- The paper contributes by introducing Libra Bench, a rigorous benchmark designed to evaluate reward models in complex reasoning scenarios.
- The methodology employs rejection sampling, supervised fine-tuning, and reinforcement learning to embed deep thinking in generative models.
- Experimental results show that the Libra-RM series outperforms previous models, significantly improving accuracy on challenging math and reasoning tasks.
Libra: Assessing and Improving Reward Model by Learning to Think
The paper "Libra: Assessing and Improving Reward Model by Learning to Think" introduces a comprehensive framework aimed at evaluating and enhancing generative reward models (RMs) specifically in complex reasoning scenarios. The authors propose two main contributions: the creation of Libra Bench, a reasoning-oriented RM benchmark, and the development of the Libra-RM series, which are reward models characterized by deep thinking capabilities. These advancements provide a robust foundation for optimizing reward models to handle the intricate challenges presented by mathematical and advanced reasoning problems.
Introduction to Libra Bench
Libra Bench is curated to address the inadequacies of existing RM benchmarks, particularly their insufficient rigor in challenging reasoning scenarios. It is built from a collection of complex mathematical problems, complemented by rollouts from advanced reasoning models. The benchmark aims to assess reward models by evaluating their pointwise judging accuracy, which is particularly critical when the correctness of responses must be determined.
Libra Bench utilizes several data sources, including high-level math competitions like the American Invitational Mathematics Examination (AIME) and the MATH dataset. The incorporation of model-based evaluation and human annotations ensures the reliability of correctness labels. This benchmark is distinguished by its focus on the correct assessment of non-trivial tasks, effectively bridging the gap between standard RM evaluations and real-world reasoning challenges.
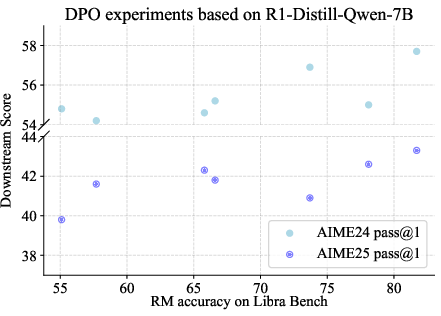
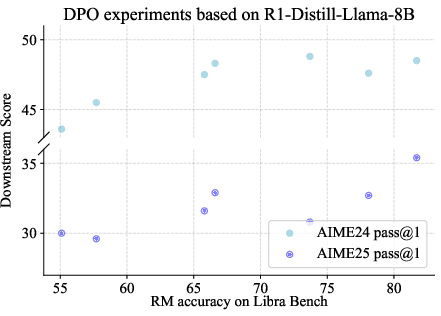
Figure 1: Correlation between Libra Bench accuracy and downstream performance.
Libra-RM Series Development
The Libra-RM series is developed using a novel approach that combines rejection sampling with reinforcement learning to imbue reward models with enhanced reasoning capabilities. This approach involves two key stages:
- Rejection Sampling and Supervised Fine-Tuning (SFT): During this phase, the reward model is initially fine-tuned on a mixture of judging and non-judging data. The inclusion of non-judging data broadens the model’s skills, augmenting its general reasoning ability.
- Reinforcement Learning for Judging: Post-SFT, models undergo reinforcement learning using a verifiable dataset, where the generative reward model learns to produce judgments reflective of high correctness. A rule-based reward structure, integrating both correctness verification and length penalties, guides the reinforcement learning process.
This two-stage training process leads to the Libra-RM series, capable of achieving state-of-the-art results on multiple benchmarks, and particularly excel on reasoning-centric evaluations.
The experimental evaluations demonstrate the Libra-RM series' superior performance compared to both existing reward models and LLM-as-a-Judge methods. The series displays remarkable accuracy on Libra Bench, with distinct improvements in handling both correct and incorrect samples, as evidenced by the confusion matrix analyses.
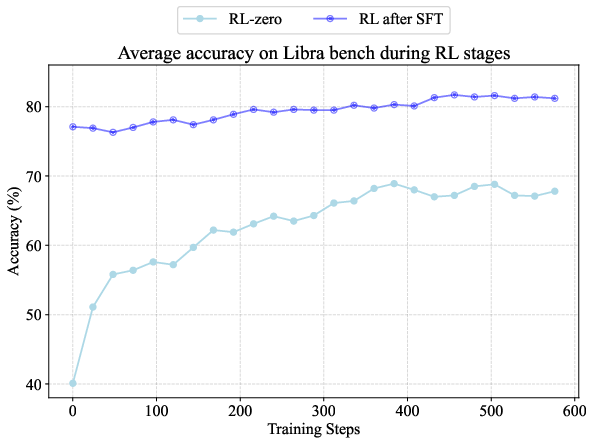
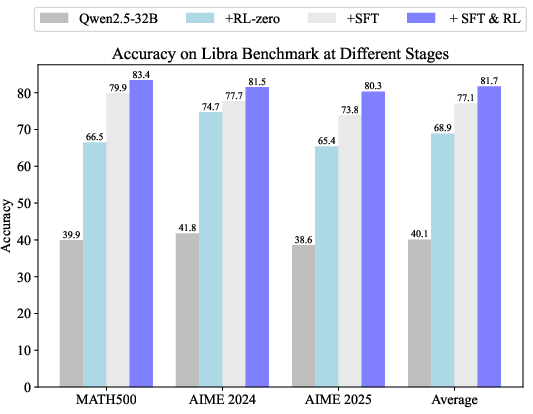
Figure 2: (a) Average accuracy on Libra Bench during RL-zero and RL after SFT. (b) Accuracy on Libra Bench at different stages, including initial model, RL-zero model, SFT model, and SFT + RL model.
Furthermore, Libra Bench's accuracy is highly correlated with downstream performance in DPO experiments. This correlation underscores the benchmark’s potential as a predictive tool for optimizing reward model effectiveness in practical applications.
Libra-RM's ability to enhance model reasoning with unlabeled data highlights its potential for scaling RL data acquisition and utilization without reliance on reference answers, addressing a key limitation in current RL methods.
Conclusion
In conclusion, the "Libra: Assessing and Improving Reward Model by Learning to Think" paper presents a significant advancement in the field of reward modeling by proposing a robust framework for both evaluation and improvement of generative RMs. Libra Bench offers a rigorous testing ground that aligns closely with real-world reasoning demands, while the Libra-RM series sets a new standard for models imbued with deep thinking capabilities. The methodologies outlined pave the way for future developments in reward modeling, particularly in expanding the applicability of RL techniques in varied and complex reasoning tasks.