- The paper introduces UltraRAG, a modular and automated toolkit that enhances RAG systems by streamlining the full workflow from data construction to evaluation.
- It employs a modular architecture with distinct global and core functional modules to facilitate model management and support multimodal retrieval and generation.
- In legal-domain applications, UltraRAG significantly improves retrieval precision and generation coherence through synthetic data construction and targeted model fine-tuning.
Introduction
The paper "UltraRAG: A Modular and Automated Toolkit for Adaptive Retrieval-Augmented Generation" introduces UltraRAG, a toolkit designed to enhance the capabilities of Retrieval-Augmented Generation (RAG) systems. RAG systems augment LLMs by integrating external knowledge sources to improve their accuracy and reliability. UltraRAG addresses limitations found in existing RAG toolkits, such as the lack of support for knowledge adaptation and ease of deployment in diverse application scenarios. UltraRAG provides a comprehensive solution covering the entire RAG workflow—from data construction and model training to deployment and evaluation.
System Architecture
UltraRAG is characterized by its modular architecture, which includes two global settings modules for Model Management and Knowledge Management, and three core functional modules for Data Construction, Training, and Evaluation/Inference. This structure enables the automation of the knowledge adaptation process for different domains, increasing system efficiency and accuracy across various tasks.
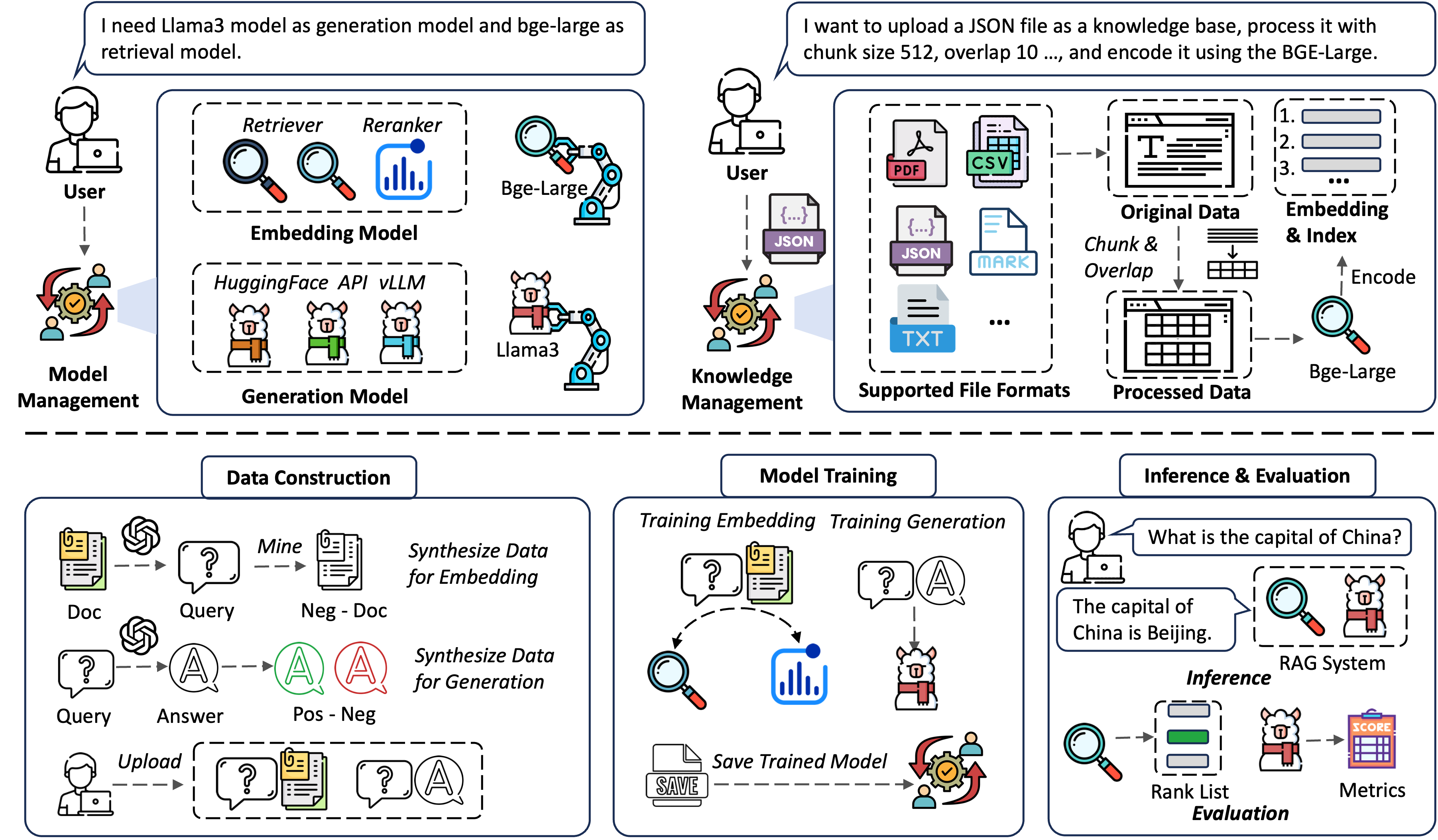
Figure 1: The Overall Architecture of UltraRAG Framework.
The toolkit is enhanced with a user-friendly WebUI, providing a seamless experience for users who may not have programming expertise. This interface facilitates the deployment and optimization of RAG systems, supporting multimodal inputs and offering extensive tools for knowledge base management.
Key Features
- WebUI: UltraRAG provides an intuitive interface that simplifies the deployment and management of RAG systems.
- Multimodal Support: It integrates multimodal retrieval and generation models, extending its utility beyond text-based tasks.
- Knowledge Management: Supports flexible knowledge base formats and streamlines the process of encoding and indexing documents.
- End-to-End Solution: Covers all stages from data construction to model fine-tuning and evaluation, incorporating advanced RAG algorithms and datasets.
- Knowledge Adaptation: Automatically generates and fine-tunes domain-specific training data to enhance retrieval and generation components for specific scenarios, leading to improved task performance.
Practical Implementation
UltraRAG is designed to reduce the complexity of creating RAG systems, allowing researchers to focus on experiment design rather than software engineering. It incorporates various RAG methods, including Vanilla RAG, RA-DIT, and more adaptive approaches like UltraRAG-DDR and UltraRAG-KBAlign, facilitating comparative research across different techniques.
UltraRAG enables domain-specific adaptations, such as in the legal domain, to manage complex terminology and enhance the applicability of LLMs. By employing synthetic data construction and embedding model fine-tuning, UltraRAG equips models to better capture domain-specific nuances and improve both retrieval and generation metrics.
Evaluation and Results
In legal-domain applications, UltraRAG demonstrated significant performance improvements when adapted to specific domain tasks, including higher accuracy in law prediction and consultation tasks. Knowledge adaptation was shown to dramatically improve retrieval precision and generation coherence, highlighting the importance of targeted domain adaptation.
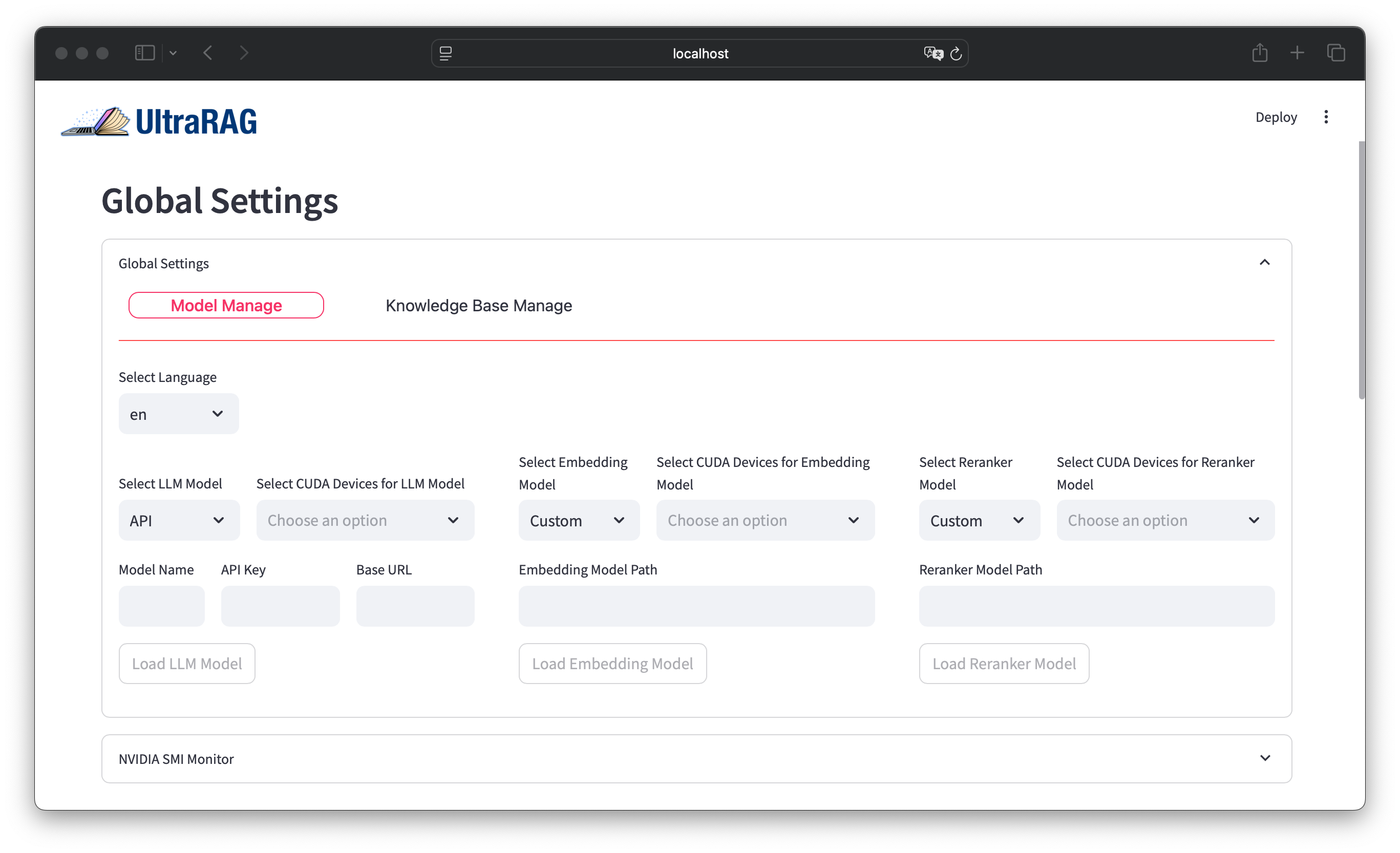

Figure 2: Screenshots of UltraRAG.
Conclusion
UltraRAG presents a modular, automated solution that addresses critical challenges in developing RAG systems, particularly for domain-specific knowledge adaptation. It offers an adaptable framework with comprehensive tools for researchers, enabling efficient RAG system building, deployment, and evaluation. With its extensible architecture and user-friendly interface, UltraRAG significantly lowers the barrier to entry, facilitating broader adoption and fostering innovation in RAG research and applications.

