- The paper demonstrates how a trainable sparse attention mechanism (InfLLM v2) accelerates long-context processing while reducing computational overhead.
- The paper leverages the UltraClean data strategy and ModelTunnel v2 to optimize training efficiency and minimize resource consumption.
- The paper employs CPM.cu with speculative sampling and quantization techniques to enable real-time performance on resource-constrained devices.
MiniCPM4: Ultra-Efficient LLMs on End Devices
Introduction
The development of the MiniCPM4 focuses on creating an ultra-efficient LLM specifically designed for deployment on end-side devices. This is achieved via advancements across four dimensions: model architecture, training data, training algorithms, and inference systems. Utilizing these innovations, MiniCPM4 becomes capable of effective computation on these devices, proving its efficiency by outperforming open-source models of similar sizes on various benchmarks.
Model Architecture and InfLLM v2
A key innovation in MiniCPM4 is the InfLLM v2 architecture, which implements a trainable sparse attention mechanism designed for accelerating both prefilling and decoding phases, especially for long-context processing.
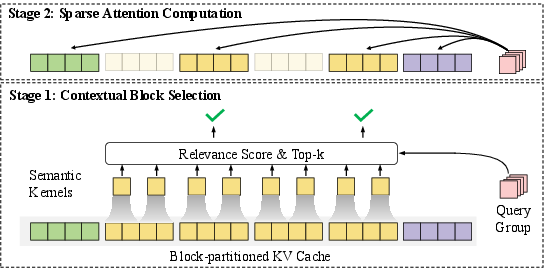
Figure 1: The illustration of InfLLM v2. Each query group selects parts of key-value blocks for attention computation, where the initial tokens and local tokens in the sliding window are always selected.
InfLLM v2 optimizes sparse attention by selecting contextual tokens dynamically through a block-level relevance scoring method, significantly reducing computation and memory demands compared to dense attentions. By computing attention using only a subset of relevant tokens, the model achieves a balance between processing speed and complexity.
Training Data and UltraClean
Efficient training of MiniCPM4 involves the UltraClean data strategy, which emphasizes high-quality data filtering and generation to enhance model learning within a constrained training token budget.
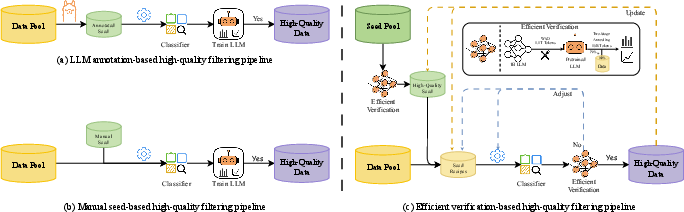
Figure 2: The illustration of high-quality data filtering pipelines. Traditional model-based data filtering methods (a) and (b) rely on human expertise for seed data selection and lack data quality verification.
UltraClean introduces a model-based verification strategy using nearly-complete models as evaluators to select high-quality seed data. This ensures better quality data, contributing to improved model performance and reduced training costs. The data cleaning and generation process, including UltraFineWeb and large-scale data synthesis, result in effective model performance despite using significantly fewer training tokens than comparative models.
Training Algorithms and ModelTunnel v2
ModelTunnel v2 refines the hyperparameter search process, using ScalingBench as a performance indicator to optimize training strategy. This is especially useful for determining optimal training configurations without exhaustive computational resources.
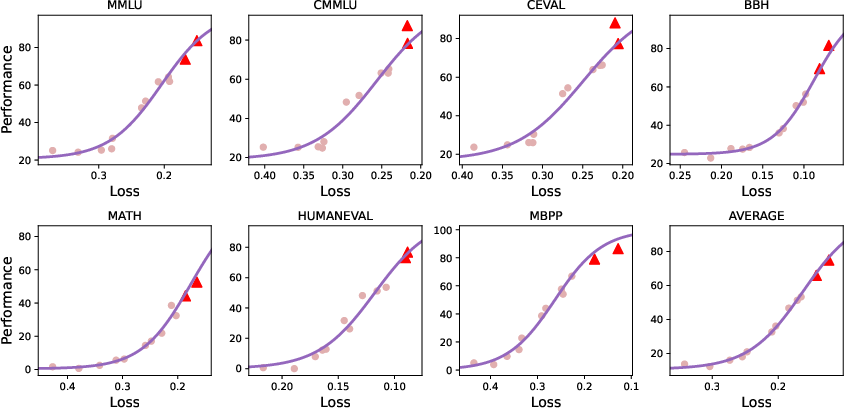
Figure 3: The sigmoid relationship between loss and downstream performance on ScalingBench.
The introduction of ScalingBench allows determining hyperparameters that translate well across model sizes, enhancing predictive scaling and reducing trial-and-error in large-scale LLM training programs. Additionally, employing load-balanced reinforcement learning and quantization-aware strategies, MiniCPM4 efficiently handles limited-resource environments without compromising performance.
Inference Systems and CPM.cu
The CPM.cu inference system enhances MiniCPM4's real-time processing capabilities on end devices by integrating sparse attention, speculative sampling, and quantization techniques.

Figure 4: The illustration of FR-Spec, which requires the draft model to use a reduced vocabulary subset.
FR-Spec, a key component of CPM.cu, involves a vocabulary reduction technique during speculative sampling, reducing the computational load during inferences. This allows MiniCPM4 to maintain high accuracy while operating efficiently within constrained resource settings.
Applications and Long-Context Processing
MiniCPM4 is optimized for applications requiring robust long-context processing capabilities, demonstrated by its superior performance on long sequence evaluations.
Figure 5: The evaluation results for long sequence prefilling.
This capacity extends MiniCPM4's usability across various domains, including tool use with model context protocol for agent-centric tasks and trustworthy survey generation, showcasing its adaptability and utility in complex real-world scenarios.
Conclusion
MiniCPM4 represents a significant step forward in making LLMs accessible and efficient for broader deployment on consumer devices. Through innovations in attention mechanisms, training data strategies, and system architecture, it demonstrates how high-performance models can be integrated into real-world applications without incurring prohibitive computational costs. Future work will continue to explore enhancements in model capabilities and resource efficiency.