- The paper introduces J1, a reinforcement learning framework that trains LLMs to generate explicit chain-of-thought reasoning before delivering verdicts.
- It leverages synthetic preference pairs and Group Relative Policy Optimization to optimize both reasoning processes and final judgments while reducing bias.
- Empirical results demonstrate that J1-Llama models outperform previous methods on numerous benchmarks with far fewer training examples.
J1: Incentivizing Thinking in LLM-as-a-Judge via Reinforcement Learning
Overview and Motivation
The paper introduces J1, a reinforcement learning (RL) framework for training LLMs to act as judges, with a focus on incentivizing explicit reasoning and mitigating judgment bias. The motivation stems from the observation that the progress of AI is increasingly bottlenecked by the quality of evaluation, and that LLM-as-a-Judge models—those that generate chain-of-thought (CoT) reasoning before making decisions—are central to robust evaluation pipelines. J1 advances the state-of-the-art by converting both verifiable and non-verifiable prompts into judgment tasks with verifiable rewards, enabling RL-based optimization of both reasoning and verdicts.
Methodology
Synthetic Data Generation
J1 leverages synthetic preference pairs for both verifiable (e.g., math) and non-verifiable (e.g., open-ended chat) tasks. For each prompt, high-quality and low-quality responses are generated, allowing the judgment task to be reframed as a verifiable classification problem. This approach obviates the need for costly human annotation and ensures scalability across diverse domains.
RL Training Recipes
J1 employs the Group Relative Policy Optimization (GRPO) algorithm, which estimates baselines from group scores and removes the need for a separate critic. The RL objective jointly optimizes the generation of intermediate thoughts and the final judgment. The training data is constructed to be position-agnostic, with both response orders included in each batch to facilitate the design of consistency-based rewards.
Reward Modeling
Two primary reward types are used:
- Verdict Correctness Reward: Binary reward based on the accuracy of the final verdict.
- Verdict Consistency Reward: Reward assigned only when the model produces correct judgments for both response orders, directly targeting position bias.
Additional format rewards (e.g., enforcing output tags) were explored but found to have negligible impact.
Model Variants
J1 supports several LLM-as-a-Judge configurations:
- Pairwise-J1 with Verdict: Outputs a preferred response after generating CoT reasoning.
- Pairwise-J1 with Scores: Assigns real-valued scores to each response.
- Pairwise-J1 with Scores and Verdict: Outputs both scores and a verdict.
- Pointwise-J1: Evaluates a single response and outputs a score, trained via distant supervision from pairwise data.
Empirical Results
J1 was instantiated at two scales: J1-Llama-8B and J1-Llama-70B, both initialized from Llama-3.x-Instruct models. Evaluation was conducted on five major reward modeling benchmarks: PPE, RewardBench, JudgeBench, RM-Bench, and FollowBenchEval.
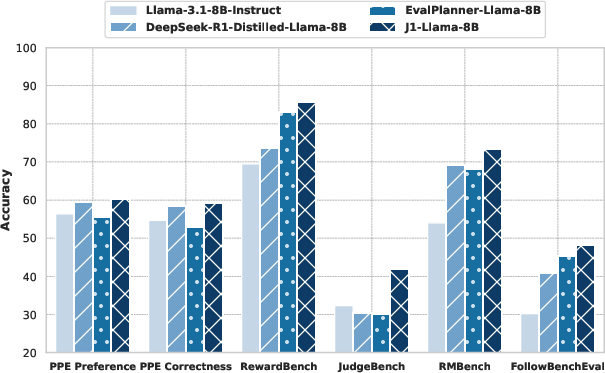
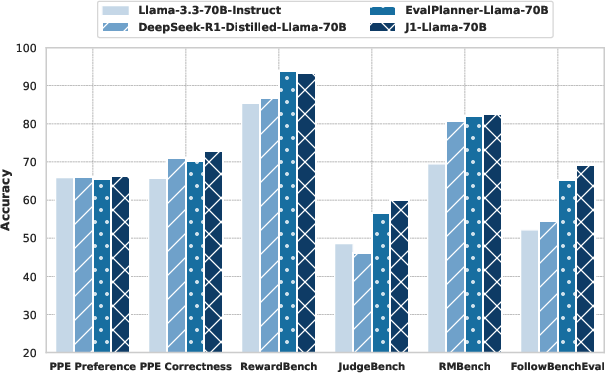
Figure 1: Pairwise-J1 outperforms all baselines on five reward modeling benchmarks at both 8B and 70B scale, despite being trained only on synthetic preference pairs.
- J1-Llama-70B achieves 69.6% overall accuracy on PPE, outperforming all previous methods, including those trained on orders of magnitude more data.
- J1-Llama-8B is competitive with larger scalar reward models and outperforms prior generative reward models at the same scale.
- Test-time scaling via self-consistency (sampling multiple CoTs and aggregating verdicts) yields further improvements of up to 1.5% at both scales.
Comparison with SOTA
J1 surpasses models trained with SFT, DPO, and recent generative reward models (e.g., DeepSeek-GRM, EvalPlanner), as well as models distilled from larger reasoning models (e.g., DeepSeek-R1). Notably, J1 outperforms the much larger DeepSeek-R1 on non-verifiable tasks and closes the gap on verifiable tasks.
Position Bias and Consistency
Extensive ablations demonstrate that:
- Pairwise-J1 with consistency rewards and position-agnostic data reduces verdict flips but still exhibits some residual bias.
- Pointwise-J1, trained from pairwise supervision, is inherently position-consistent and achieves higher position-consistent accuracy, with a lower rate of ties.
- Test-time scaling (sampling multiple generations) further improves consistency and reduces ties for both pairwise and pointwise models.
(Figure 2)
Figure 2: Illustration of the thinking patterns of Pairwise-J1 and Pointwise-J1 during RL training, showing evaluation criteria, reference answers, and comparative reasoning.
(Figure 3)
Figure 3: Test-time scaling increases position-consistent accuracy and decreases tie rate for both pairwise and pointwise models.
Score Distribution Analysis
Pairwise-J1 produces sparser score distributions and larger score differences between chosen and rejected responses, reflecting its comparative training objective. Pointwise-J1, trained with distant supervision, yields finer-grained but less discriminative scores.
(Figure 4)
Figure 4: Distribution of absolute scores and score differences for Pairwise-J1 and Pointwise-J1 on PPE Correctness.
Training Dynamics
Training rewards and thought lengths converge steadily, with pairwise judges generating longer reasoning traces (~500 tokens) compared to pointwise judges (~300–400 tokens).
(Figure 5)
Figure 5: Reward and average generation length during training for different J1-Llama-8B models.
Implementation Considerations
- Data Efficiency: J1 achieves SOTA results with only 22K synthetic preference pairs, compared to hundreds of thousands or millions used by prior models.
- Computational Requirements: Training J1-Llama-8B and J1-Llama-70B requires 8×A100 and 64×A100 GPUs, respectively, with sequence lengths up to 4096 tokens.
- Deployment: J1 models can be deployed for both training-time and test-time evaluation, with further improvements possible via inference-time scaling (e.g., self-consistency).
- Bias Mitigation: Position-agnostic batching and consistency-based rewards are essential for reducing judgment bias in pairwise setups.
- Generalization: J1 demonstrates robust generalization across both verifiable and non-verifiable tasks, making it suitable for broad evaluation pipelines.
Theoretical and Practical Implications
J1 establishes that RL-based optimization of reasoning and judgment, when combined with synthetic data and verifiable rewards, yields superior LLM-as-a-Judge models. The framework enables systematic study of bias mitigation, reward design, and prompt engineering, providing actionable insights for future judge model development. The success of pointwise judges trained from pairwise data suggests new directions for scalable, consistent evaluation.
Future Directions
- Scaling RL Recipes: Extending J1 to larger model sizes and more diverse domains, including multimodal and multilingual tasks.
- Reward Design: Exploring richer reward signals, including human-in-the-loop feedback and adversarial robustness.
- Meta-Judging: Integrating meta-reward models and ensemble methods for further improvements in judgment reliability.
- Automated Prompt Engineering: Systematic optimization of seed prompts to elicit richer and more discriminative reasoning traces.
Conclusion
J1 presents a principled RL-based approach for training LLM-as-a-Judge models, achieving state-of-the-art performance with data-efficient recipes and robust bias mitigation. The framework's flexibility in handling both pairwise and pointwise judgments, combined with strong empirical results, positions J1 as a foundational method for future research in LLM evaluation and alignment.