- The paper introduces the Skill-Mix framework that synthesizes diverse skills to evaluate AI models beyond traditional training data limitations.
- The methodology employs combinatorial prompt generation and advanced automated grading to overcome leaderboard overfitting and assess emergent behaviors.
- Empirical results highlight discrepancies between conventional leaderboard rankings and genuine model generalization, guiding future AI evaluations.
Skill-Mix: a Flexible and Expandable Family of Evaluations for AI Models
This essay explores the "Skill-Mix" methodology, a novel paradigm for evaluating AI models, particularly within the context of LLMs transitioning to serve as general-purpose AI agents. The paper introduces a comprehensive framework for assessing the ability of these models to synthesize and apply various learned skills across diverse contexts, addressing limitations of existing evaluation methods that suffer from training-set contamination and inadequate assessment of untrained skill combinations.
Motivation and Challenges in Current Evaluations
LLMs are increasingly positioned as general-purpose agents, transcending their initial role as mere LLMs. This evolution necessitates robust evaluation metrics that extend beyond traditional, often superficial, benchmarks. Conventional evaluations are vulnerable to contamination from training data that overlap significantly with evaluation datasets and fail to measure genuine combinatorial and emergent capabilities in models.
To counteract these limitations, the "Skill-Mix" evaluation is devised to challenge models with tasks that oblige the integration of multiple skills in novel contexts, thus providing a more insightful gauge of a model’s true generalization capabilities.
Methodology of Skill-Mix Evaluation
The core concept of "Skill-Mix" involves generating tasks that require the model to exhibit a combination of skills out of a predefined set. This is achieved by randomly selecting subsets of skills and topics, posing these as prompts for the AI to process and respond to. The exponential growth of possible skill combinations (Nk) with respect to the number of skills (k) ensures that tasks are not confined to the model's training distribution, thereby necessitating genuine synthesis and innovation from the AI.
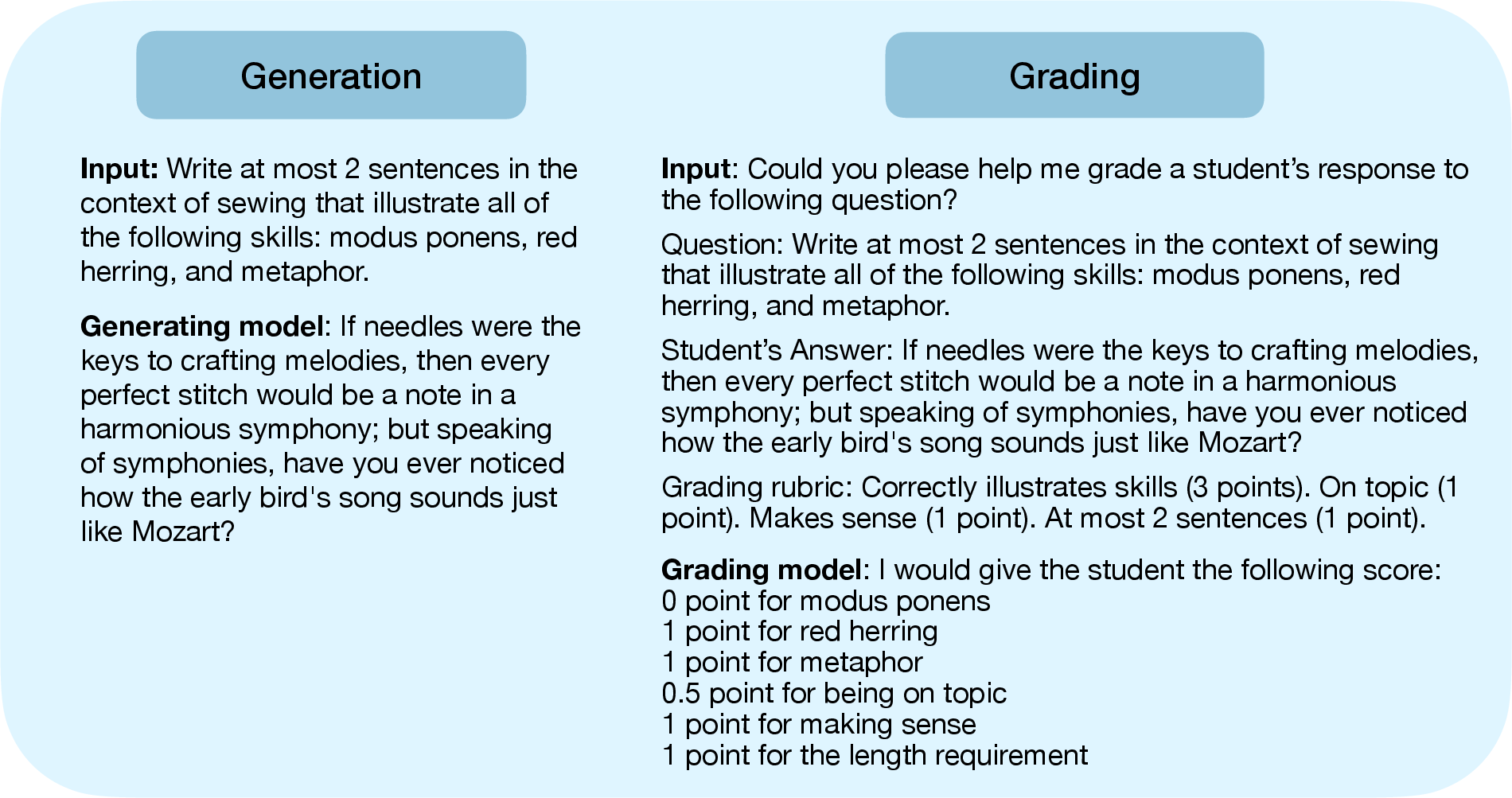
Figure 1: Left: Simplified depiction of the generation stage of our evaluation, demonstrating AI's task of combining topic and skills into coherent text.
Evaluation and Grading Process
The grading of these generated tasks is automated using advanced LLMs themselves, like GPT-4 and the LLaMA-2 model, supplemented by human spot-checking to ensure quality and accuracy. The robustness of this grading approach is essential, as it determines the reliability of the "Skill-Mix" evaluation as a benchmark.
Grading Pipeline
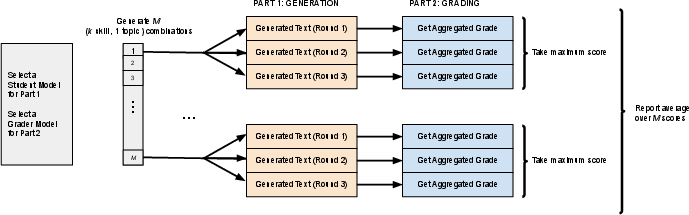
Figure 2: Illustration of the (k) pipeline, with M=100 for GPT-4 grading and M=30 for LLaMA-2 grading.
Key Findings and Insights
Empirical results on popular chatbot models reveal notable differences in capabilities that are overshadowed by conventional leaderboard scores, thereby exposing instances of "cramming for the leaderboard." Specifically, GPT-4’s performance on higher k tasks suggests capabilities that transcend simple mimicry, indicating potential for more profound emergent behaviors beyond training—a significant stride towards surpassing "stochastic parrot" behavior.
This evaluation framework also uncovers discrepancies between leaderboard rankings and actual generalization abilities, pointing towards a prevalent issue of overfitting models to specific benchmark datasets rather than fostering genuine generalization.
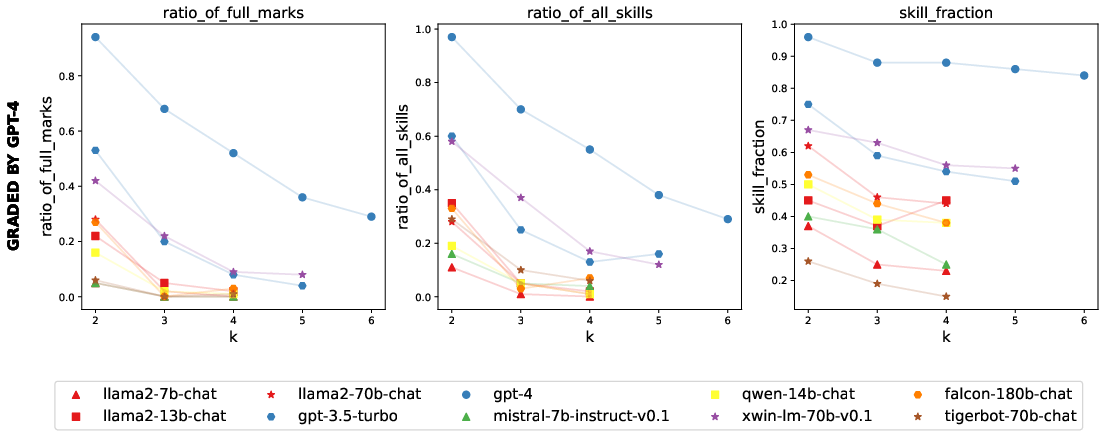
Figure 3: Performance of various instruction-tuned student (generating) models on (k) graded by GPT-4.
Future Directions and Implications
The modular and expandable nature of "Skill-Mix" makes it a versatile tool for evaluating future AI models. It holds potential for application in domain-specific evaluations, such as coding or scientific reasoning, and can be seamlessly adapted to multi-modal data contexts. Moreover, the paradigm encourages the establishment of a trusted ecosystem of evaluations, which could become integral to public policy discussions surrounding AI capabilities and risks.
In conclusion, "Skill-Mix" presents a scalable, contamination-resistant approach that aligns evaluation with the complex, integrative demands placed on contemporary AI models, setting a foundation for more rigorous assessments of general-purpose AI agents.
Concluding Visualization
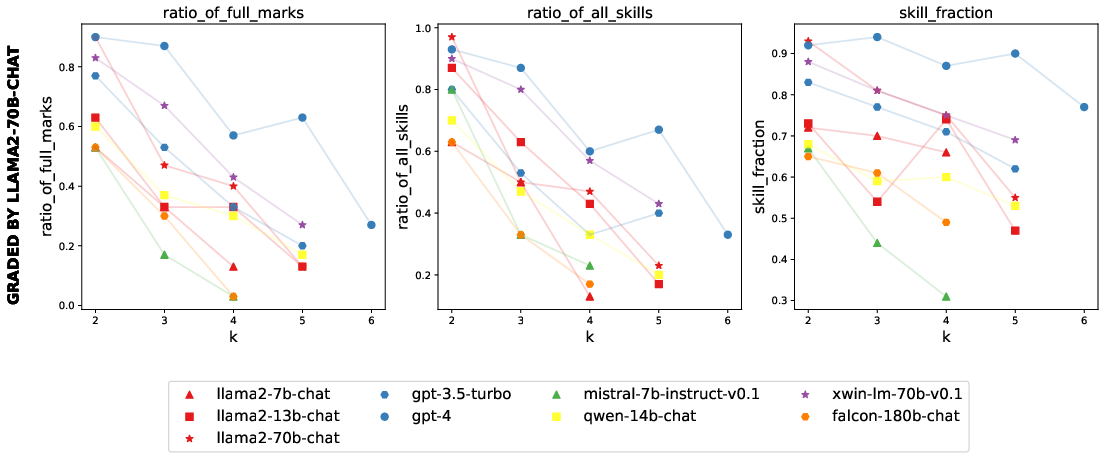
Figure 4: Performance assessment indicating emergent capabilities surpassing "stochastic parrot" behavior in GPT-4.

