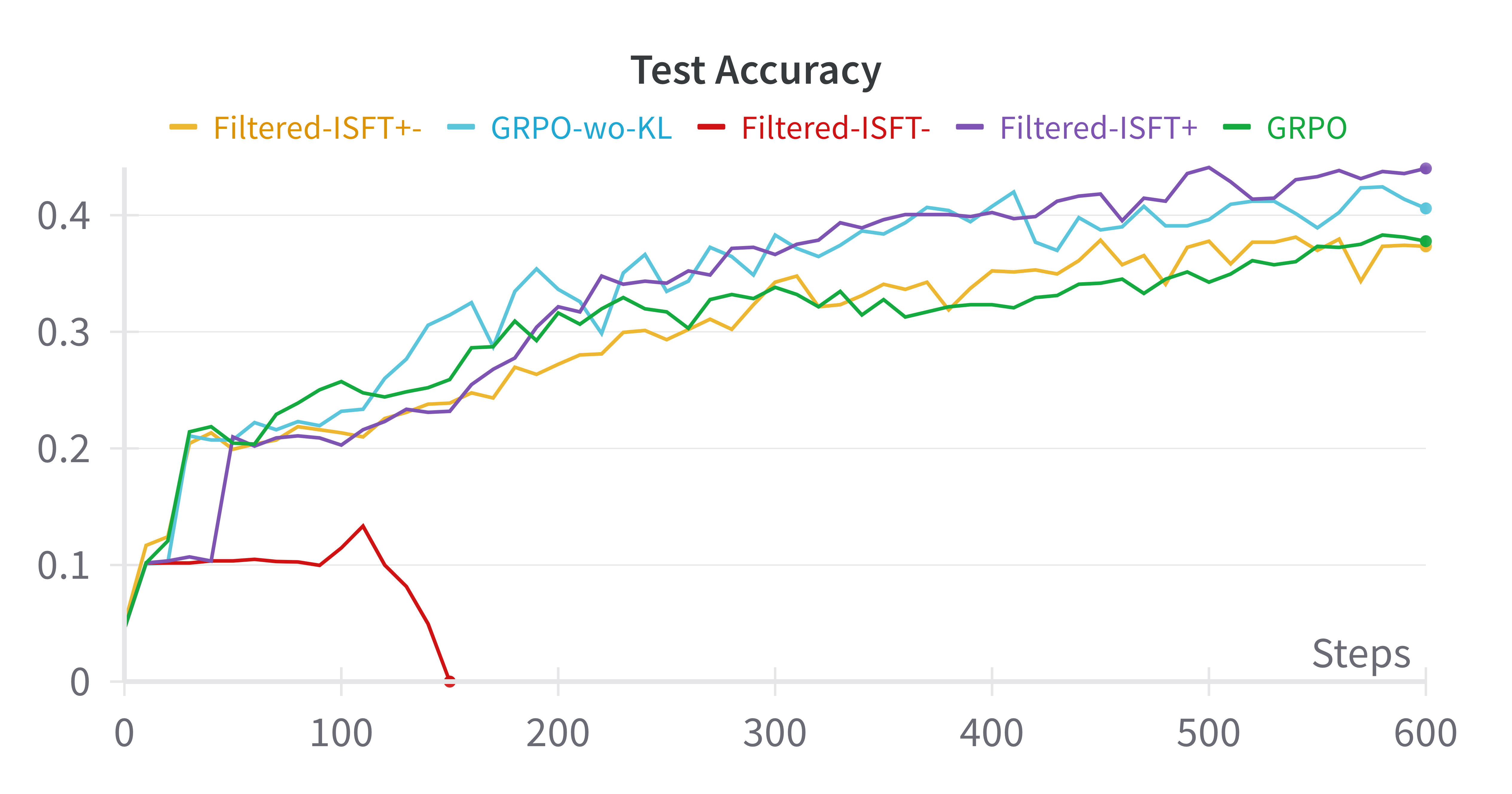
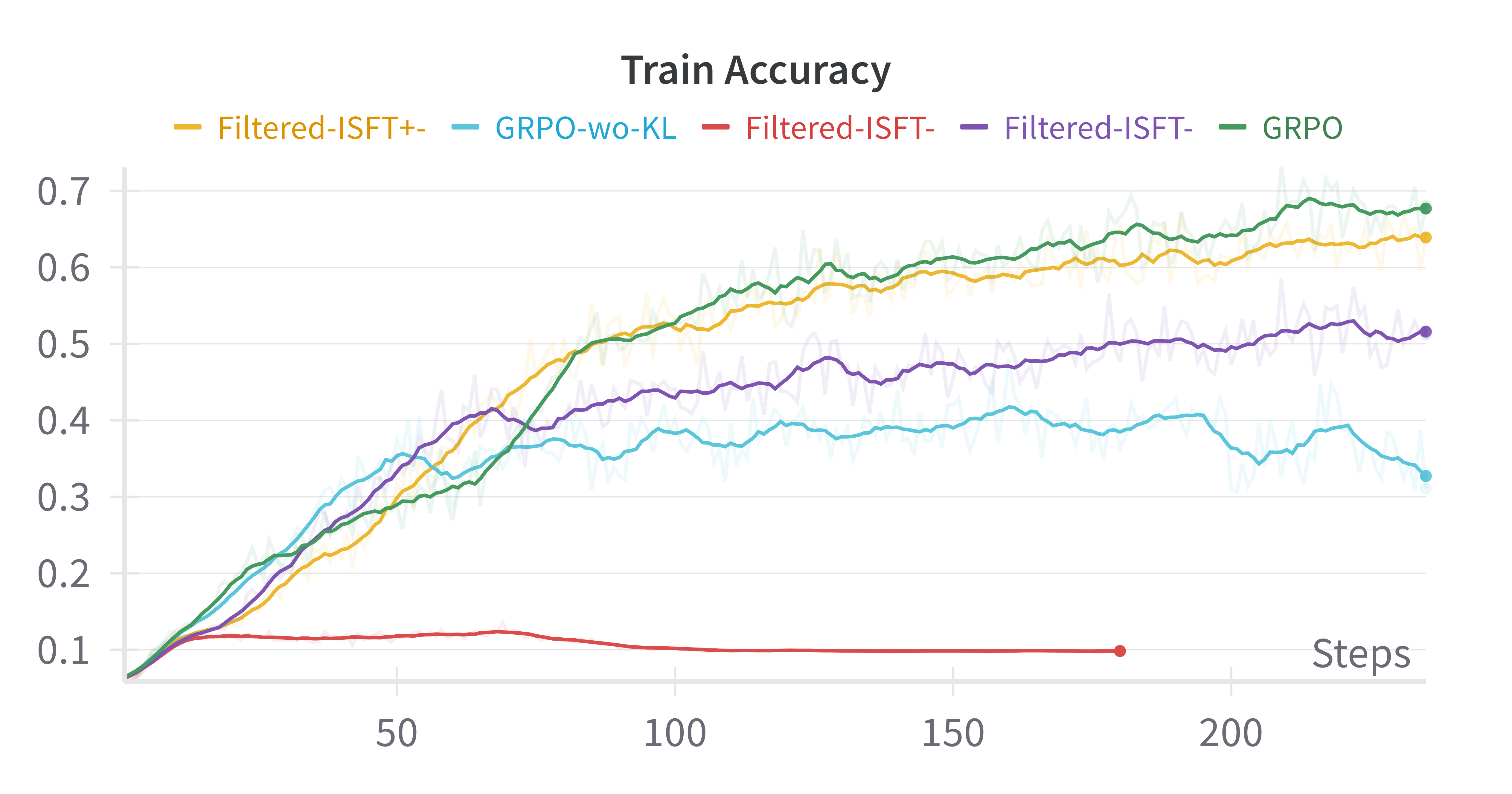
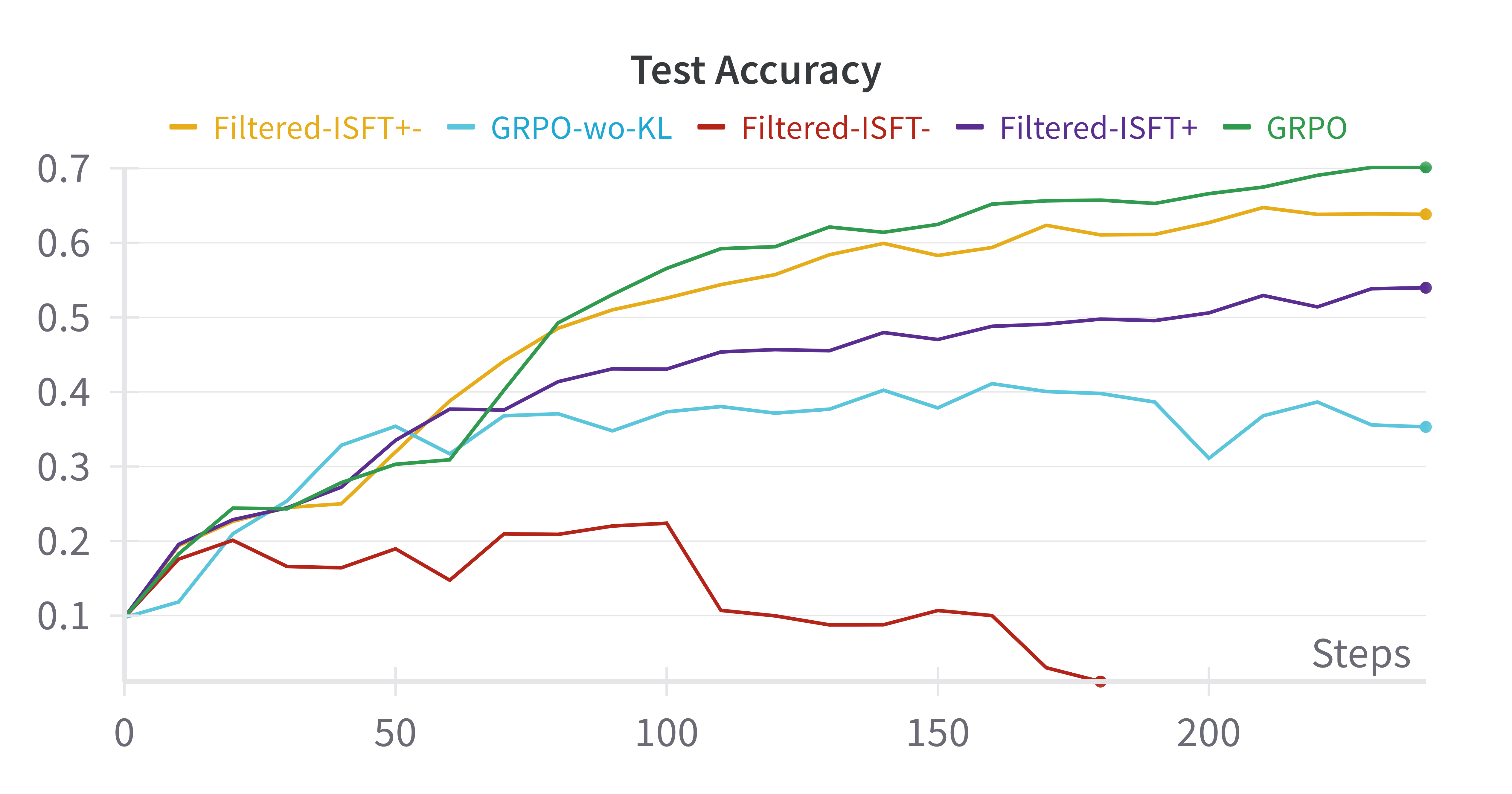
Figure 2: Base-Model:Qwen-2.5-0.5B
Conclusion
The paper concludes that while RL techniques like GRPO have been celebrated for enhancing LLM capabilities, the foundational structural assumptions largely reduce their operations to that of supervised learning. The practical upshot is that LLM post-training can often achieve equivalent outcomes through simpler fine-tuning methods, given the degenerate assumptions in current RL frameworks. Future work should consider alternative MDP formulations to potentially unlock more nuanced applications of RL for LLMs.
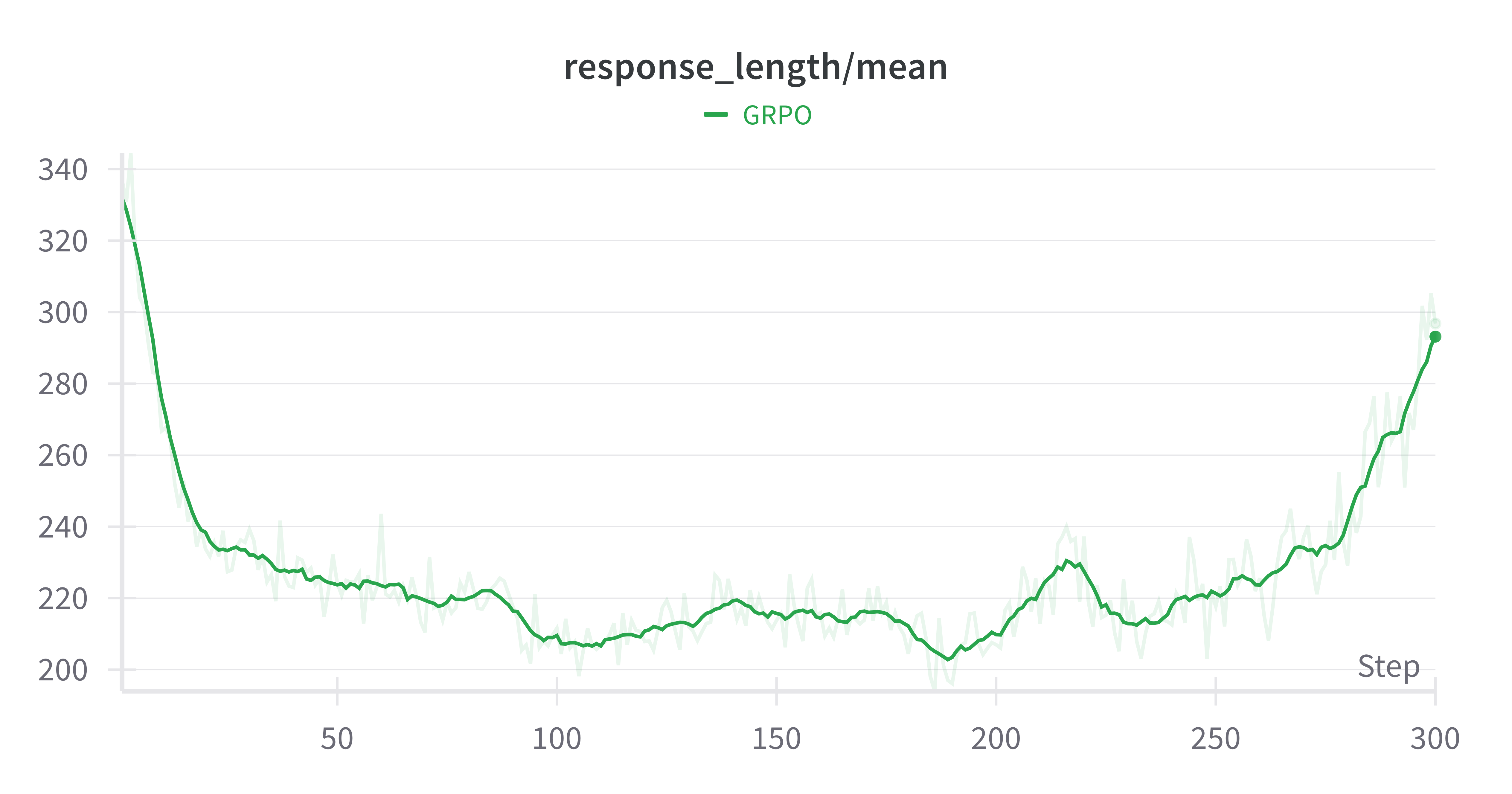
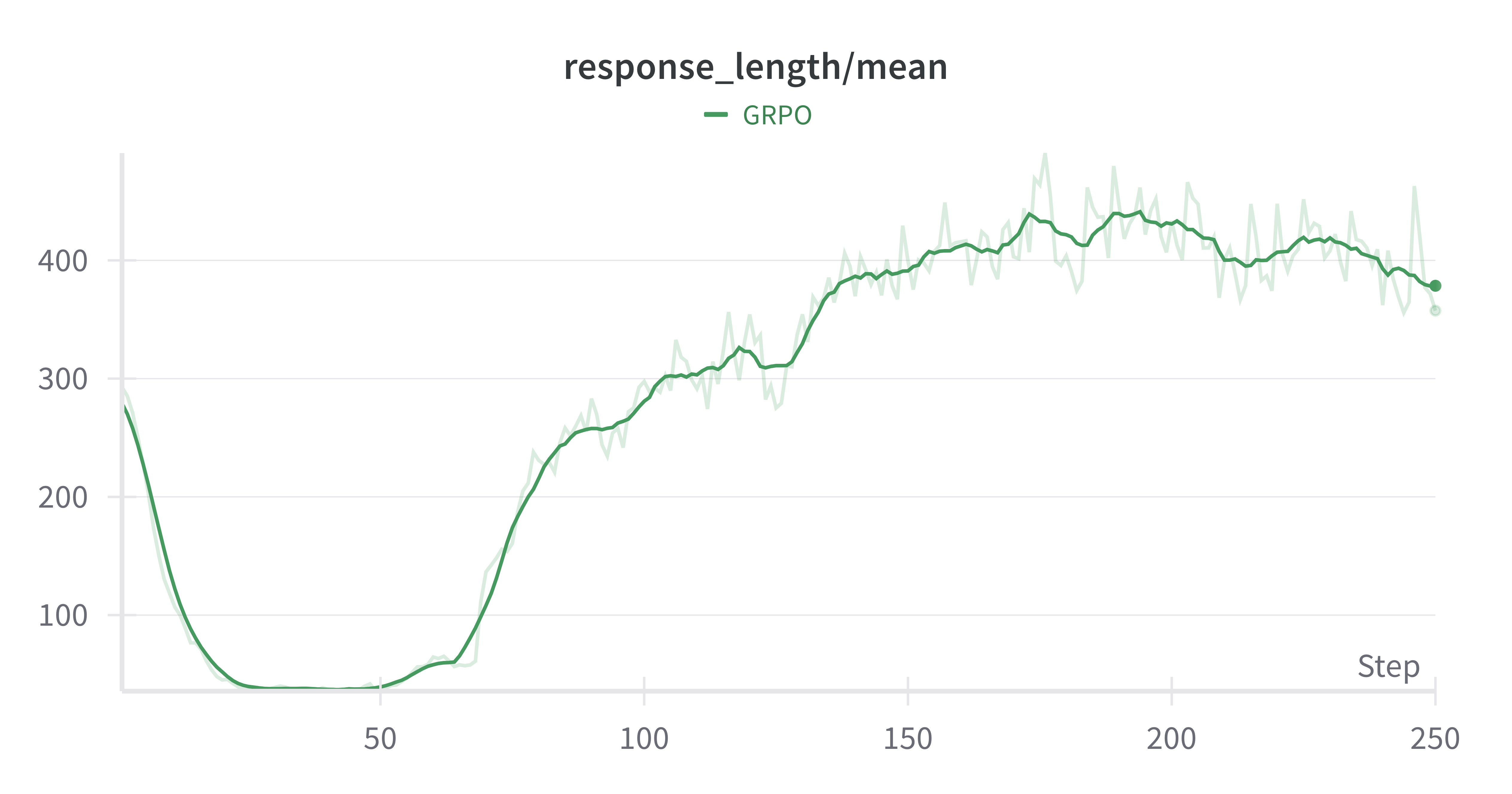
Figure 3: Base-Model:Qwen-2.5-0.5B, GSM8k
The analysis spurs future exploration into developing alternative structural frameworks and potentially re-evaluating the assumptions to genuinely enrich LLM reasoning through RL strategies.