- The paper introduces a formal framework delineating three modes—skill denoising, selection, and generalization—for models to surpass individual expert performance.
- It employs a synthetic knowledge graph and controlled experiments to demonstrate that low-temperature sampling and data diversity significantly boost query accuracy.
- The findings provide actionable guidance for optimizing training data and model architectures, emphasizing compositional examples and chain-of-thought reasoning for multi-hop tasks.
Introduction and Motivation
The paper "A Taxonomy of Transcendence" (2508.17669) provides a formal and empirical framework for understanding how LMs trained on data generated by multiple human experts can surpass the skill level of any individual expert. The authors introduce three distinct modes of transcendence—skill denoising, skill selection, and skill generalization—each corresponding to specific properties of the training data and the structure of expert knowledge. The work leverages a synthetic knowledge graph setting to systematically analyze and validate the conditions under which transcendence occurs, emphasizing the critical role of data diversity and compositional structure.
The taxonomy is grounded in a rigorous formalism, extending prior work on generative model transcendence (Zhang et al., 2024). The authors define experts as conditional probability functions over input-output spaces, with each expert possessing a unique distribution over contexts and a reward function quantifying skill. Transcendence is achieved when a model trained on the mixture of expert data attains higher expected reward on a test distribution than any individual expert.
Skill Denoising
Skill denoising arises when experts make independent, uncorrelated errors on a shared input distribution. The model can outperform all experts by averaging out their mistakes, analogous to the "wisdom of crowds." Low-temperature sampling is shown to be essential for extracting the modal prediction and denoising errors.
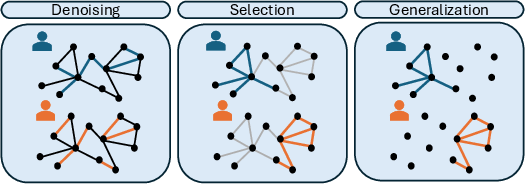
Figure 1: Expert distributions in the knowledge-graph setting, illustrating denoising, selection, and generalization regimes via edge coverage and sampling probabilities.
Skill Selection
Skill selection occurs when experts have domain-specific expertise, i.e., their input distributions are non-overlapping or biased toward certain contexts. Transcendence is possible if the probability of an expert generating data for a context is positively correlated with their skill on that context. The paper provides a formal theorem and proof for the two-expert case, establishing the necessity of this correlation for transcendence.
Skill Generalization
Skill generalization is the most challenging regime, where the test inputs are outside the support of any expert's training distribution. Here, the model must compose knowledge from multiple experts by leveraging shared latent representations and compositional structure. The authors analyze this setting using two-hop fact completion in a knowledge graph, demonstrating that compositional inductive bias enables the model to answer queries that no expert can.
Synthetic Knowledge Graph Experimental Framework
The empirical analysis is conducted using a synthetic knowledge graph populated with fictional entities and relations, ensuring no overlap with pretraining data. Experts are assigned clusters of edges (facts), with controlled coverage and error rates. Training samples are generated as paragraphs describing entities, and evaluation is performed via query completion accuracy on one-hop and two-hop facts.
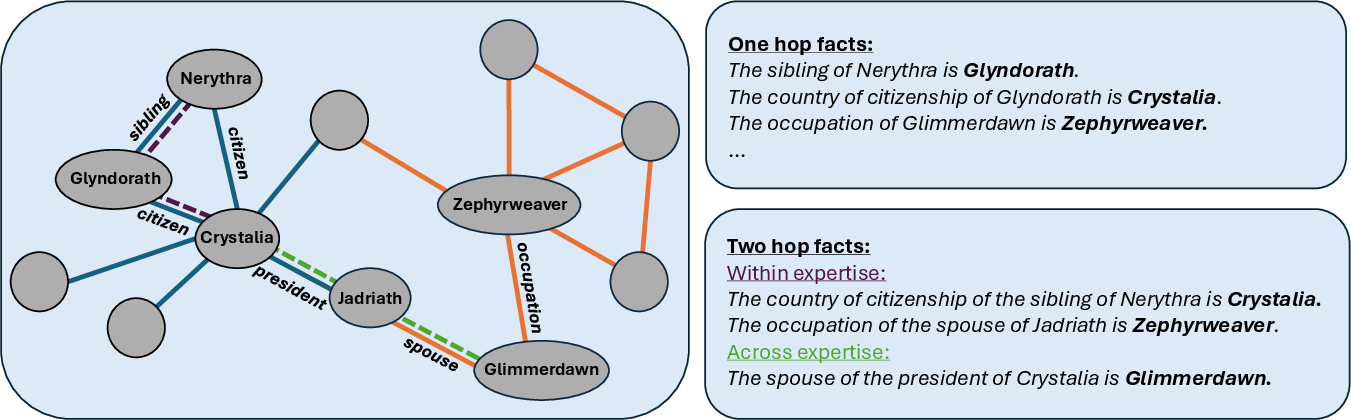
Figure 2: Visualization of the knowledge graph with expert-specific edge coverage and example entities, highlighting within- and across-expertise two-hop facts.
Empirical Results
Skill Denoising Experiments
Models trained on data from noisy experts (with independent errors) achieve query completion accuracy far exceeding individual expert coverage, especially with large numbers of experts and low-temperature decoding. For instance, with expert coverage as low as 0.2, the model attains over 80% accuracy when trained with 100 experts.
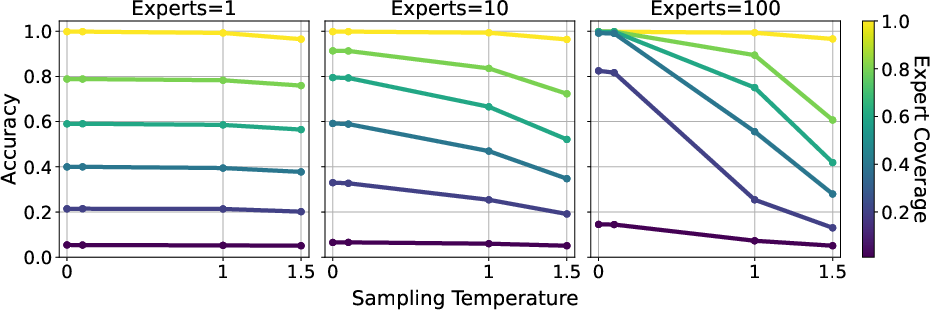
Figure 3: Low-temperature sampling enables the model to transcend expert skill level in the denoising regime.
Skill Selection Experiments
By varying the parameter α (controlling the likelihood of experts commenting within their expertise), the authors show that models can achieve near-perfect accuracy even when individual expert coverage is low, provided that experts predominantly generate data within their domains. Increasing the number of experts and α both improve performance.
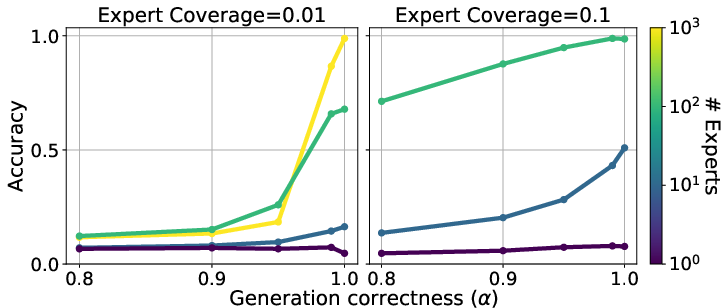
Figure 4: Query accuracy as a function of α and expert coverage, demonstrating the impact of expertise-focused data generation.
Skill Generalization Experiments
The two-hop fact completion task reveals that accuracy on unseen across-expertise queries increases linearly with the number of within-expertise two-hop examples in the training set. The model achieves 34% accuracy on across-expertise two-hop facts (vs. a 20% baseline) when trained on all available within-expertise compositions. Data diversity in phrasing further boosts performance, and allowing chain-of-thought (CoT) reasoning raises accuracy above 60%.
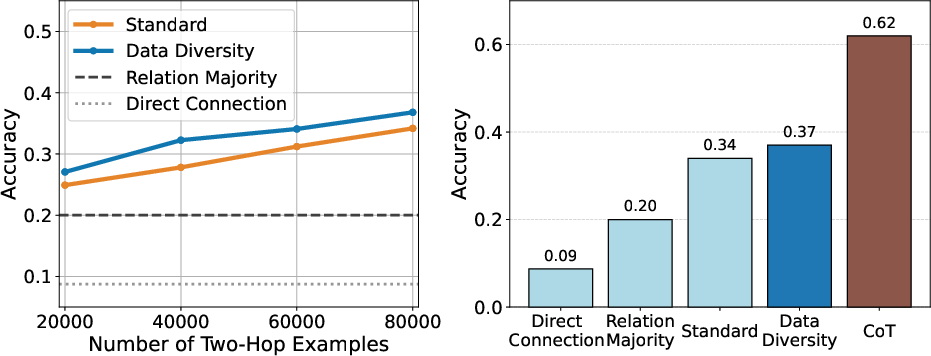
Figure 5: Left: Across-expertise two-hop accuracy vs. number of within-expertise training examples. Right: Comparison of methods for across-expertise generalization.
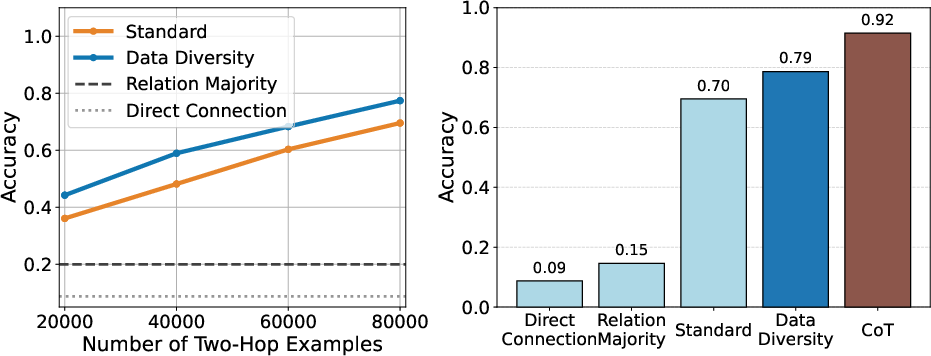
Figure 6: Left: Training samples vs. within-expertise two-hop accuracy. Right: Method comparison for within-expertise query accuracy.
Mechanistic Insights and Theoretical Implications
The analysis in the appendices formalizes the conditions under which compositional generalization is favored by a simplicity-biased learner. When the number of compositional training examples exceeds the number of atomic facts plus a fixed compositional overhead, the model prefers a generalizing solution over memorization. This aligns with information-theoretic arguments for inductive bias toward low-complexity solutions [(Goldblum et al., 2023), cs/0001002].
The findings also connect to the compositionality gap literature (Press et al., 2022), showing that scaling model size alone does not close the gap; instead, data diversity and explicit compositional training are required. The results on CoT echo prior work on reasoning and knowledge manipulation (Allen-Zhu et al., 2023, Wei et al., 2022).
Practical Implications and Future Directions
The taxonomy provides actionable guidance for dataset design and model training:
- Skill denoising: Maximize expert diversity and error independence; use low-temperature decoding.
- Skill selection: Ensure experts generate data predominantly within their expertise; increase the number and diversity of experts.
- Skill generalization: Augment training with diverse compositional examples and phrasing; leverage CoT prompting for multi-hop reasoning.
The controlled synthetic setting isolates key phenomena but is limited in ecological validity. Future work should extend these analyses to real-world corpora, explore additional transcendence modes (e.g., skill discovery), and develop principled data augmentation strategies for compositional generalization.
Conclusion
This paper establishes a rigorous taxonomy of transcendence, delineating the conditions under which LMs can outperform their training experts via denoising, selection, and generalization. The empirical and theoretical results underscore the centrality of data diversity and compositional structure in enabling transcendent capabilities. The framework and findings have significant implications for the design of training data, model architectures, and evaluation protocols in the development of generalist AI systems.