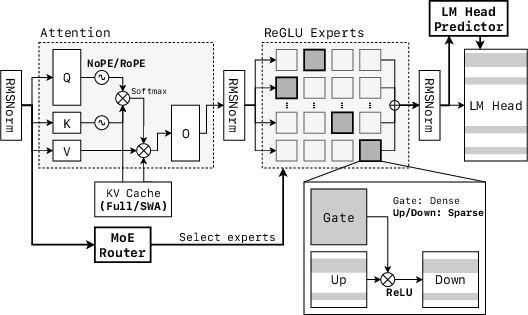
- The paper introduces a new family of LLMs designed from scratch for local deployment by leveraging dual-level structural sparsity and mixture-of-experts architectures.
- The models utilize innovations such as pre-attention routing, expert offloading, and ReGLU-based sparsity to optimize computational resources and achieve competitive MMLU scores.
- The study demonstrates that on-device large language models can attain state-of-the-art performance, paving the way for broader AI accessibility in resource-constrained settings.
SmallThinker: A Family of Efficient LLMs Natively Trained for Local Deployment
Introduction
The paper introduces SmallThinker, a series of LLMs specifically designed for deployment on local devices with limited computational power and storage capabilities. Unlike traditional models that are compressed for local use, SmallThinker is architected from scratch with a deployment-aware design, transforming resource constraints into fundamental design principles. The models achieve state-of-the-art (SOTA) performance, demonstrating the feasibility of local deployment without reliance on GPU-accelerated cloud infrastructure.
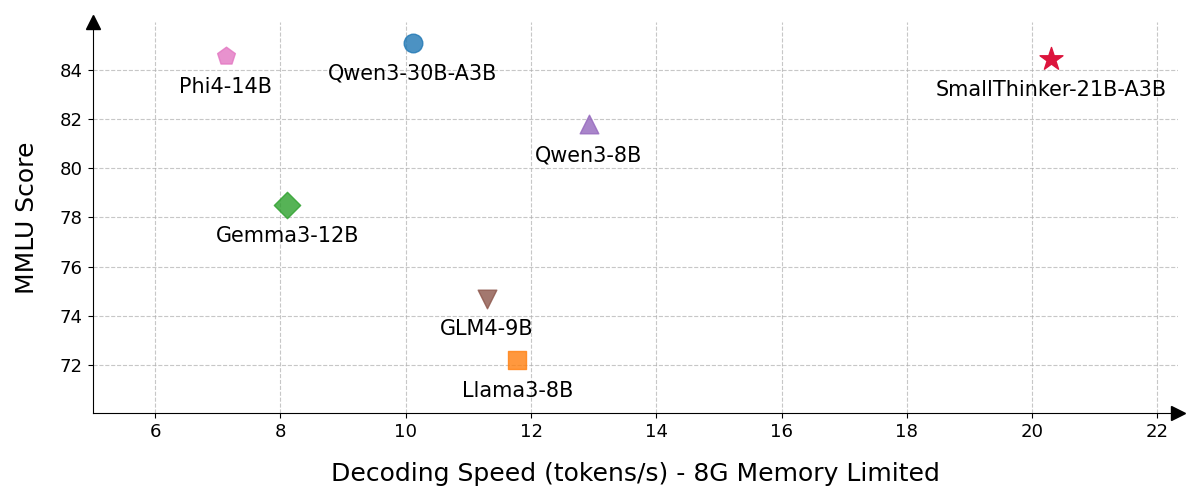
Figure 1: A comparison of inference performance and MMLU scores. SmallThinker achieves SOTA performance, outperforming comparable models in both speed and accuracy.
Model Architecture
The SmallThinker models integrate two-level structural sparsity combining Mixture-of-Experts (MoE) architecture with sparse feed-forward networks. This design drastically reduces computational requirements while maintaining model capacity.
Pre-Training
SmallThinker models are pre-trained using a three-stage curriculum on a comprehensive, high-quality dataset mix, encompassing diverse domains such as General Knowledge, Mathematics, and Code. The training involves progressive adjustment of data composition and integration of both open-source datasets and synthetically generated data.
Pretraining Details
- Data Collection: Sources include FineWeb-Edu, MegaMath, and StackV2 for comprehensive domain knowledge inclusion.
- Synthetic Augmentation: Use of MGA-style and persona-driven methodologies to enrich Mathematics and Code domains.
- Training Setup: SmallThinker-4B-A0.6B utilizes a token horizon of 2.5 trillion tokens while SmallThinker-21B assumes 7.2 trillion tokens, involving structured sequence length adjustments and dynamic learning rate decay.
Model Evaluation
Evaluation on multiple benchmarks indicates SmallThinker models achieve comparable or superior results relative to larger baselines, showcasing excellent parameter utilization.
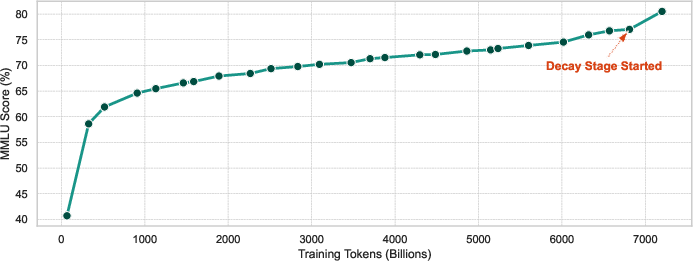
Figure 3: Learning curve of SmallThinker-21B-A3B-Base on the MMLU benchmark, showing 5-shot accuracy vs. training tokens (in billions).
Comparison against models like Gemma3, Qwen3, and Phi4 demonstrates competitive scores across diverse tasks including MMLU, GPQA-Diamond, and HumanEval. Notably, SmallThinker models excel in encoding efficiency and task adaptability.
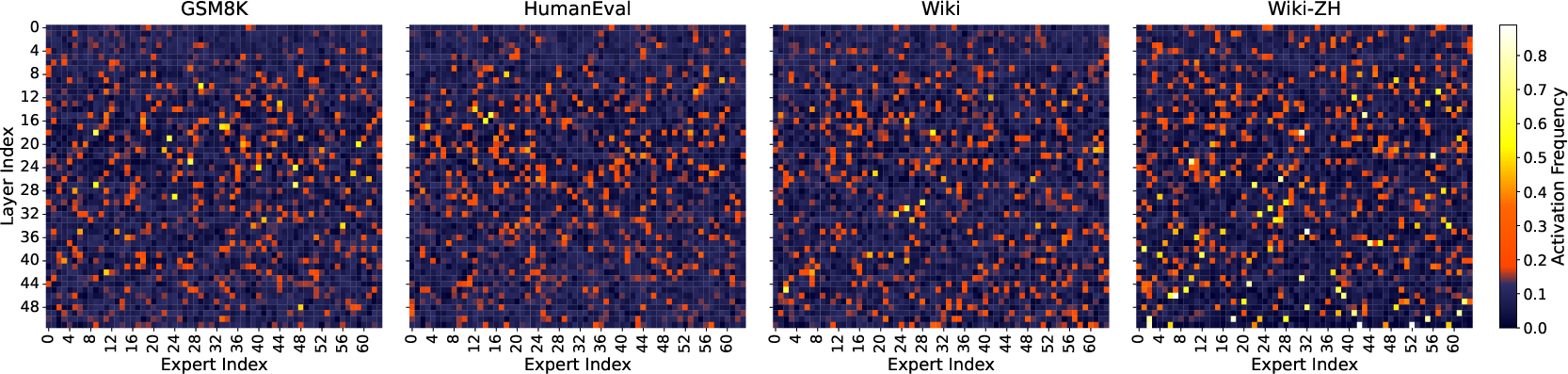
Figure 4: Expert activation frequency heatmaps of SmallThinker-21B-A3B.
Inference Framework for Local Devices
SmallThinker designs emphasize sparse inference strategies and memory-efficient inference for optimal performance on resource-constrained devices.
Memory-Efficient Inference
- Expert Offloading: Implementing parameter offloading mechanism that optimally utilizes SSD storage, guided by expert activation locality.
- Prefetching Techniques: Employ pipeline methodologies to interleave I/O tasks with computational processes, optimizing latency management.
Sparse Inference
- ReGLU Sparsity Optimization: Utilizing selective computation strategies focusing on sparse activation outputs, paired with SIMD vectorization.
- LM Head Sparsity: Predictor module selectively computes logits, minimizing computational demands.
Limitations and Future Work
While effective, the scale of pretraining data constrains SmallThinker's broader applicability. Future efforts include expanding the dataset and implementing RLHF for improved model alignment and response quality.
(Figure 5 and Figure 6)
Figure 5: Expert activation frequency heatmaps of SmallThinker-4B-A0.6B.
Figure 6: The neuron-level sparsity across layers for SmallThinker model family.
Conclusion
SmallThinker showcases a novel approach to AI deployment, providing capable models for local devices that offer significant computational and memory efficiency gains, setting a new pathway for democratizing AI across consumer devices globally. Further improvements will aim to expand its knowledge base and refine its alignment for robust, real-world applications.