- The paper demonstrates that carefully curated and diverse synthetic data can outperform natural data, achieving up to 7.7× faster convergence in LLM training.
- It employs both generator-driven and source rephrasing paradigms, with rigorous ablations highlighting the role of information density and stylistic diversity.
- Efficient use of small-scale models and scalable infrastructure enables BeyondWeb to breach the data wall and democratize high-quality LLM pretraining.
BeyondWeb: Systematic Advances in Synthetic Data for Trillion-Scale LLM Pretraining
Introduction
The "BeyondWeb" paper presents a comprehensive empirical and methodological study of synthetic data for LLM pretraining, culminating in the introduction of the BeyondWeb framework. The work addresses the data wall encountered in web-scale pretraining, where further scaling of natural data yields diminishing returns, and systematically investigates the mechanisms, design choices, and scaling properties of synthetic data generation. The authors provide strong evidence that carefully curated, diverse, and information-dense synthetic data can not only match but surpass the performance of models trained on natural data, and that naive synthetic data strategies are insufficient. The study is notable for its rigorous ablations, multi-scale experiments, and clear articulation of the trade-offs and requirements for effective synthetic data curation.
Synthetic Data Paradigms: Generator-Driven vs. Source Rephrasing
The paper distinguishes two principal paradigms for synthetic data generation:
- Generator-Driven: Large LLMs generate data de novo, encapsulating their parametric knowledge. This approach, exemplified by Cosmopedia and the Phi family, can distill knowledge into compact forms but is limited by generator cost, coverage, and risk of model collapse.
- Source Rephrasing: Smaller LLMs rephrase existing web data into higher-quality, task-aligned formats (e.g., Q&A, instructional passages). This paradigm, as in WRAP and Nemotron-CC, is more scalable and cost-effective, and has become the dominant industry practice.
The authors argue, and empirically demonstrate, that source rephrasing can match or exceed generator-driven methods in downstream performance, especially when diversity and information density are prioritized.
The BeyondWeb Framework
BeyondWeb is a synthetic data generation pipeline that leverages targeted document rephrasing, format transformation, style modification, and content restructuring to produce diverse, information-dense synthetic corpora. The framework is built on a scalable, production-grade infrastructure (Ray + vLLM on Kubernetes), enabling efficient generation at trillion-token scale.
Key features include:
- Diverse Generation Strategies: Multiple rephrasing and transformation prompts to avoid stylistic and topical homogeneity.
- Quality-First Curation: Selection of high-quality web data as seed material, with rigorous filtering and deduplication.
- Scalable Infrastructure: Distributed, parallelizable generation and experiment tracking, supporting heterogeneous compute environments.
Empirical Results and Scaling Properties
Pareto Frontier and Training Efficiency
BeyondWeb establishes a new Pareto frontier for synthetic pretraining data. Notably, a 3B model trained on BeyondWeb data for 180B tokens outperforms all but one 8B baseline trained on the same token budget, and the 8B BeyondWeb model achieves up to 7.7× faster convergence than RedPajama and 2.7× faster than Nemotron-Synth.
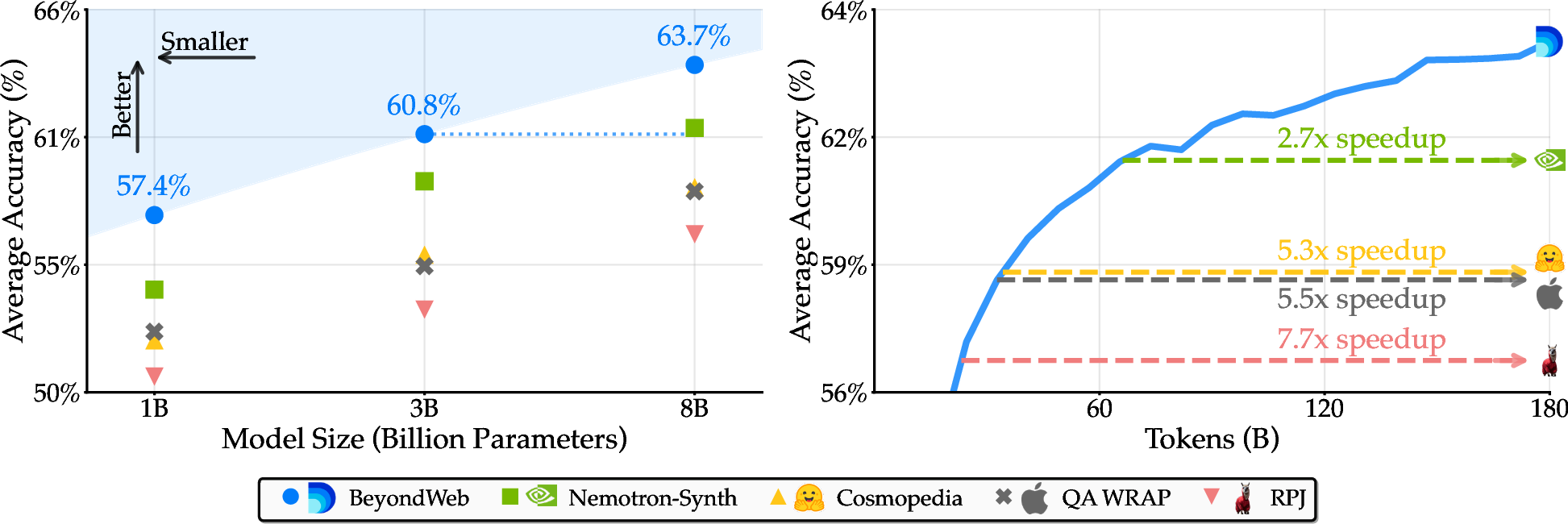
Figure 1: BeyondWeb establishes a new Pareto frontier for synthetic pretraining data, with superior accuracy and training efficiency compared to state-of-the-art baselines.
Ablation studies reveal that simple summarization-based rephrasing can match the performance of sophisticated generator-driven approaches (e.g., Cosmopedia), indicating that increased per-token information density is a primary driver of synthetic data benefits. However, BeyondWeb's more intentional, diverse strategies yield further substantial gains, demonstrating that synthetic data is not merely knowledge distillation.
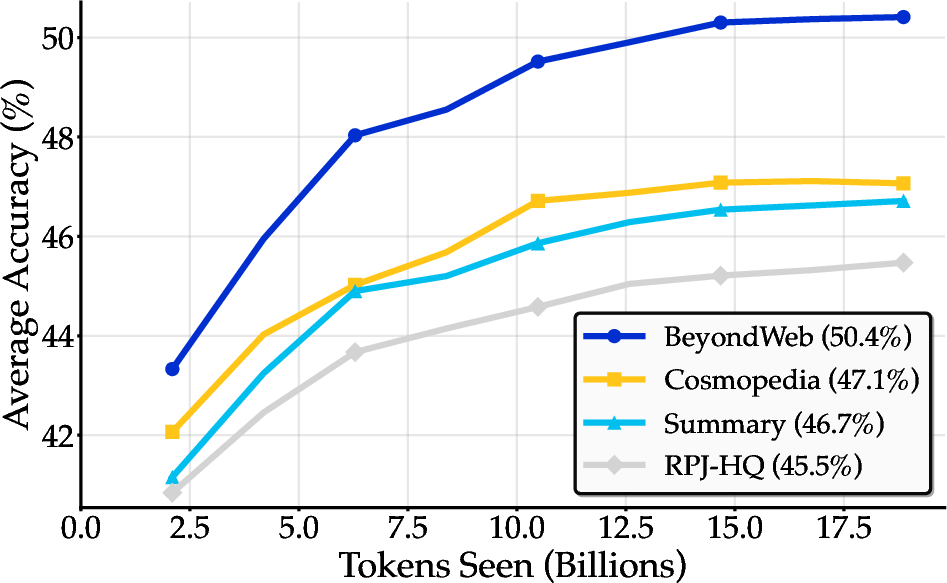
Figure 2: Summarization-based rephrasing achieves similar gains as generator-driven Cosmopedia, but BeyondWeb's approach yields higher accuracy, highlighting the importance of intentional synthetic data design.
Surpassing the Data Wall
Controlled experiments show that naive synthetic data generation (e.g., simple continuations) provides only marginal improvements over data repetition and cannot breach the data wall. In contrast, BeyondWeb's strategic synthetic data generation significantly exceeds the performance ceiling of natural data, with a +4.2pp improvement over the full-data upper bound.
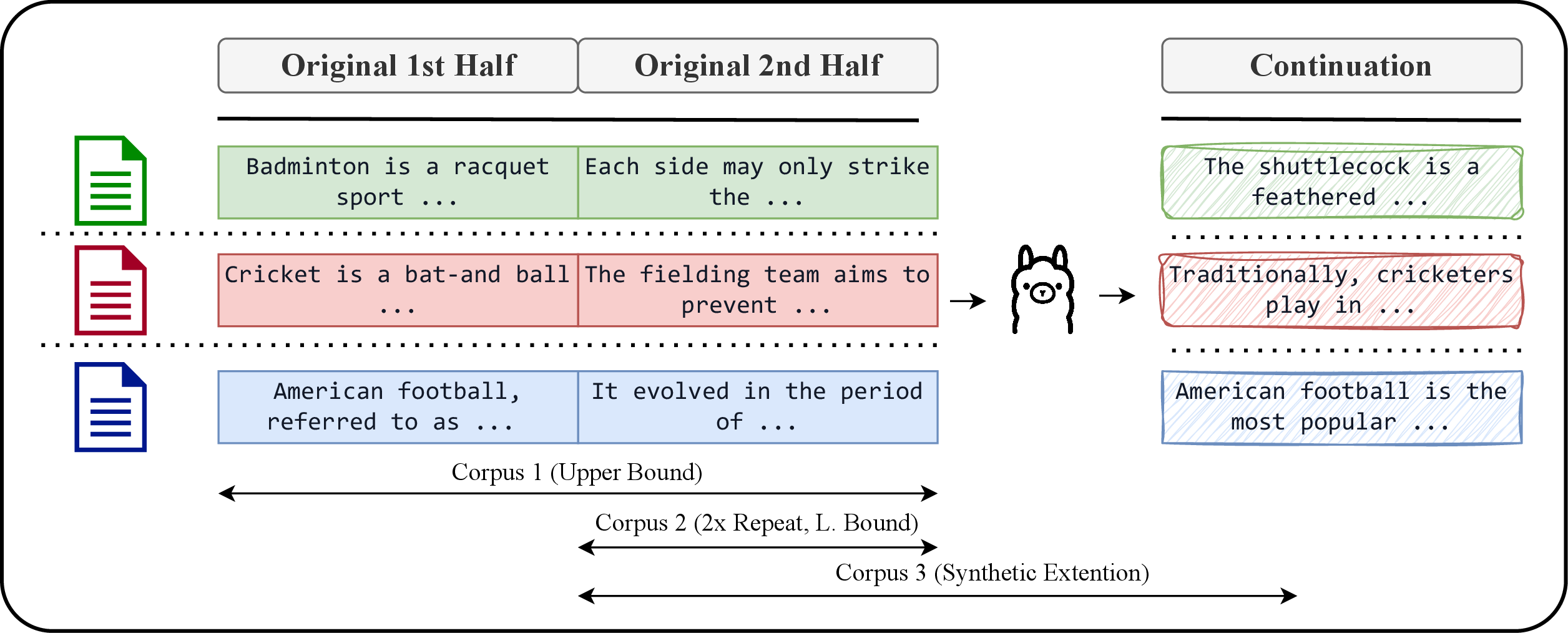
Figure 3: Experimental design for data splitting and corpus construction, isolating the effects of repetition versus synthetic augmentation.
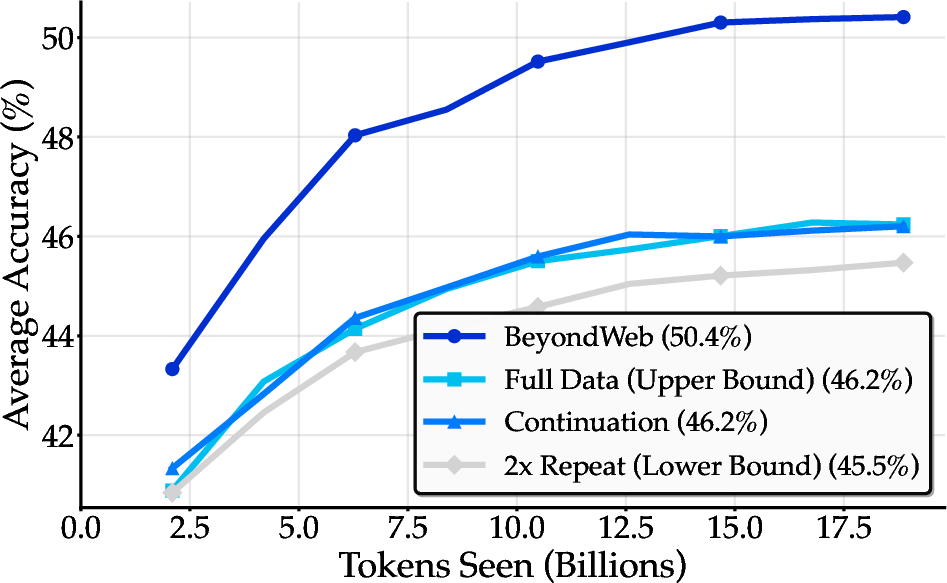
Figure 4: BeyondWeb's synthetic data (dark blue) significantly outperforms both naive continuation and full natural data, demonstrating the necessity of thoughtful synthetic data design.
Quality, Style, and Diversity
- Seed Data Quality: Rephrasing high-quality web data yields larger gains than using low-quality sources, but high-quality input alone is insufficient for optimal synthetic data.
- Style Matching: Upsampling conversational data improves downstream performance, but gains saturate beyond 20% conversational content, indicating that style alignment is necessary but not sufficient.
- Diversity: Diverse generation strategies are critical for sustained improvements, especially at large training budgets. Single-strategy approaches plateau, while BeyondWeb maintains positive learning curves across scales.
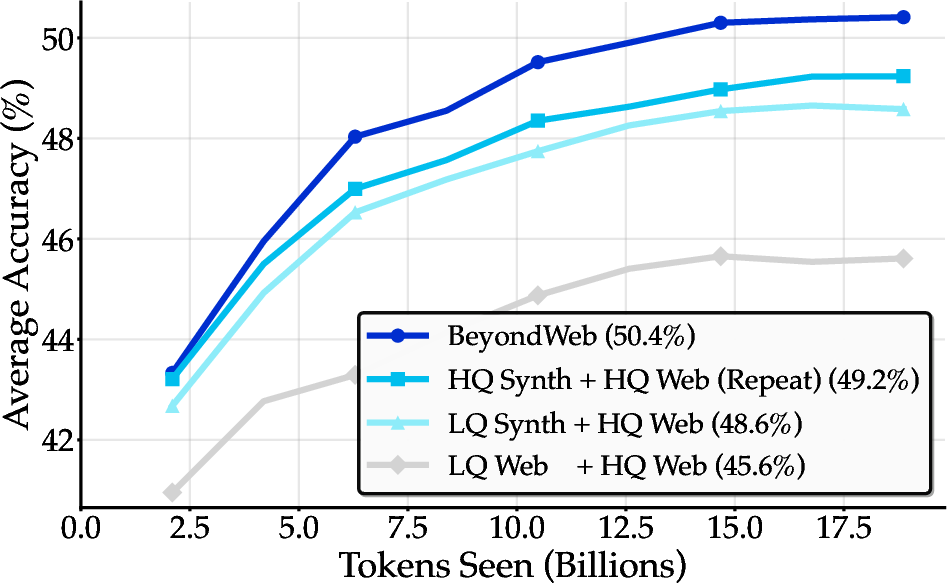
Figure 5: Performance comparison across different quality combinations in training data, showing the importance of high-quality seed data.
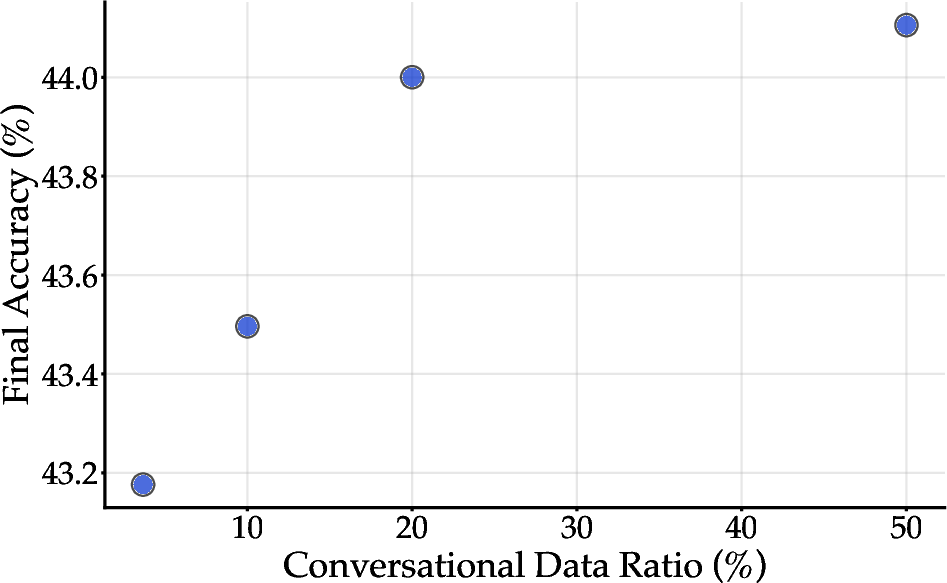
Figure 6: Effect of conversational data ratio on final accuracy, with gains saturating beyond 20% conversational content.
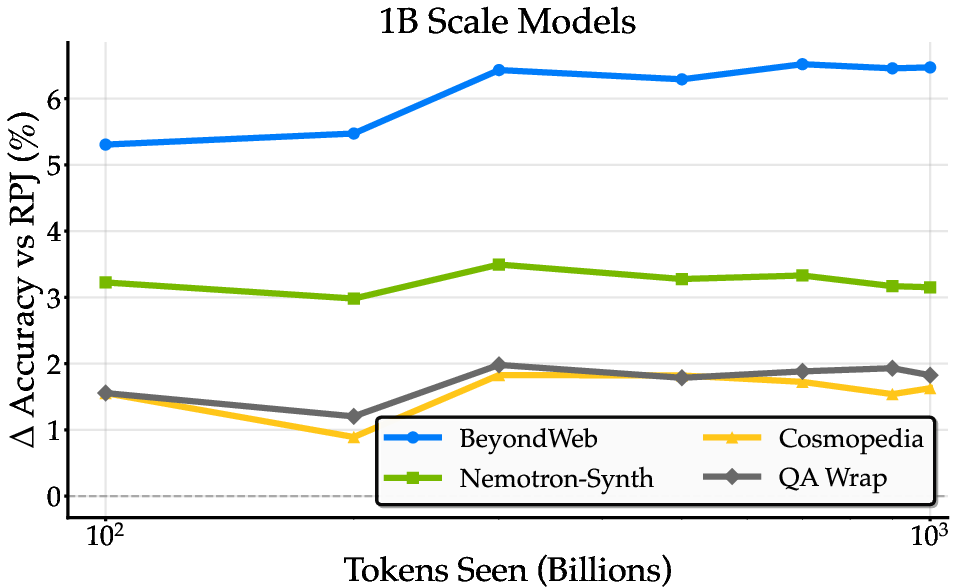
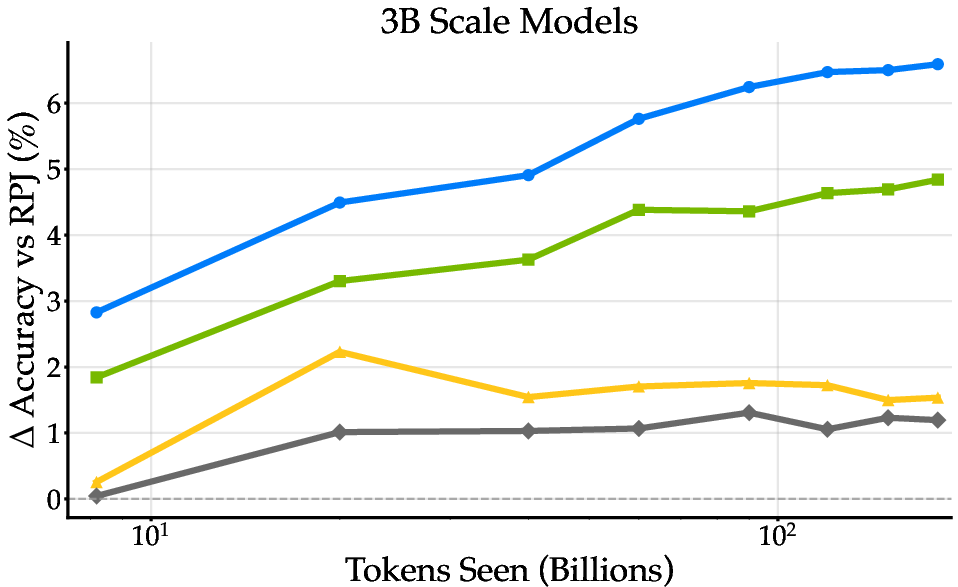
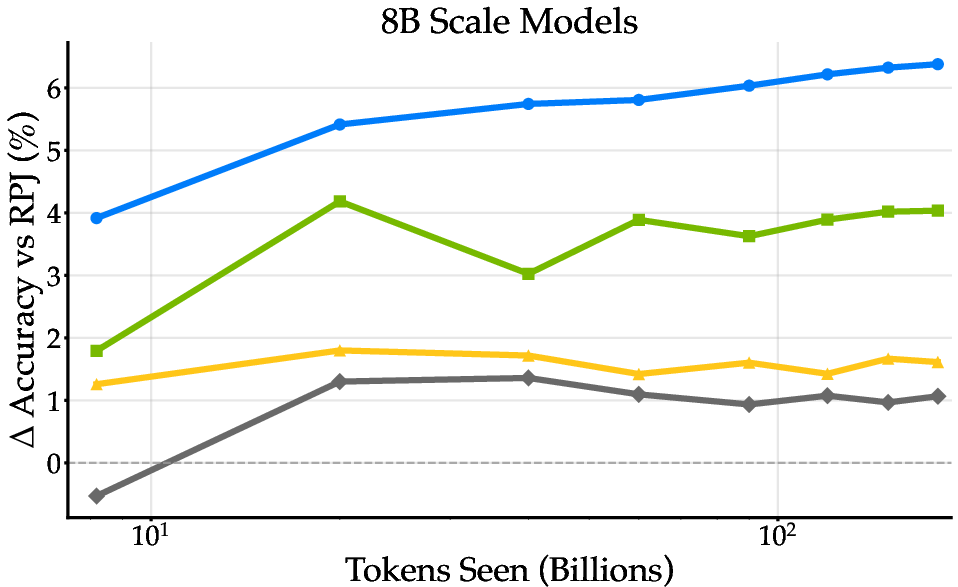
Figure 7: Training dynamics across model scales, with BeyondWeb maintaining consistent improvements and avoiding overfitting in overtrained regimes.
Generator Family and Size
- Model Family Robustness: Synthetic data benefits are consistent across generator model families; the general language modeling ability of the rephraser does not predict synthetic data quality.
- Size Saturation: Increasing rephraser size from 1B to 3B yields substantial gains, but improvements plateau beyond 3B, making small models a cost-effective choice for synthetic data generation.
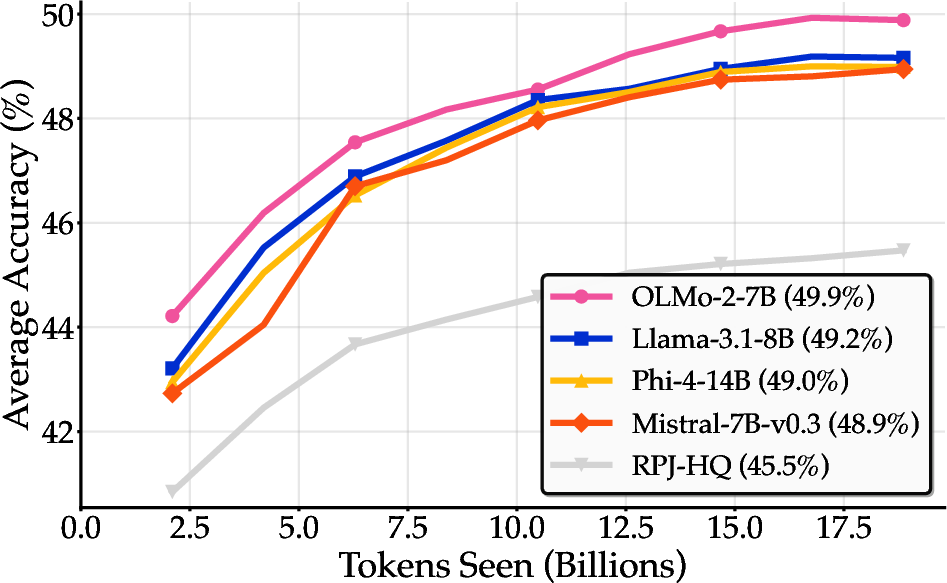
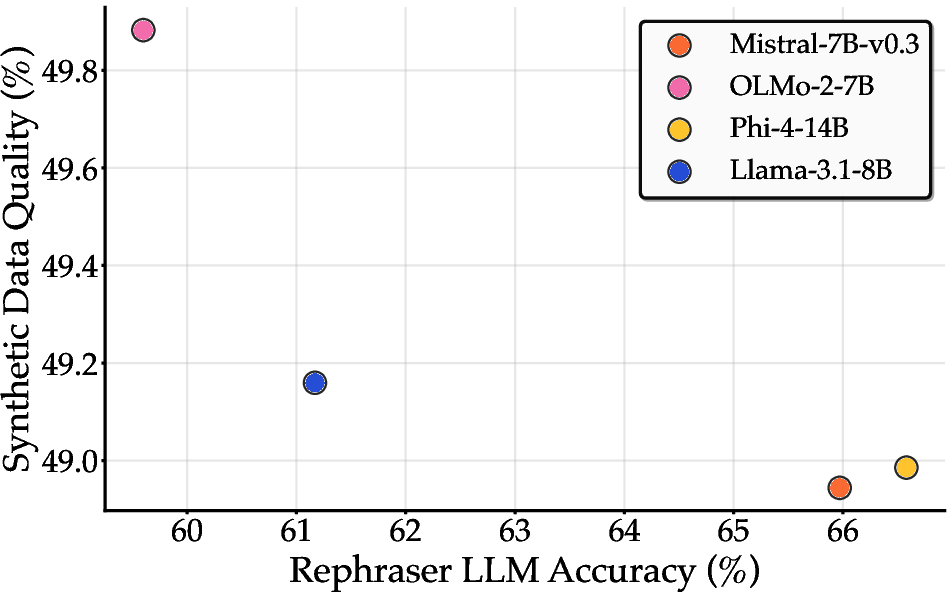
Figure 8: Synthetic data benefits are consistent across generator model families, and generator model quality does not predict synthetic data quality.
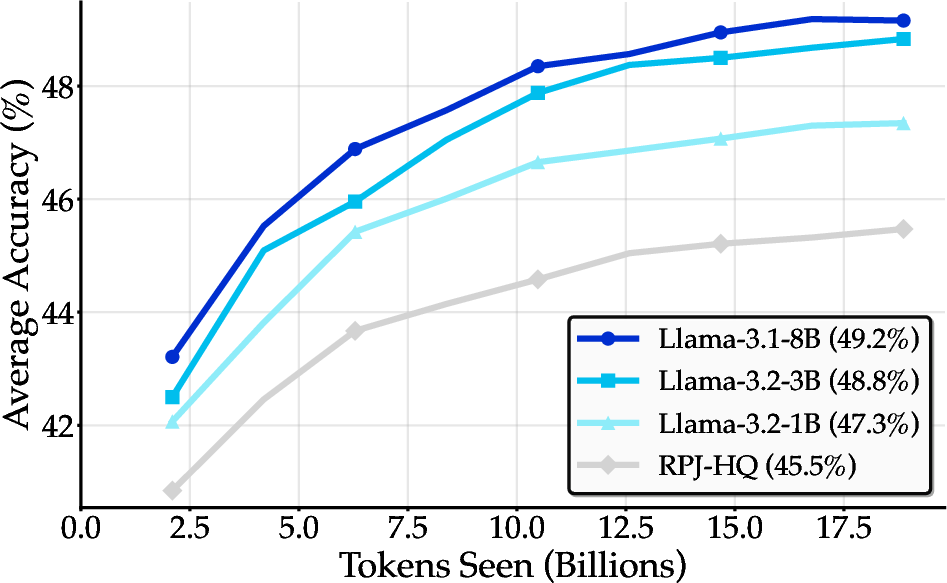
Figure 9: Effect of generator model size on synthetic data quality, with diminishing returns beyond 3B parameters.
Implementation Considerations
- Infrastructure: Distributed, containerized generation pipelines (Ray + vLLM on Kubernetes) are essential for scaling synthetic data generation to trillions of tokens.
- Data Curation: Rigorous filtering, deduplication, and quality control of both seed and synthetic data are necessary to avoid redundancy and maximize information density.
- Prompt Engineering: Diverse, targeted prompts for rephrasing and transformation are required to avoid stylistic collapse and ensure broad coverage.
- Resource Requirements: Effective synthetic data generation does not require massive generator models; 3B-parameter LLMs suffice for most rephrasing tasks, reducing compute costs.
- Evaluation: Multi-task, multi-shot evaluation suites are necessary to robustly assess generalization and avoid overfitting to specific benchmarks.
Implications and Future Directions
The findings have several practical and theoretical implications:
- Synthetic Data as a Primary Modality: High-quality, diverse synthetic data can replace or augment natural data in pretraining, enabling efficient scaling beyond the data wall.
- Democratization: The ability to use small, open-source models for rephrasing lowers the barrier to entry for high-quality LLM pretraining.
- Alignment and Control: Synthetic data generation offers greater control over style, content, and alignment, with potential for explicit value alignment during pretraining.
- Scaling Laws: The intrinsic repetition and diversity properties of synthetic data require new theoretical frameworks for scaling analysis.
- Domain Generalization: The source rephrasing paradigm is not limited to web data or text, and can be extended to domain-specific or multimodal corpora.
Conclusion
BeyondWeb provides a rigorous, scalable, and empirically validated framework for synthetic data generation in LLM pretraining. The work demonstrates that there is no single "silver bullet" for synthetic data; rather, strong outcomes require joint optimization of data quality, style alignment, diversity, and infrastructure. The results challenge the conventional reliance on ever-larger models and natural data, and establish synthetic data curation as a central pillar of future LLM development.
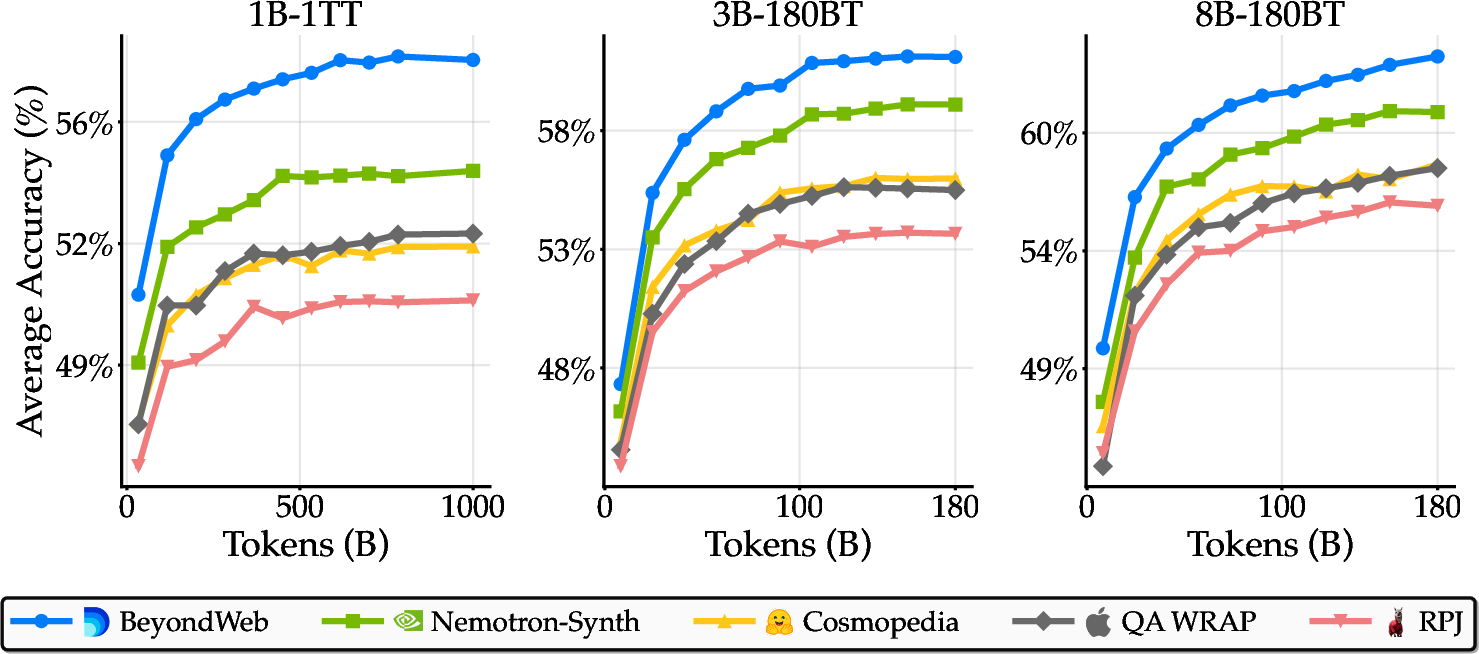
Figure 10: Learning curves across model scales, with BeyondWeb maintaining superior performance throughout training.
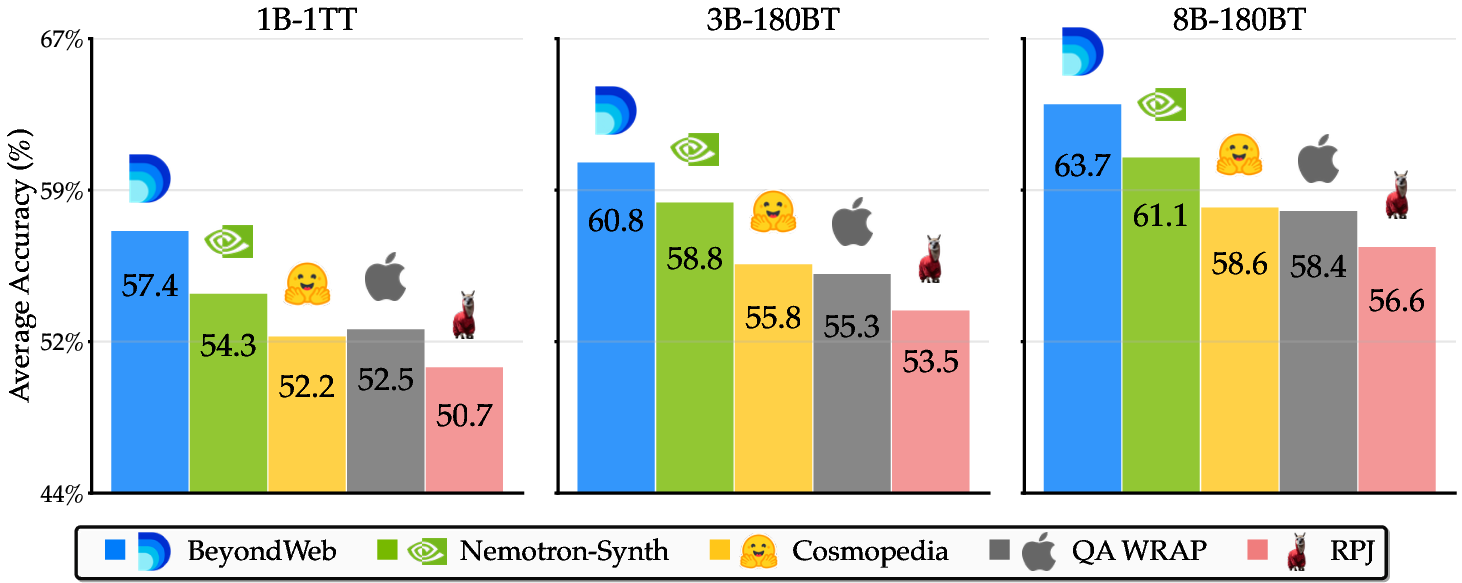
Figure 11: BeyondWeb's significant advantages over state-of-the-art baselines across three model scales, establishing a new Pareto frontier for synthetic pretraining data.

