- The paper demonstrates that integrating pre-trained LLM tutors with RL accelerates convergence, significantly boosting performance in Deep Q-Networks.
- The study introduces a student-teacher architecture where RL agents consult LLM tutors with a decaying probability, streamlining training in sparse reward settings.
- Results indicate that larger LLMs, such as DeepSeek-R1, offer modest tutoring benefits, highlighting the trade-offs between model size and computational cost.
Accelerating Reinforcement Learning Algorithms Convergence using Pre-trained LLMs as Tutors With Advice Reusing
This paper explores the integration of pre-trained LLMs as tutors within Reinforcement Learning (RL) frameworks, aiming to accelerate the convergence of RL algorithms. It introduces a student-teacher architecture which facilitates RL training through structured guidance from LLMs, bringing forth insights into the dynamics of LLM-assisted learning in complex environments.
Introduction
Reinforcement Learning (RL) has proven effective in solving complex sequential decision-making problems across various domains, including autonomous systems and game theory. However, despite its successes, RL typically faces slow convergence, particularly in environments with sparse rewards where extensive computational resources are required for training. Traditional techniques such as reward shaping and curriculum learning aim to mitigate this challenge but require domain-specific expertise and often lack general applicability.
LLMs, such as GPT and DeepSeek, have demonstrated extraordinary capabilities in natural language processing tasks, suggesting the possibility of leveraging them as interactive tutors to enhance RL training. By utilizing LLM-generated advice, RL agents can potentially achieve faster convergence without necessitating modifications to the underlying algorithms. This paper examines the effectiveness of LLM tutoring and advice reusing mechanisms in accelerating RL convergence across diverse environments and algorithmic settings.
Methods and Materials
Student-Teacher Architecture
The student-teacher architecture involves RL agents operating as students under the guidance of pre-trained LLM tutors. The decision to consult the LLM for guidance is governed by a probability that decays over the training period, reducing the reliance on the LLM as the agent's learning progresses.
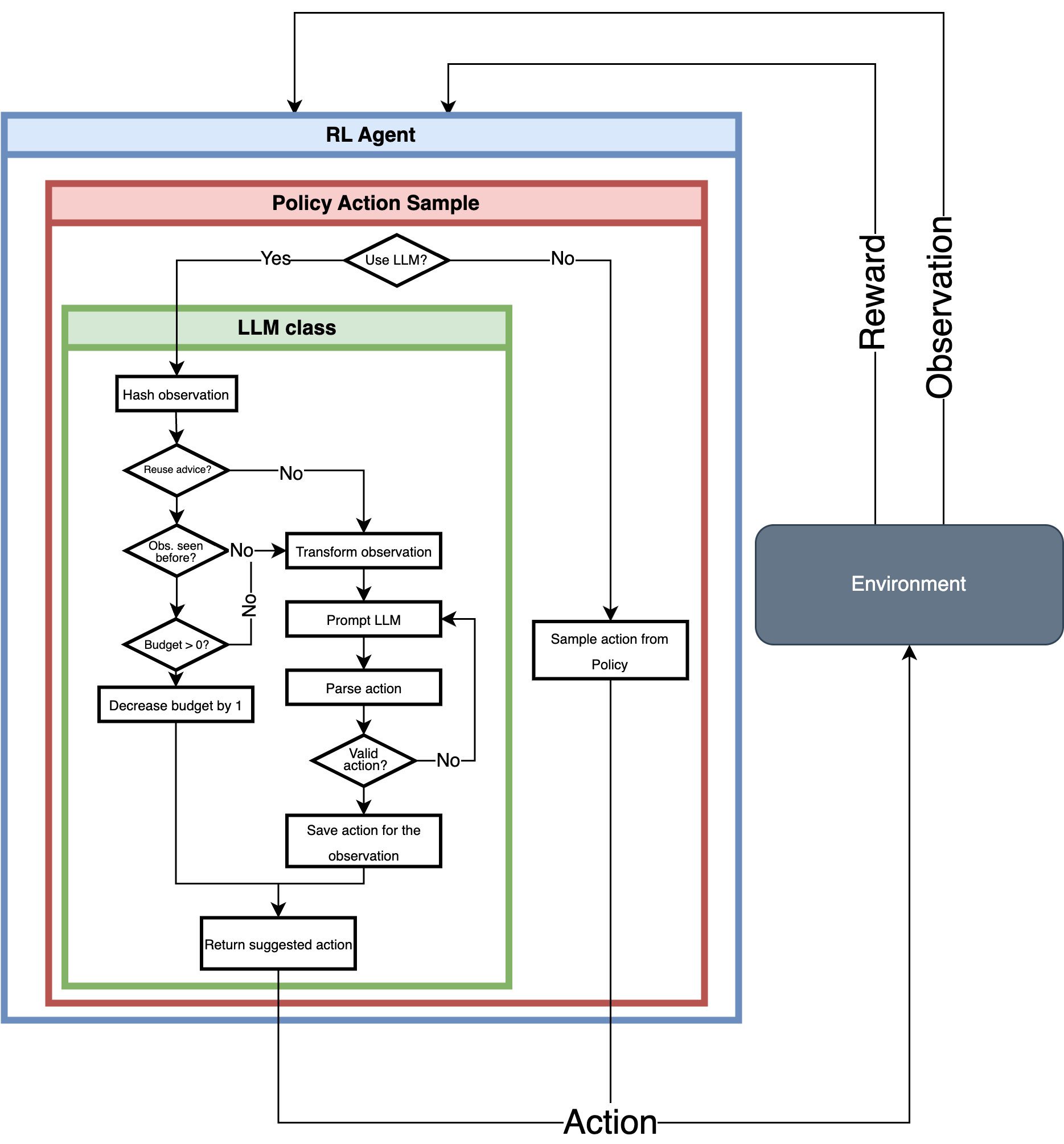
Figure 1: A schematic view of student-teacher structure for RL and LLM. When the RL agent selects an action to execute in the environment, it has the opportunity to consult the LLM tutor. The decision to do so is guided by a probability P, continuously decaying during the training phase.
Reinforcement Learning Algorithms
Three RL algorithms were tested: Deep Q-Networks (DQN), Proximal Policy Optimization (PPO), and Advantage Actor-Critic (A2C). These algorithms represent distinct learning strategies and help in assessing the influence of LLM tutoring across varying methodologies.
LLMs
Three open-source LLMs—DeepSeek-R1, Llama3.1, and Vicuna—were employed as tutors. These models vary in size and reasoning capabilities, providing insights into the correlation between LLM attributes and their efficacy as RL guides.
Results
The integration of LLM tutoring significantly accelerated the convergence of RL models across different environments. The DQN algorithm, when combined with LLM guidance, exhibited the most substantial improvements in convergence speed and performance across environments such as Blackjack and Snake.
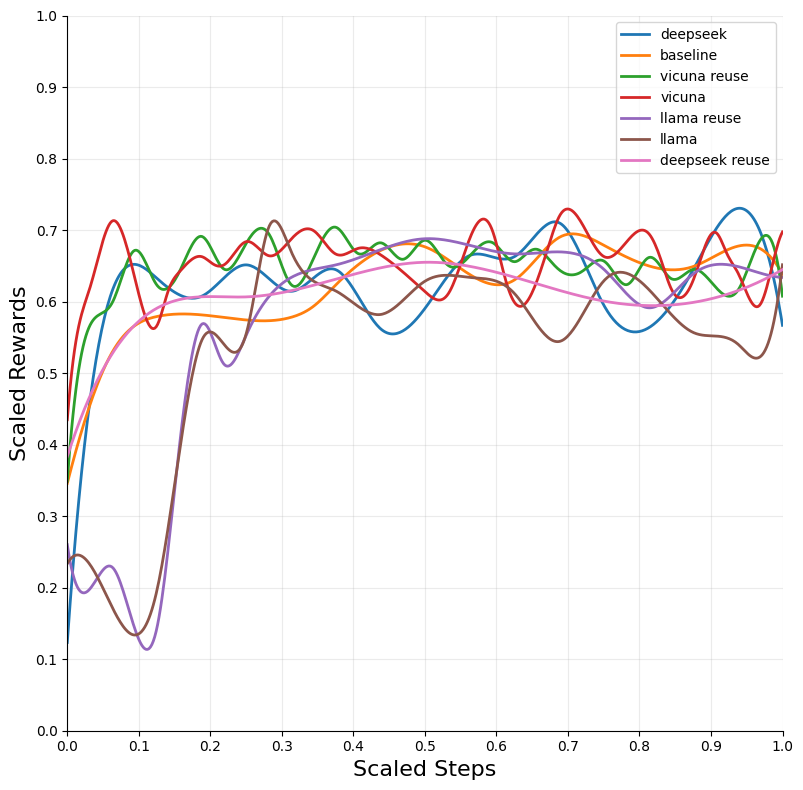
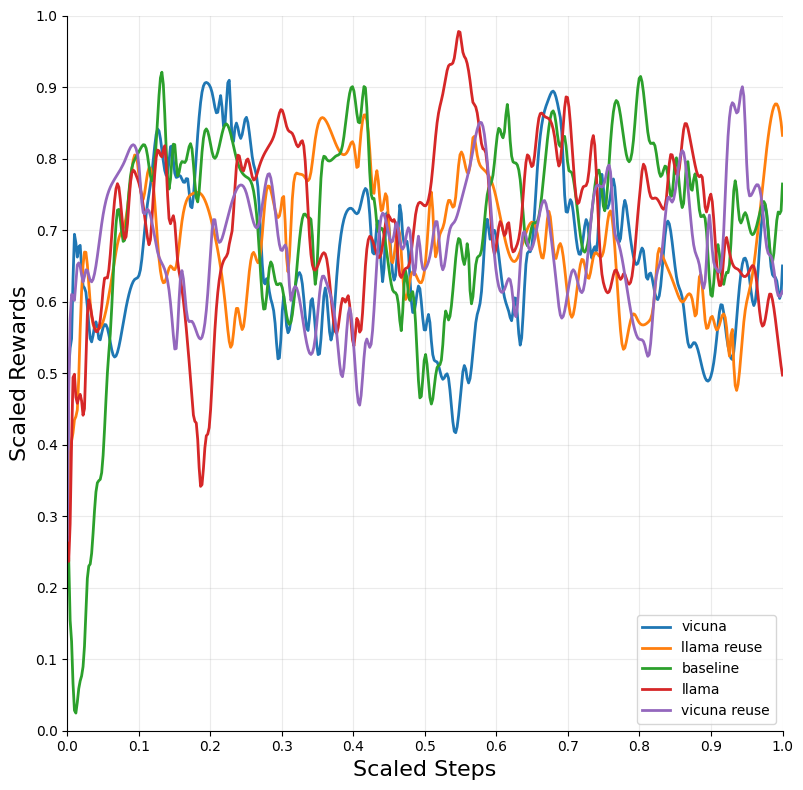
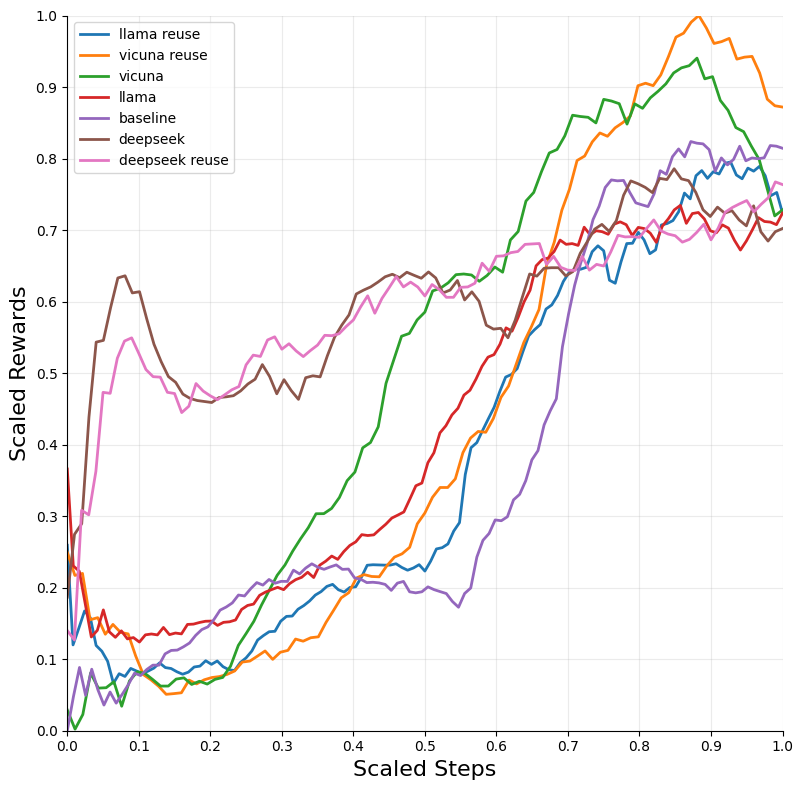
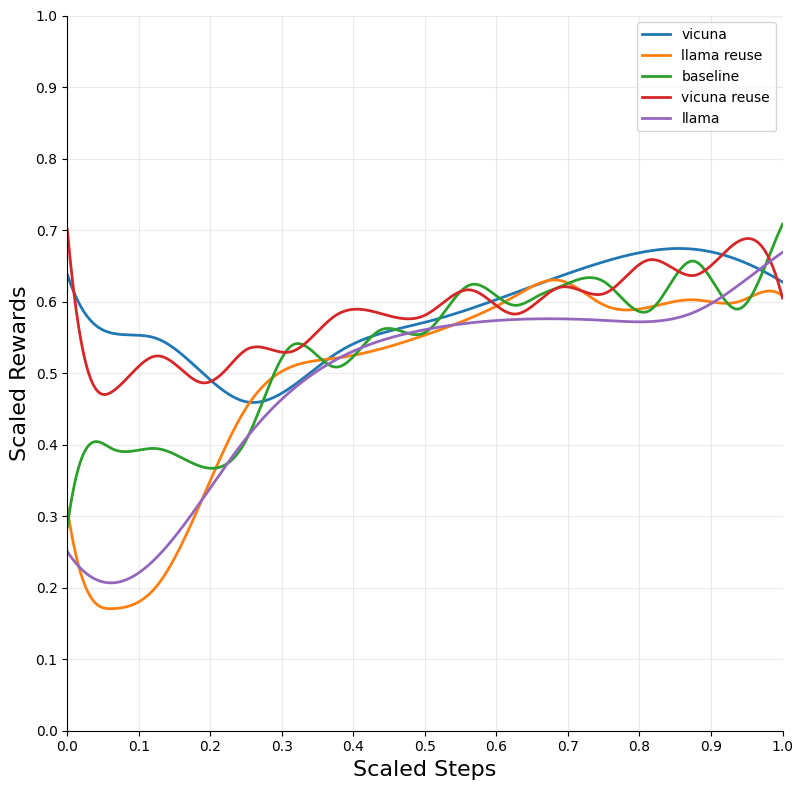
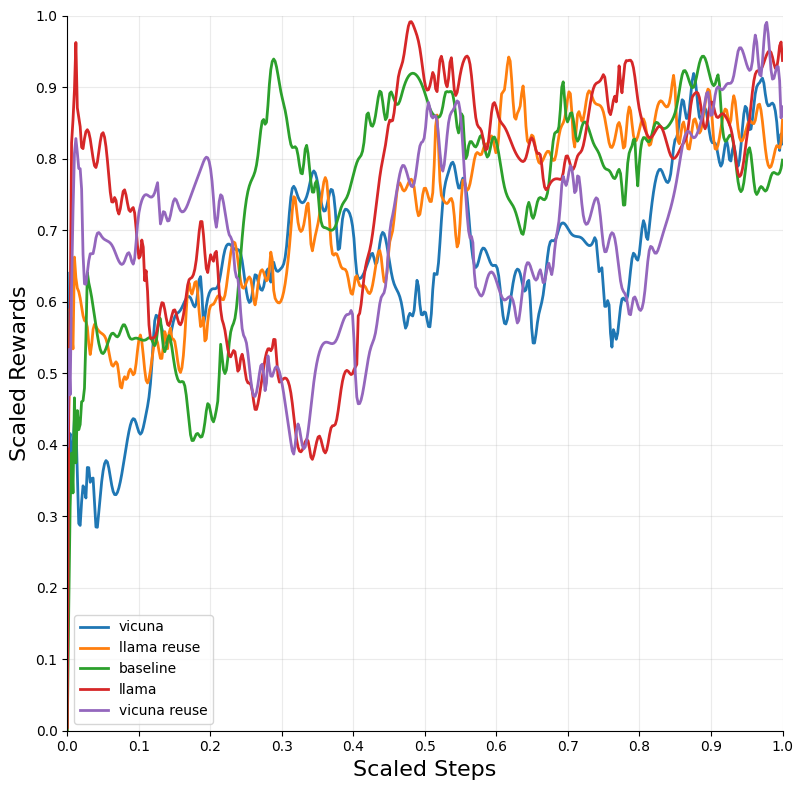
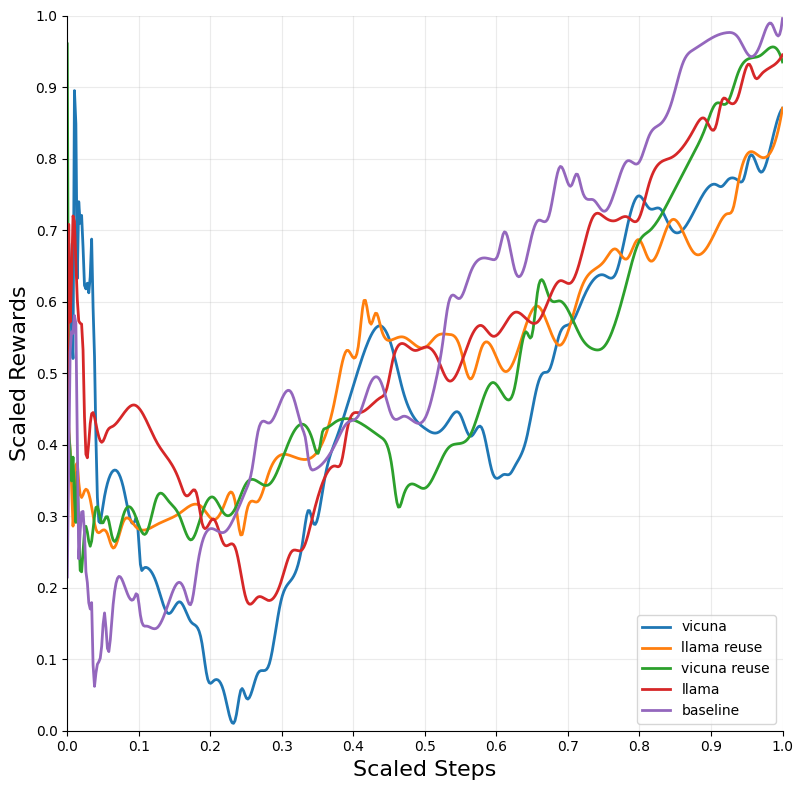
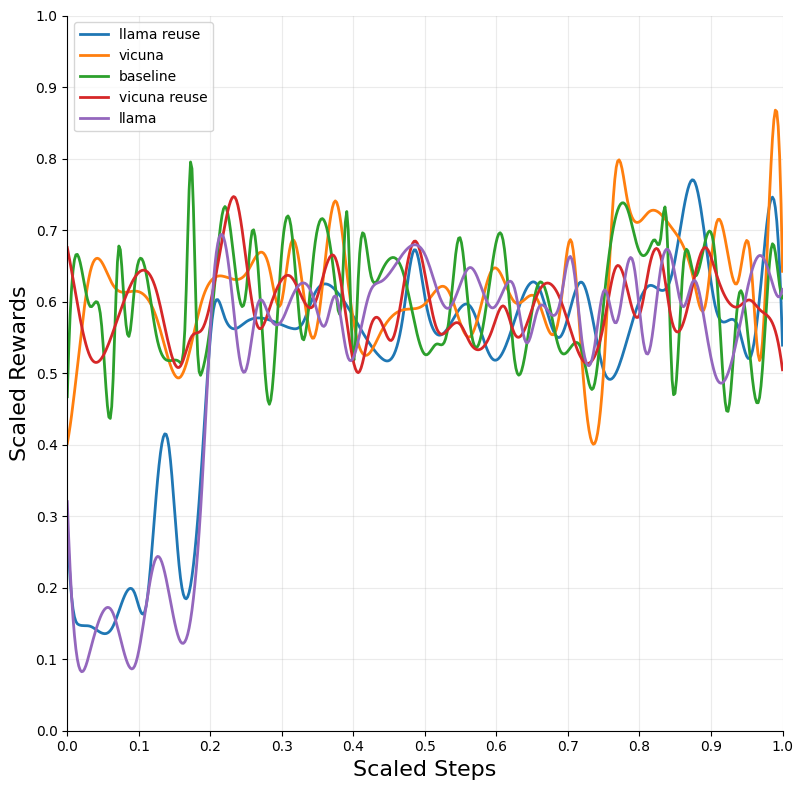
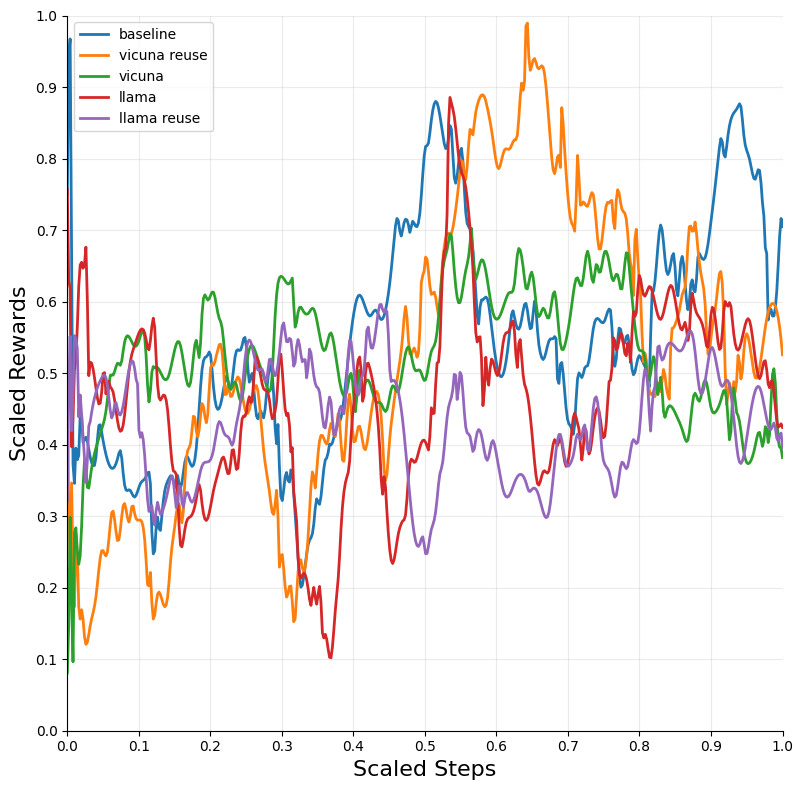
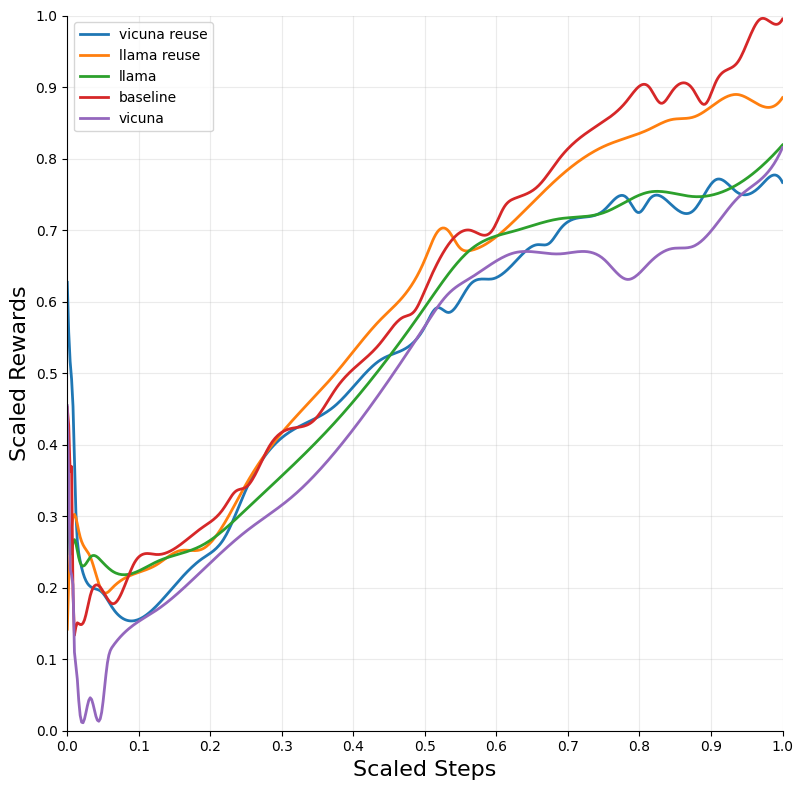
Figure 2: Blackjack — DQN.
Influence of LLM Attributes
Larger LLM models, such as DeepSeek-R1, tended to outperform smaller ones, hinting at a positive correlation between LLM size and tutoring effectiveness. However, this correlation was modest and should be considered with caution due to computational limitations and the stochastic nature of LLM outputs.
Discussion
The integration of LLM tutors presents a promising avenue for reducing RL training time, especially in complex environments where traditional methods falter. LLMs offer a unique capability to guide agents through sparse reward landscapes, minimizing the need for extensive exploration.
However, the practical implementation of LLM-tutored RL also introduces challenges, such as increased computational overhead due to LLM inference times and the need for robust prompt engineering to ensure consistent and valid advice. Future research could explore advanced advice reuse strategies, optimized LLM configurations, and the application of cloud-hosted LLMs for potentially higher-quality guidance.
Conclusion
LLM tutoring offers substantial improvements in RL convergence speeds while maintaining optimal performance levels. The promising results suggest expanding research into leveraging LLMs for more effective and efficient RL training across varying domains. Despite the initial overhead, the long-term benefits make this a compelling approach for enhancing advanced RL systems.

