- The paper introduces OmniBench-RAG, a platform that standardizes evaluation of RAG systems by quantifying accuracy gains and efficiency trade-offs across diverse domains.
- It employs parallel evaluation tracks comparing vanilla and RAG-enhanced models, utilizing metrics like response time, GPU/memory usage, and accuracy to measure performance.
- Experimental results highlight significant domain-specific variability, with notable improvements in culture and technology contrasted by challenges in health and mathematics.
OmniBench-RAG: A Multi-Domain Evaluation Platform for Retrieval-Augmented Generation Tools
Introduction
The paper proposes OmniBench-RAG, an automated multi-domain evaluation platform designed to assess Retrieval-Augmented Generation (RAG) systems more comprehensively and reproducibly. RAG techniques enhance LLMs by anchoring their responses in external, verified knowledge, thereby augmenting factual accuracy and reducing hallucinations. However, existing benchmarks often lack standardized evaluation frameworks and fail to capture efficiency and cross-domain variability in RAG performance. OmniBench-RAG aims to fill this gap by introducing standardized metrics and systematic evaluation approaches.
OmniBench-RAG's architecture is centered around parallel evaluation tracks for both vanilla and RAG-enhanced models.
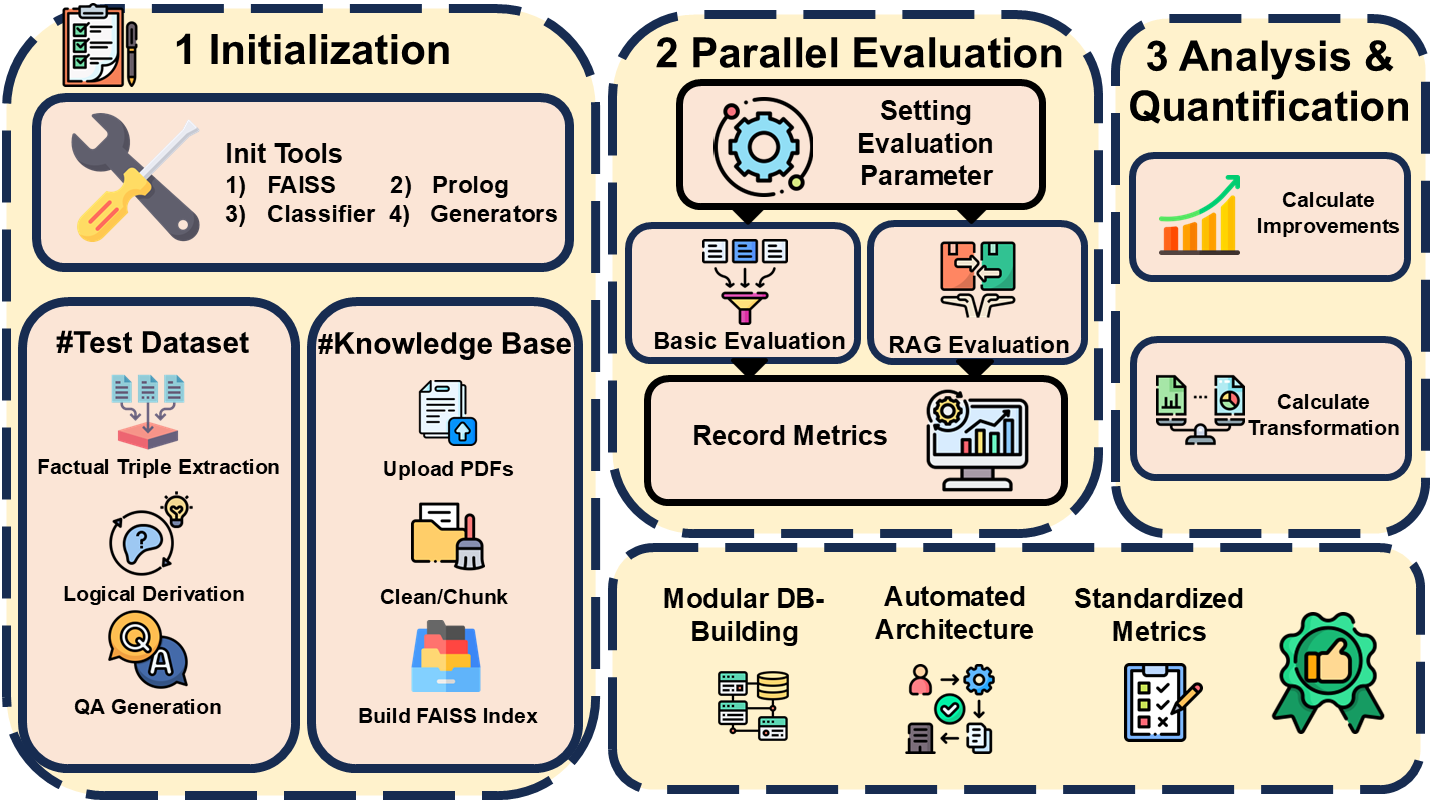
Figure 1: Workflow of OmniBench-RAG.
Stage 1: Initialization and Asset Preparation
This stage involves setting up the system configuration, preparing the knowledge base for RAG evaluation, and generating the test dataset. A dynamic pipeline processes domain-specific documents, converting them into searchable embeddings using FAISS. Two methods are provided for test dataset preparation: loading pre-existing QA datasets or dynamically generating novel test cases using a logic-based methodology.
Stage 2: Parallel Evaluation Execution
Parallel tracks evaluate the model's performance both with and without RAG enhancements. Metrics such as accuracy, response time, GPU, and memory utilization are recorded. The RAG track uses retrieved knowledge chunks to inform model responses, facilitating a comparative analysis of both tracks' performance metrics.
Stage 3: Comparative Analysis and Quantification
The platform introduces two key metrics: Improvements, which quantifies accuracy gains due to RAG, and Transformation, capturing efficiency trade-offs in terms of response time, GPU, and memory usage. These metrics enable comparisons across the domains and model variants, offering insights into the effectiveness of RAG enhancements across various knowledge fields.
Evaluation Results
The evaluation involved assessing the Qwen model across nine domains: culture, geography, history, health, mathematics, nature, people, society, and technology. OmniBench-RAG's analysis revealed notable domain-specific variability in RAG's impact, demonstrating significant improvements in domains like culture and technology while exhibiting declines in domains like health and mathematics. This highlights the alignment or misalignment of retrieval content with domain-specific requirements as crucial to the effectiveness of RAG.
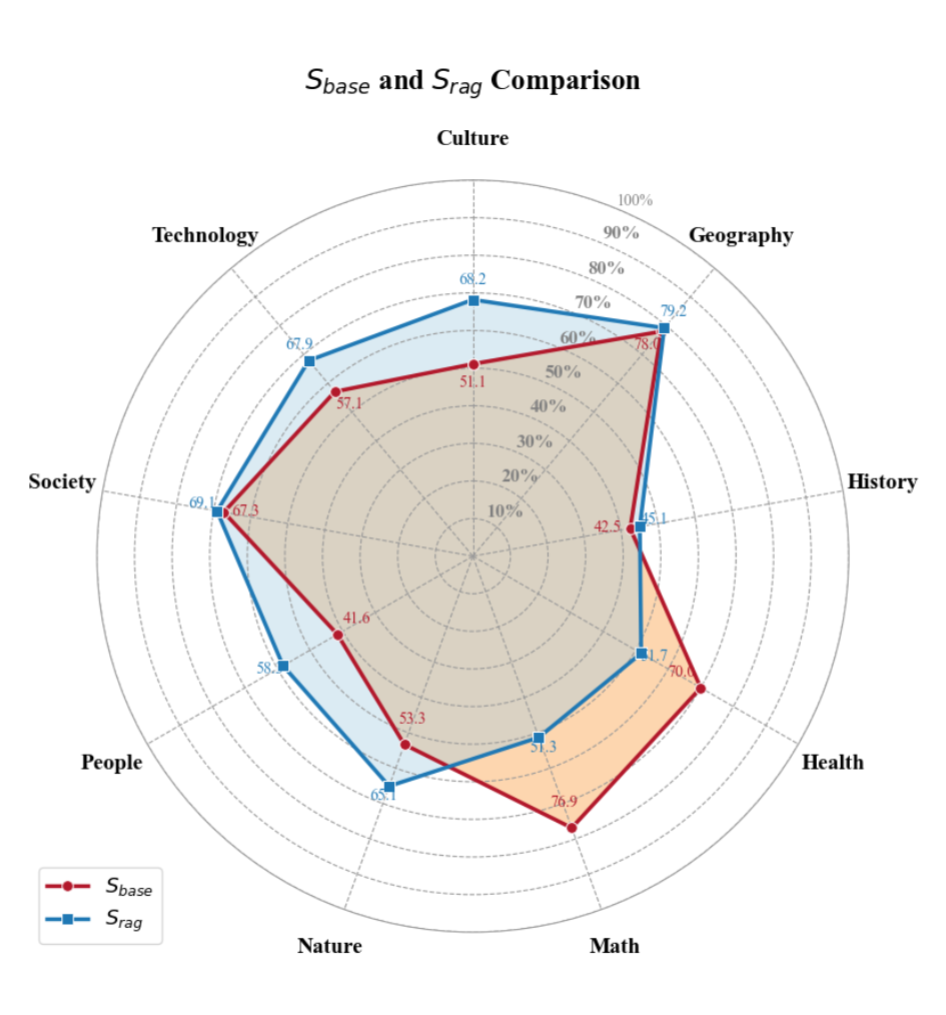
Figure 2: Radar plot of Qwen's accuracy across nine knowledge domains, comparing Sbase and SRAG.
For instance, substantial gains in the culture domain were linked to the use of contextually rich datasets that aligned well with QA tasks. Conversely, the health domain suffered due to generic retrieval processes failing to support structured, rule-based reasoning tasks.
Table 1 provides a quantitative summary of Qwen's performance across the domains, illustrating both accuracy improvements and efficiency transformations.
Conclusion
OmniBench-RAG represents a significant advancement in the evaluation of RAG systems by providing an automated, systematic, and reproducible platform for multi-domain assessment. The platform's parallel evaluation architecture, dynamic test generation capabilities, and standardized metrics enable comprehensive analyses of RAG's impact across different models and domains. Findings underscore the variability of RAG effectiveness, indicating its significant potential in some areas while highlighting challenges in others. By spotlighting domain-dependent performance variances, OmniBench-RAG aids in data-driven decision-making regarding the deployment of RAG-enhanced LLMs.

