- The paper introduces a robust evaluation framework called PRGB Benchmark that emphasizes LLM multi-level filtering, combination, and reference reasoning in RAG systems.
- It presents a dynamic placeholder substitution technique to mitigate inherent model bias and assess reliance on external retrieval data.
- Experiments with top-tier LLMs reveal varied strengths, where smaller models excel at noise filtering while larger ones demonstrate advanced multi-document synthesis.
PRGB Benchmark: A Robust Placeholder-Assisted Algorithm for Benchmarking Retrieval-Augmented Generation
Introduction
The "PRGB Benchmark" outlined in the paper "PRGB Benchmark: A Robust Placeholder-Assisted Algorithm for Benchmarking Retrieval-Augmented Generation" (2507.22927) presents a methodological foray into evaluating the specific capabilities of LLMs within Retrieval-Augmented Generation (RAG) systems. Unlike previous benchmarks that focus on the overall performance metrics of RAG systems, this research emphasizes the specific generative capabilities of LLMs in utilizing external knowledge retrieved by these systems.
Placeholder-RAG-Benchmark Framework
The core of this research is the Placeholder-RAG-Benchmark, which differentiates itself by offering a structured, multi-level evaluation framework aimed at systematically examining LLMs' abilities in RAG systems along three dimensions: multi-level filtering, combination, and reference reasoning.
Multi-Level Filtering:
This dimension evaluates the capability of LLMs to filter irrelevant noise from retrieved documents. It categorizes noise into three types:
- Weak Noise: Derived from completely irrelevant entities, assessing the model's basic filtering capability.
- Moderate Noise: Introduced from semantically similar entities, requiring discernment in accurate document filtering.
- Hard Noise: Poses particular challenge by involving general cases that may conflict with specific retrievals.
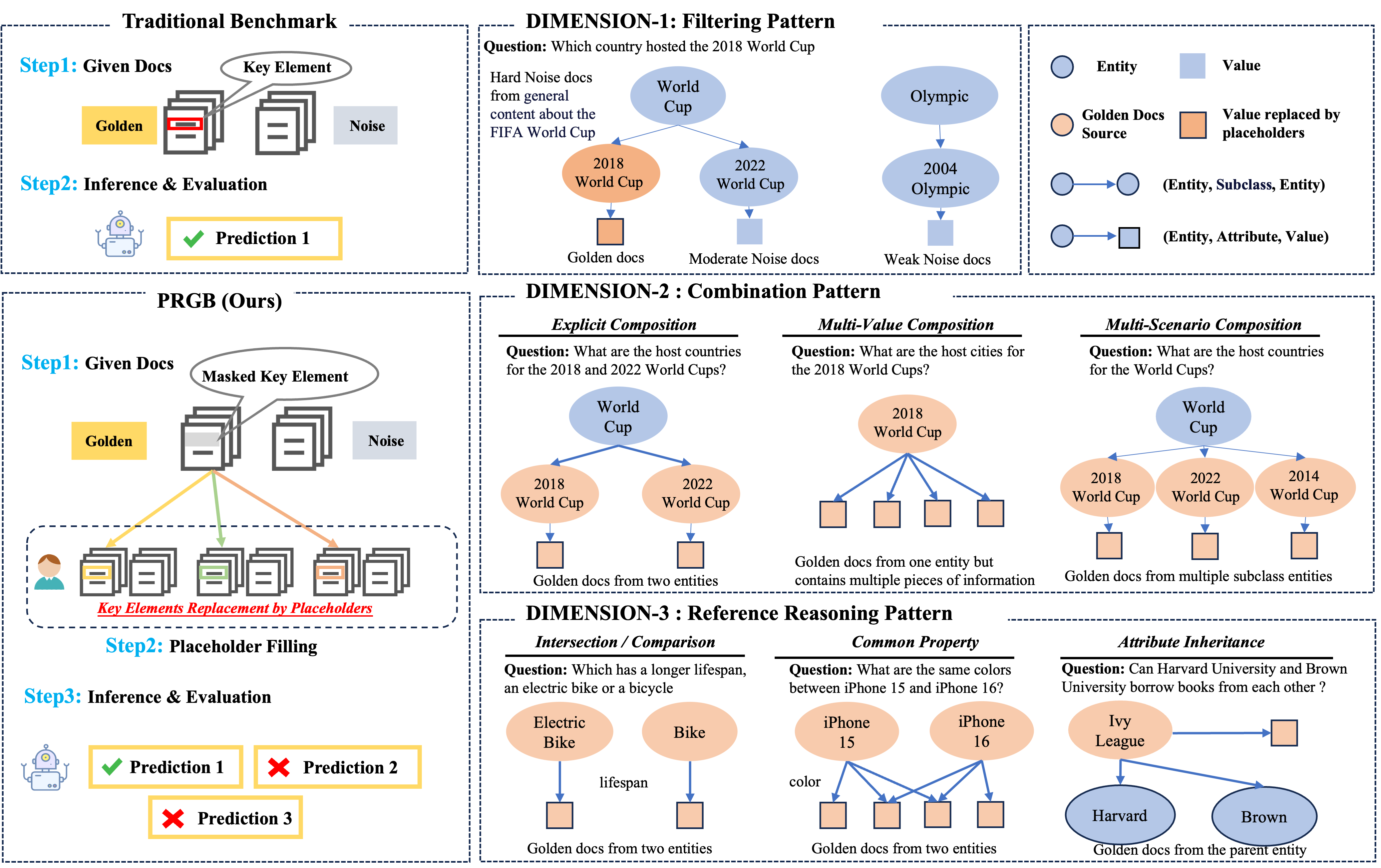
Figure 1: Visualization for Evaluation Dimensions of Placeholder-RAG-Eval. Starting from triplet-based metadata, three finer-grained evaluation tasks are formulated, including filtering, composition, and reasoning.
Combination Abilities
This dimension tests whether LLMs can assimilate information across multiple documents to address complex queries effectively. The tasks here are:
- Explicit Composition: Questions require merging information from multiple related entities.
- Multi-Value Composition: Models must recognize all relevant data points for developing a comprehensive response.
- Multi-Scenario Composition: Models are tasked with integrating information from broader scenarios shared among related entities.
Reference Reasoning Tasks
Reference reasoning aims to assess an LLM's capacity to perform multi-hop reasoning, a skill crucial in answering queries that depend on synthesized knowledge:
Dynamic Placeholder Substitution
A salient innovation of the Placeholder-RAG-Benchmark is the introduction of dynamic placeholder substitution. This technique mitigates the inherent bias imparted by pre-trained LLMs' internal knowledge, placing emphasis on the capability to utilize external, retrieved data to answer queries correctly. By replacing critical information in documents with placeholders, this method examines the LLM's ability to generate contextually accurate responses based on available external data.
Experimentation and Results
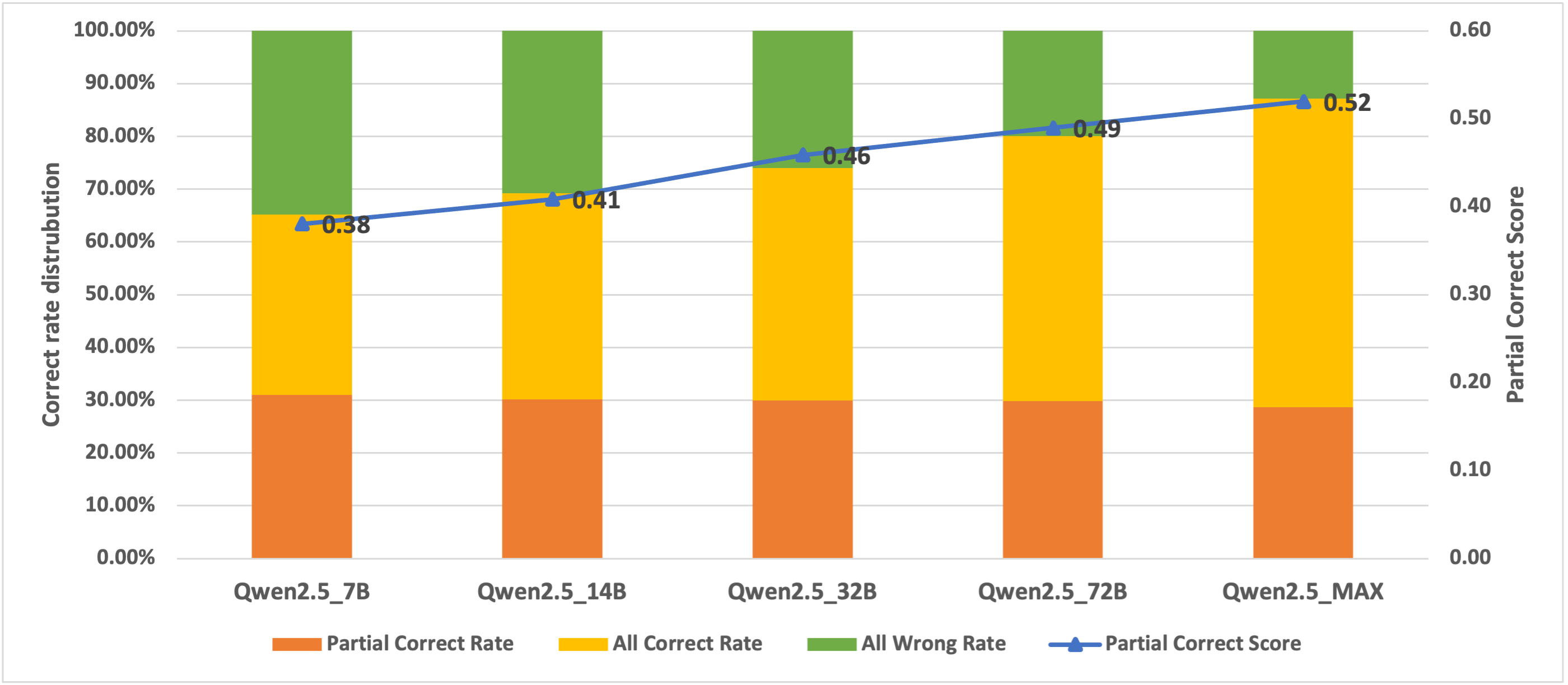
A selection of top-tier LLMs, including variants from the Qwen2.5 series and other competitive models such as GPT-4o and Gemini, were assessed using this benchmark. The assessment revealed:
- Reasoning Ablities: Models exhibited varied efficacy across different benchmark dimensions, significantly depending on their reasoning strategies. Models with enhanced reasoning capabilities demonstrated superior performance in filtering and combination tasks (Table 1), as models without these abilities often produced incorrect, unanalyzed responses.
- (Figure 1) illustrates some of the complex evaluation tasks developed for the benchmark.
- Noise Filtering Efficiency: Filtering efficacy was not proportionally related to model size. Smaller models sometimes surpassed larger ones in handling tasks with low-level noise. Large models with robust language capabilities tended to paraphrase the content, leading to potential errors when evaluating direct excerpts from retrieved documents.
- (Table \ref{tab:main}) depicts performance variations among different LLMs when subjected to the PRGB Benchmark.
- Advanced Composition and Reasoning: The benchmark found larger models more adept in multi-document synthesis and reference reasoning tasks, underscoring their superior capability in aggregation and multi-hop reasoning.
- (Table \ref{tab:model_rag_scores}) shows the contrast between models' performance across various reasoning tasks.
Conclusion
The "PRGB Benchmark: A Robust Placeholder-Assisted Algorithm for Benchmarking Retrieval-Augmented Generation" (2507.22927) establishes a pioneering fine-grained evaluation framework for assessing LLMs' proficiency in RAG systems. By emphasizing multi-level filtering, combinatory synthesis, and reference reasoning while incorporating innovative placeholder substitution mechanisms, the benchmark advances the nuanced appreciation of LLMs' ability to process and utilize external knowledge. Results from the evaluation reveal distinct model proficiencies, demonstrating that larger models hybridize knowledge more effectively, yet do not dominate all tasks. This benchmark presents a substantial foundation for further research in RAG systems, focusing on accuracy for developing responsive and reliable RAG-based solutions. Future endeavors may include refining evaluation metrics and expanding the benchmark to embrace a broader range of generative tasks in multilingual and domain-specific settings.