- The paper introduces PiCSAR, a training-free method that enhances reasoning tasks in LLMs and LRMs by selecting candidate chains via joint log-likelihood scoring.
- It decomposes confidence into reasoning and answer components, using best-of-n sampling and length normalization to optimize candidate selection.
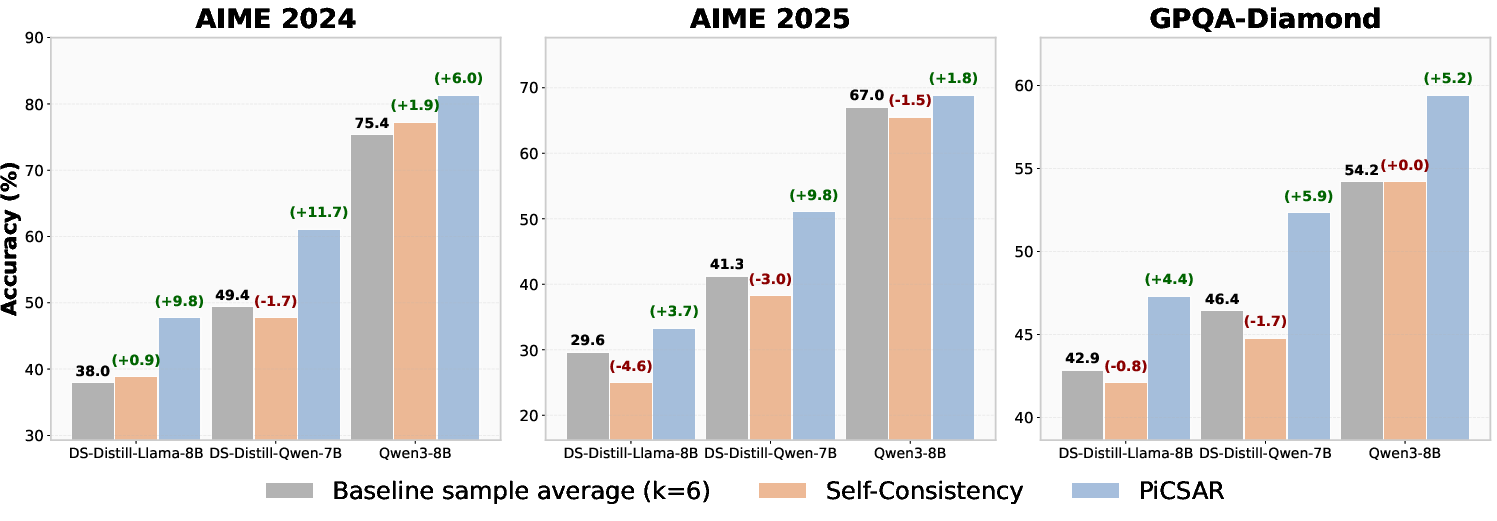
- Experimental results on datasets like MATH500 show improved sampling efficiency and accuracy over methods such as self-consistency.
Overview of "PiCSAR: Probabilistic Confidence Selection And Ranking"
The paper introduces PiCSAR (Probabilistic Confidence Selection And Ranking), a novel method aimed at enhancing the performance of LLMs and large reasoning models (LRMs) in reasoning tasks. This method is designed to optimize the selection of reasoning chains and answers through a probabilistic approach that maximizes joint log-likelihoods, thus improving the ability to identify correct reasoning chains without training external models.
Methodology
PiCSAR operates by evaluating multiple candidate solutions generated via best-of-n sampling, selecting candidates based on the joint log-likelihood of reasoning traces and answers. The method breaks down this joint log-likelihood into two key metrics: reasoning confidence and answer confidence.
Scoring Function
The proposed scoring function calculates the joint conditional probability:
argr,ymaxp(r,y∣x)=argr,ymaxp(y∣r,x)⋅p(r∣x)
This decomposition results in a scoring formula defined as:
Score(r,y)=logp(r∣x)+logp(y∣r,x)
Where:
- logp(r∣x) is the reasoning confidence.
- logp(y∣r,x) is the answer confidence.
Implementation Steps
PiCSAR involves generating candidate reasoning chains, scoring them via the aforementioned formula, and selecting the pair with the highest score. Two variants are introduced: the standard PiCSAR and the length-normalized PiCSAR-N, which adjusts the reasoning confidence by chain length to prevent bias toward shorter responses.
Experimental Results
PiCSAR was tested on multiple LLMs and LRMs across various datasets, demonstrating significant performance boosts compared to existing methods like self-consistency and Universal Self-Consistency (USC).
Advantages of PiCSAR
- Training-Free: PiCSAR eliminates the need for external reward models, reducing computational overhead and susceptibility to distribution shifts.
- Scalable and Efficient: By exploiting the natural decomposition of confidence terms, PiCSAR effectively scales across different model architectures and sizes.
- Flexible Confidence Evaluation: The model generation and evaluation processes can be decoupled, allowing different models to perform these tasks, which enhances flexibility while maintaining performance stability.
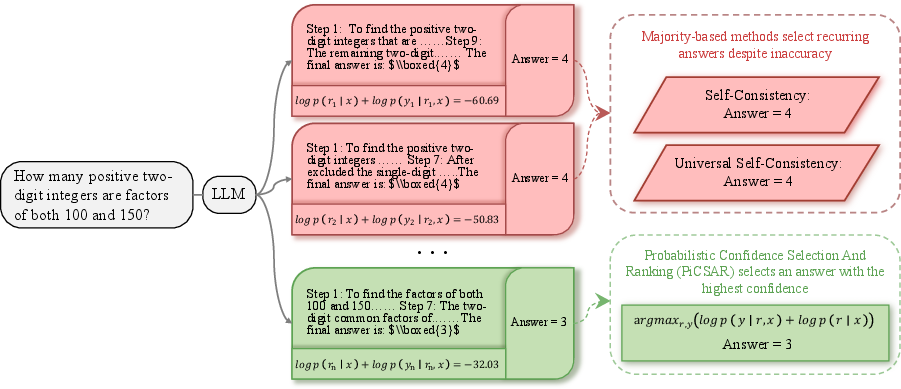
Figure 2: PiCSAR selects the most likely reasoning trace r and answer y by jointly maximising their log-likelihoods logp(r∣x) and logp(y∣r,x).
Future Work and Implications
The findings suggest that further improvements in LLM reasoning can be achieved by refining selection methods and optimizing confidence assessments. PiCSAR opens new avenues for effectively leveraging probabilistic frameworks in complex reasoning tasks, promising enhancements in model accuracy without additional training costs. The adaptability and efficiency of PiCSAR make it a favorable choice for deployment in diverse practical applications, potentially broadening the scope of reasoning capabilities in future AI systems.
In summary, PiCSAR presents a compelling approach for improving reasoning task performance by efficiently utilizing probabilistic confidence metrics, offering a paradigm shift towards more effective reasoning in AI models.