- The paper introduces a hybrid generative pipeline that starts with 360° panoramic proxy generation and employs semantically layered 3D mesh reconstruction.
- It integrates techniques such as LLM-enhanced text conditioning, depth estimation, and cross-layer alignment to achieve state-of-the-art visual coherence and geometric consistency.
- The system demonstrates significant improvements for VR, simulation, and game development by producing real-time, interactive, and exportable 3D worlds.
HunyuanWorld 1.0: A Framework for Immersive, Explorable, and Interactive 3D World Generation from Text or Images
Introduction and Motivation
HunyuanWorld 1.0 addresses the challenge of generating high-fidelity, explorable, and interactive 3D worlds from either textual descriptions or single images. The framework is motivated by the limitations of prior approaches: video-based methods offer visual diversity but lack true 3D consistency and are computationally inefficient for rendering, while 3D-based methods provide geometric consistency but are constrained by limited training data and inefficient scene representations. HunyuanWorld 1.0 proposes a hybrid solution, leveraging panoramic images as 360° world proxies and introducing a semantically layered 3D mesh representation to enable structured, interactive, and exportable 3D worlds.

Figure 1: HunyuanWorld 1.0 enables generation of immersive, explorable, and interactive 3D worlds from text or image inputs, supporting mesh export and object-level manipulation.
System Architecture and Pipeline
The core architecture of HunyuanWorld 1.0 is a staged generative pipeline that integrates 2D generative modeling with 3D scene reconstruction. The process begins with the generation of a panoramic image (serving as a world proxy) conditioned on either text or image input. This panorama is then decomposed into semantic layers (sky, background, and object layers) using an agentic world layering module. Each layer undergoes depth estimation and alignment, followed by mesh-based 3D reconstruction. The resulting layered 3D mesh supports object disentanglement, enabling interactive manipulation and compatibility with standard graphics pipelines.
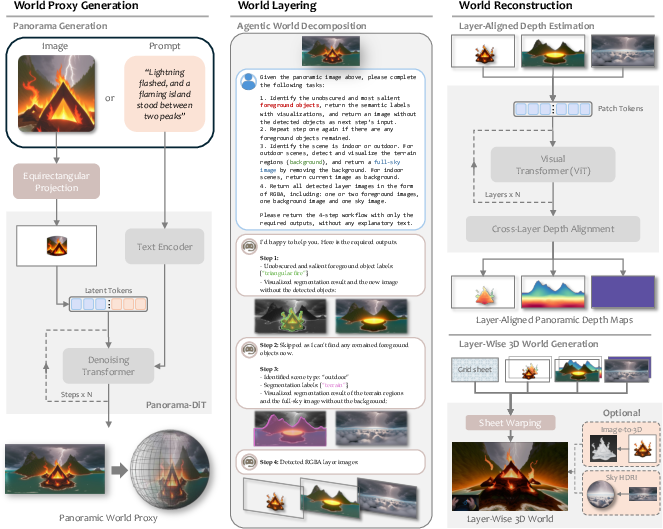
Figure 2: The architecture of HunyuanWorld 1.0 for 3D world generation, illustrating the staged process from input to layered 3D mesh output.
Panoramic Proxy Generation
- Text-to-Panorama: Text prompts are enhanced via LLMs for alignment with training data, then used to condition a DiT-based diffusion model (Panorama-DiT) to generate 360° panoramas.
- Image-to-Panorama: Input images are unprojected into panoramic space using estimated camera intrinsics, and the resulting partial panorama is completed by the diffusion model, conditioned on both the image and a scene-aware prompt.
Boundary artifacts are mitigated through elevation-aware augmentation and circular denoising, ensuring geometric and semantic continuity across panorama boundaries.
Panoramic Data Curation
A dedicated pipeline curates high-quality panoramic data from commercial, open, and synthetic sources. Automatic and manual filtering ensures removal of artifacts and misalignments. Captioning is performed in three stages: re-captioning for detail, LLM-based distillation for hierarchical prompts, and human verification for semantic fidelity.
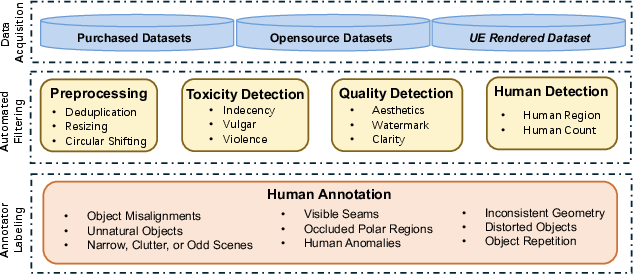
Figure 3: The panoramic data curation pipeline, including acquisition, quality filtering, and multi-stage captioning.
Agentic World Layering
Semantic object recognition is performed using VLMs, followed by object detection and segmentation (e.g., Grounding DINO, ZIM) with circular padding to handle panorama boundaries. Layer decomposition separates objects, background, and sky, with an autoregressive inpainting process for occluded regions. Object removal datasets are used to fine-tune the completion model for realistic layer synthesis.
Layer-wise 3D Reconstruction
Depth estimation is performed per layer, with cross-layer alignment to ensure geometric consistency. Foreground objects are reconstructed via direct mesh projection or by generating full 3D assets using image-to-3D models (e.g., Hunyuan3D). Background and sky layers are reconstructed via sheet warping, with adaptive depth compression and HDRI support for sky rendering. The framework also supports 3D Gaussian Splatting as an alternative representation.
Long-Range World Extension
To enable exploration beyond the initial panorama, a video-based view completion model (Voyager) is integrated. Voyager uses a world-consistent video diffusion model with a point cloud cache, supporting arbitrary camera trajectories and long-range scene extension while maintaining spatial coherence.
System Optimization
Mesh storage is optimized via dual strategies: XAtlas-based decimation and UV parameterization for offline use, and Draco compression for web deployment, achieving up to 90% size reduction. Model inference is accelerated using TensorRT, intelligent caching, and multi-GPU parallelization, supporting real-time generation without compromising visual quality.
Experimental Results
Panorama Generation
HunyuanWorld 1.0 demonstrates superior performance in both image-to-panorama and text-to-panorama tasks, outperforming Diffusion360, MVDiffusion, PanFusion, and LayerPano3D in BRISQUE, NIQE, Q-Align, and CLIP-based alignment metrics. Qualitative results show improved visual coherence and semantic fidelity.

Figure 4: Image-to-panorama generation results by HunyuanWorld 1.0.

Figure 5: Text-to-panorama generation results by HunyuanWorld 1.0.

Figure 6: Qualitative comparison for image-to-panorama generation (World Labs).

Figure 7: Qualitative comparison for image-to-panorama generation (Tanks and Temples).

Figure 8: Qualitative comparison for text-to-panorama generation (case 1).

Figure 9: Qualitative comparison for text-to-panorama generation (case 2).
3D World Generation
For both image-to-world and text-to-world tasks, HunyuanWorld 1.0 achieves state-of-the-art results, surpassing WonderJourney, DimensionX, LayerPano3D, and Director3D in all quantitative metrics. The generated 3D worlds exhibit high visual fidelity, geometric consistency, and strong semantic alignment with input conditions.

Figure 10: Visual results of text-to-world generation by HunyuanWorld 1.0.
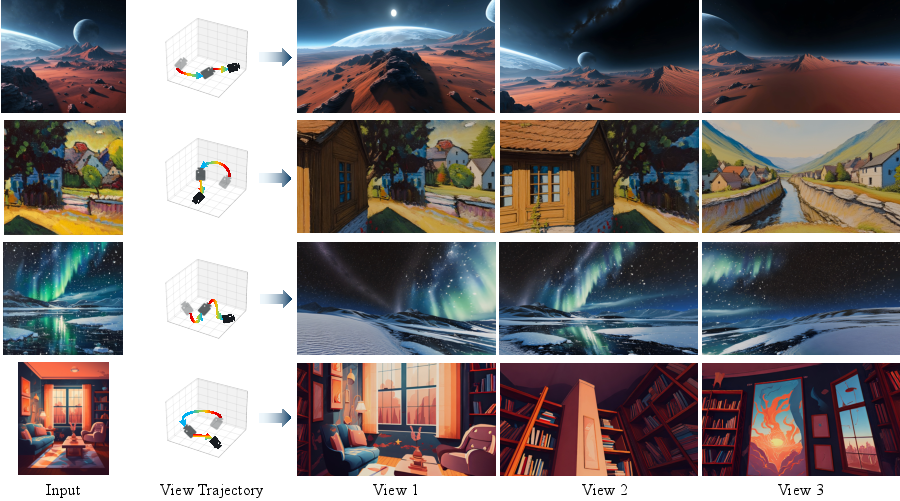
Figure 11: Visual results of image-to-world generation by HunyuanWorld 1.0.

Figure 12: Qualitative comparison for image-to-world generation.

Figure 13: Qualitative comparison for text-to-world generation.
Applications and Implications
HunyuanWorld 1.0 supports a broad range of applications:

Figure 14: Overview of HunyuanWorld 1.0 applications, including VR, simulation, game development, and object interaction.
- Virtual Reality: Generation of 360° immersive environments for VR platforms, with seamless omnidirectional browsing.
- Physical Simulation: Exportable 3D meshes compatible with physics engines for simulation tasks.
- Game Development: Diverse, style-rich 3D worlds exportable to standard engines (Unity, Unreal).
- Object Interaction: Disentangled object representations enable precise manipulation and interaction within generated scenes.
Theoretical and Practical Implications
The introduction of a semantically layered 3D mesh representation, combined with panoramic world proxies, addresses the data scarcity and representation inefficiency in 3D world generation. The hybrid approach leverages the diversity and scalability of 2D generative models while ensuring geometric consistency and interactivity in 3D. The system's modularity and export capabilities facilitate integration into existing graphics and simulation pipelines.
Notably, the paper demonstrates strong numerical improvements over prior methods in both visual quality and semantic alignment, and claims robust generalization across diverse scene types and artistic styles. The disentanglement of object representations is a significant advancement for interactive applications.
Future Directions
Potential future developments include scaling the framework to larger and more diverse datasets, improving the fidelity of object-level reconstruction, and extending the system to support dynamic scenes and real-time user interaction. Further research may explore tighter integration with LLMs for more nuanced scene understanding and control, as well as optimization for edge deployment.
Conclusion
HunyuanWorld 1.0 presents a comprehensive framework for generating immersive, explorable, and interactive 3D worlds from text or image inputs. By unifying panoramic 2D generation with semantically layered 3D reconstruction, the system achieves state-of-the-art performance and broad applicability. The approach sets a new baseline for world-level 3D content creation and provides a foundation for future research in generative 3D modeling, interactive simulation, and virtual environment synthesis.