- The paper demonstrates that RL induces a two-phase dynamic – procedural consolidation followed by strategic exploration – in LLMs.
- It introduces HICRA, a targeted credit assignment method that amplifies high-impact planning tokens to enhance reasoning accuracy.
- The research validates semantic entropy as a robust metric for tracking high-level strategy, outperforming traditional token entropy measures.
Emergent Hierarchical Reasoning in LLMs through Reinforcement Learning
Introduction and Motivation
The paper investigates the mechanisms underlying the improvement of complex reasoning abilities in LLMs via Reinforcement Learning (RL). It posits that RL induces an emergent hierarchical reasoning structure in LLMs, analogous to the separation of high-level strategic planning and low-level procedural execution observed in human cognition. The authors identify a two-phase learning dynamic: initial procedural consolidation followed by strategic exploration, and propose Hierarchy-Aware Credit Assignment (HICRA) to address inefficiencies in prevailing RL algorithms by focusing optimization on high-impact planning tokens.
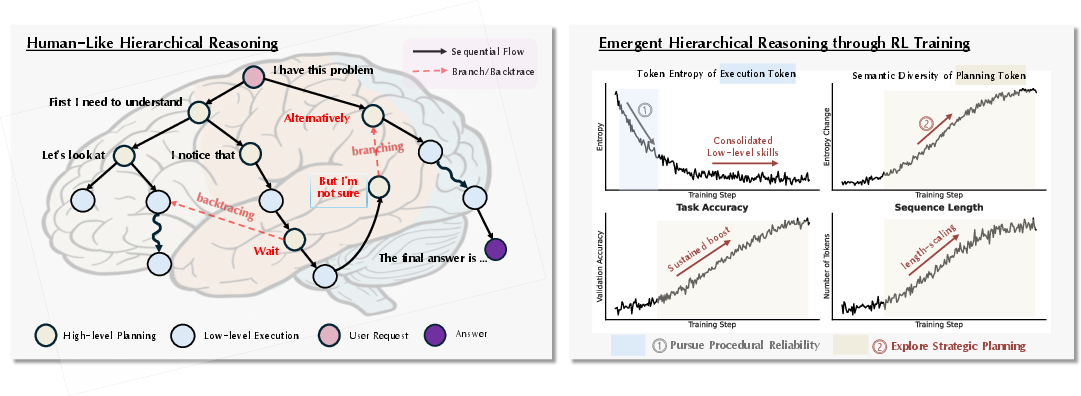
Figure 1: LLM reasoning mirrors human-like hierarchical reasoning, with RL training exhibiting a two-phase dynamic: procedural consolidation followed by strategic planning.
Emergent Reasoning Hierarchy: Two-Phase Dynamics
Empirical analysis across multiple LLM and VLM families (Qwen2.5-7B, Qwen3-4B, Llama-3.1-8B, MiMO-VL-7B) reveals that RL-driven reasoning enhancement is not monolithic. The learning process is characterized by:
- Procedural Consolidation: The model rapidly reduces perplexity and token-level entropy for execution tokens, indicating increased confidence and reliability in low-level operations.
- Strategic Exploration: Once procedural reliability is achieved, the learning bottleneck shifts to high-level planning, evidenced by increased semantic entropy of strategic grams and longer, more accurate reasoning chains.
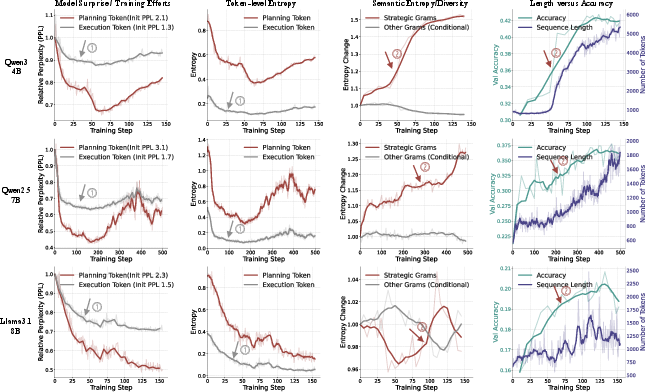
Figure 2: Training dynamics show initial procedural consolidation (decreased perplexity and entropy) followed by strategic exploration (increased semantic entropy and reasoning chain length).
Strategic Grams (SGs), defined as n-grams functioning as semantic units for logical moves (deduction, branching, backtracing), serve as proxies for planning tokens. The functional distinction between planning and execution tokens is operationalized via SGs, enabling targeted analysis of learning dynamics.

Figure 3: Example reasoning trace with planning tokens (strategic grams) highlighted, illustrating deduction, branching, and backtracing.
HICRA: Hierarchy-Aware Credit Assignment
Prevailing RL algorithms such as GRPO apply optimization pressure indiscriminately across all tokens, diluting the learning signal. HICRA addresses this by amplifying the advantage for planning tokens during policy updates:
A^i,tHICRA={A^i,t+α⋅∣A^i,t∣if t∈Si A^i,totherwise
where Si indexes planning tokens and α controls amplification. This anisotropic credit assignment reshapes the policy update to prioritize strategic exploration, accelerating the discovery and reinforcement of effective reasoning patterns.
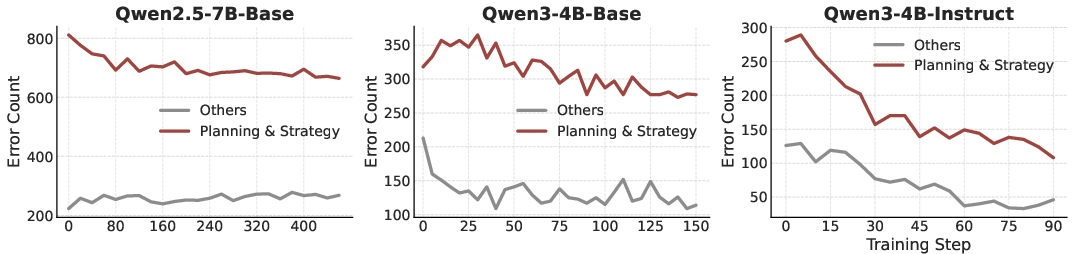
Figure 4: RL training primarily reduces planning/strategy errors, confirming that strategic bottleneck correction drives reasoning improvements.
Semantic Entropy: A Reliable Compass for Strategic Exploration
The paper demonstrates that aggregate token-level entropy is dominated by execution tokens and can mislead practitioners regarding exploration dynamics. Semantic entropy, computed over strategic grams, accurately tracks the diversity of high-level strategies and correlates with validation accuracy.
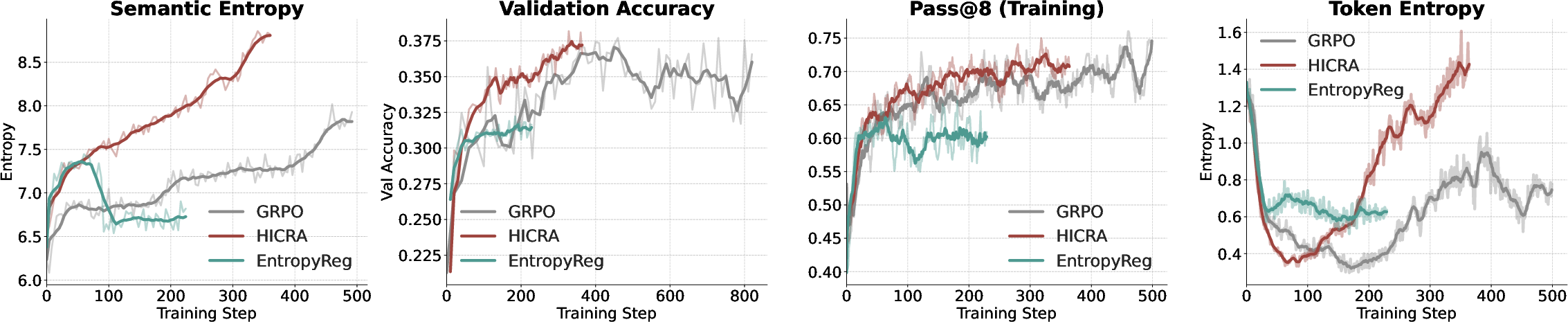
Figure 5: HICRA boosts semantic entropy and validation accuracy, outperforming entropy regularization which increases token-level entropy but fails to improve accuracy.
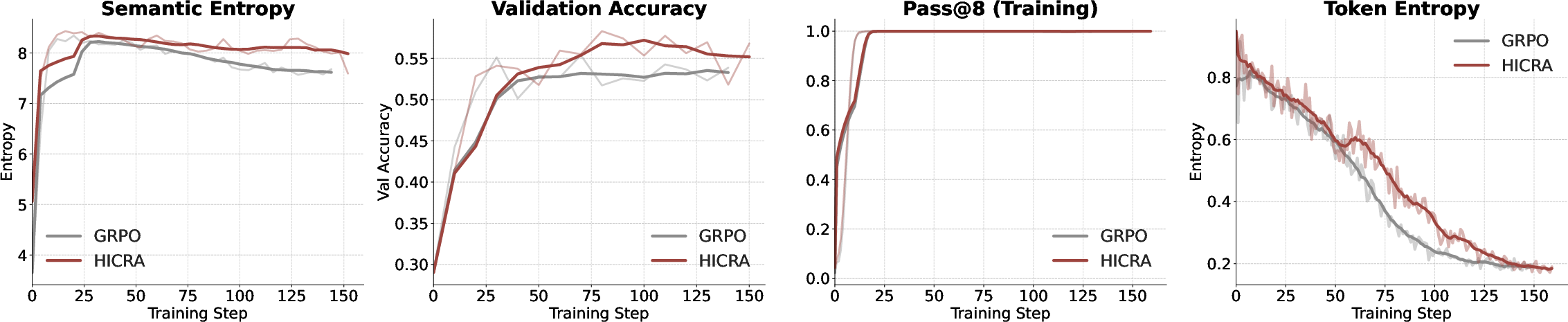
Figure 6: On MiMO-VL-Instruct-7B, semantic entropy remains predictive of validation accuracy, while token entropy collapses and Pass@8 saturates.
Experimental Results
Extensive experiments on mathematical and multimodal reasoning benchmarks show that HICRA consistently outperforms GRPO and other baselines across diverse model families. Gains are most pronounced when the base model possesses sufficient procedural reliability, confirming the dependency of HICRA's effectiveness on a solid low-level foundation.
Analysis and Limitations
The reduction in strategic errors during RL training substantiates the claim that mastery of high-level planning is the primary driver of reasoning improvements. HICRA's targeted exploration yields higher semantic entropy and superior accuracy compared to indiscriminate entropy regularization. However, when applied to models lacking procedural competence, HICRA may be counterproductive, highlighting the need for adaptive hierarchical methods.
Planning Tokens vs. High-Entropy Tokens
The functional definition of planning tokens via SGs is shown to be more precise than entropy-based proxies. While most planning tokens exhibit high entropy, the majority of high-entropy tokens are not planning tokens, underscoring the importance of semantic function over statistical variation.
Implications and Future Directions
The findings suggest several avenues for advancing RL in LLMs:
- Action Granularity: Moving beyond token-level actions to semantic units or reasoning steps could align optimization with cognitive processes.
- Adaptive Hierarchical Methods: Dynamically shifting optimization pressure between procedural and strategic components based on model diagnostics.
- Process-Oriented Rewards: Decoupling planning and execution in reward models to enable finer-grained credit assignment.
- Generalization: Extending the reasoning hierarchy framework to domains beyond mathematics, such as code generation and agentic tool use.
Conclusion
The paper provides a unified framework for understanding RL-induced reasoning improvements in LLMs, identifying a two-phase dynamic and a strategic bottleneck. HICRA demonstrates that targeted credit assignment on planning tokens yields superior reasoning performance. Semantic entropy emerges as a robust metric for strategic exploration. The work motivates a paradigm shift toward hierarchical, adaptive, and process-oriented RL algorithms for LLMs, with broad implications for future research in AI reasoning systems.

