- The paper introduces a novel LLM architecture that integrates brain-inspired hybrid attention, MoE, and adaptive spiking neurons for efficient long-context processing.
- It employs a conversion-based training paradigm with continual pre-training and multi-stage fine-tuning to achieve over 100× speedup and competitive benchmark performance.
- The models demonstrate significant energy savings and scalability, reducing energy consumption by up to 97.7% compared to traditional FP16 and INT8 MAC approaches.
SpikingBrain: Brain-Inspired Large Models for Efficient Long-Context Training and Inference
Introduction
SpikingBrain introduces a family of LLMs that integrate brain-inspired mechanisms—hybrid efficient attention, Mixture-of-Experts (MoE) modules, and spike encoding—into their architecture. The models are designed to address the computational and memory bottlenecks of mainstream Transformer-based LLMs, particularly for long-context processing and deployment on non-NVIDIA hardware. SpikingBrain leverages a conversion-based training pipeline, adaptive spiking neurons, and system-level optimizations for the MetaX GPU cluster, demonstrating stable large-scale training and inference with less than 2% of the data typically required for comparable open-source models.
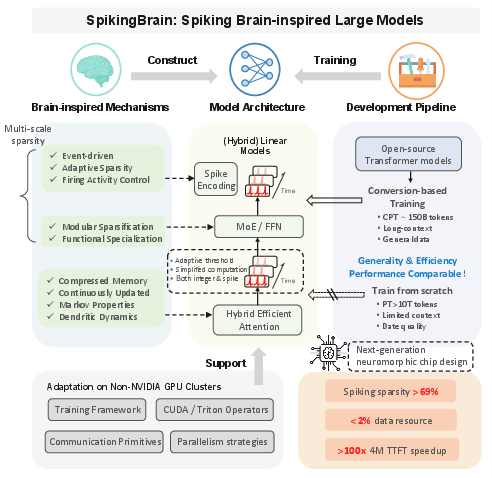
Figure 1: Overview of SpikingBrain, highlighting hybrid attention, MoE, spike encoding, and hardware adaptation for efficient training and inference on MetaX clusters.
Model Architecture
Hybrid Attention Mechanisms
SpikingBrain models employ a combination of linear, sliding window, and full softmax attention modules. Linear attention provides O(n) complexity and constant memory usage, while sliding window attention captures local dependencies efficiently. Hybridization is realized in two paradigms:
- Inter-layer sequential hybridization (SpikingBrain-7B): Alternates linear and SWA layers for purely linear complexity.
- Intra-layer parallel hybridization (SpikingBrain-76B): Combines linear, SWA, and full attention within layers, with outputs normalized for stability.
The Gated Linear Attention (GLA) module enhances expressivity via gating vectors, supporting recurrent state updates analogous to dendritic dynamics in biological neurons.
Mixture-of-Experts (MoE)
SpikingBrain-76B incorporates sparse MoE layers, with 16 routed experts and 1 shared expert per layer, activating only a subset of parameters per token. Upcycling techniques replicate dense FFN weights across experts, maintaining initial equivalence and enabling specialization during training. Seven dense FFN layers are retained for stability.
Adaptive Spiking Neurons
The models utilize adaptive-threshold spiking neurons, simplifying the LIF model by removing the decay factor and introducing a dynamic threshold proportional to the mean absolute membrane potential. This ensures balanced firing rates, prevents over-excitation/quiescence, and supports efficient conversion of activations to integer spike counts.
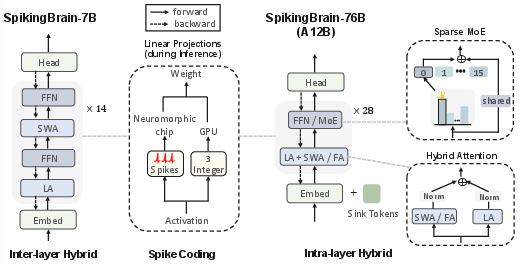
Figure 2: Integrated architectures of SpikingBrain-7B (linear, inter-layer hybridization) and SpikingBrain-76B (hybrid-linear MoE, intra-layer hybridization), with spike coding for hardware compatibility.
Training Paradigm
Conversion-Based Training
SpikingBrain leverages a multi-stage conversion pipeline:
- Continual Pre-Training (CPT): Transfers attention patterns from pre-trained Transformer checkpoints to efficient attention variants, progressively extending context length (8k → 32k → 128k) with only ~150B tokens.
- Supervised Fine-Tuning (SFT): Three-stage alignment for general knowledge, dialogue, and reasoning, using domain-specific datasets.
Attention map correspondence enables direct initialization of QKV projections from softmax attention models, with lightweight training adapting to local/low-rank variants. Non-negative activations and low-rank normalization ensure stable convergence.
MoE Upcycling
Dense FFN weights are replicated across experts, with output scaling to maintain consistency. Stochastic routing and data noise drive expert specialization, while shared experts stabilize training.
Spiking-Driven LLMs
Spiking Scheme
Activations are converted to integer spike counts via adaptive-threshold neurons, then expanded into sparse spike trains for event-driven computation. Three spike coding schemes are supported:
- Binary ({0,1}): Simple, low overhead, but high firing rate for large counts.
- Ternary ({−1,0,1}): Bidirectional, halves firing rate and time steps, aligns with biological excitation/inhibition.
- Bitwise: Expands counts into binary bits, compresses time dimension, optimal for high-precision, low-power scenarios.
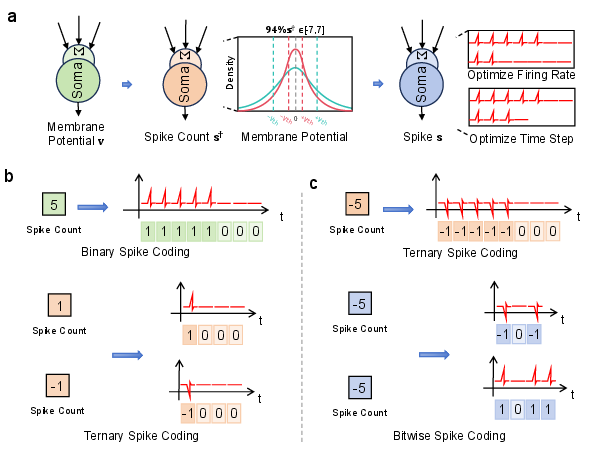
Figure 3: Schematic of binary, ternary, and bitwise spike coding schemes, illustrating temporal compression and sparsity.
Hardware Adaptation
Spike coding is compatible with GPU execution (single-step integer formulation) and event-driven neuromorphic hardware (expanded spike trains). Deployment on asynchronous hardware maximizes energy efficiency, as computation is triggered only by spike events.
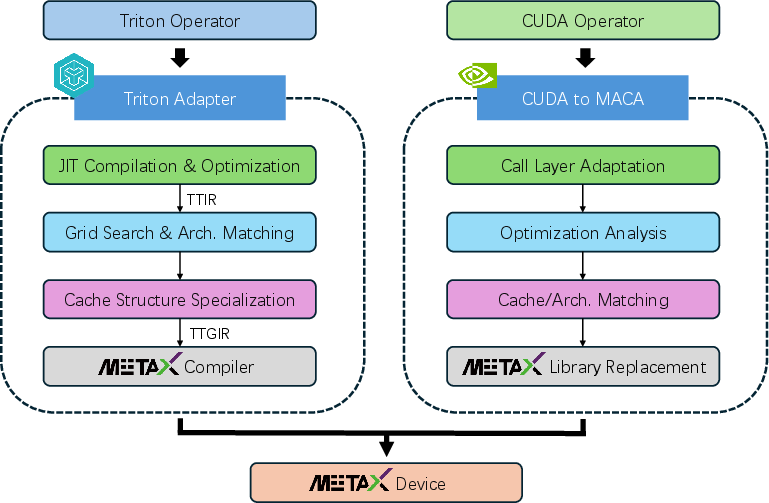
Distributed Training and Operator Adaptation
MetaX-specific optimizations include:
Parallel Topologies
SpikingBrain models employ data, pipeline, expert, and sequence parallelism, with ZeRO and activation recomputation for memory efficiency. Sequence parallelism (DeepSpeed Ulysses, ZeCO, LASP-2) enables scalable long-context training and inference.
Results
SpikingBrain-7B recovers ~90% of base model performance across benchmarks (MMLU, CMMLU, ARC-C, HS, Ceval), matching advanced linear and hybrid models. SpikingBrain-76B closes the gap further, achieving results comparable to Llama2-70B, Mixtral-8×7B, and Gemma2-27B, despite activating fewer parameters.
Long-Context Efficiency
SpikingBrain-7B achieves over 100× speedup in TTFT for 4M-token sequences under sequence parallelism, with constant time overhead as sequence length and GPU count scale. Inference latency and throughput are consistently superior to baselines across frameworks and hardware.
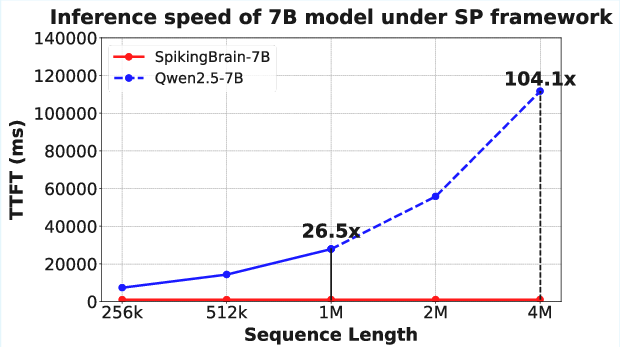
Figure 5: TTFT comparison under sequence parallelism, demonstrating SpikingBrain-7B's scalability and efficiency for ultra-long sequences.
CPU-Side Inference
Compressed 1B-scale SpikingBrain models deployed on CPUs (llama.cpp backend) maintain constant decoding speed as output length increases, outperforming Llama3.2-1B by up to 15.39× at 256k sequence length.
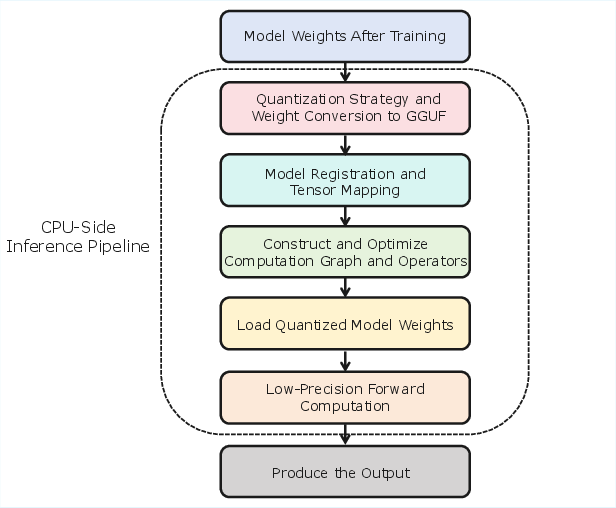
Figure 6: Overview of the CPU-side inference pipeline, detailing conversion, registration, optimization, and quantized inference steps.
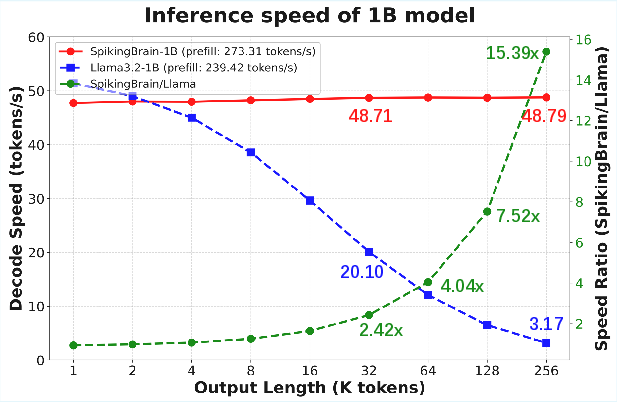
Figure 7: Decoding speed comparison for SpikingBrain-1B and Llama3.2-1B on CPU, highlighting stable throughput and memory efficiency.
Spiking Scheme Analysis
Bitwise-ternary spike coding yields 69.15% sparsity, with 18.4% of channels inactive during inference. Performance degradation from spiking and INT8 quantization is limited to ~2%. Energy consumption is reduced by 97.7% (vs. FP16 MAC) and 85.2% (vs. INT8 MAC), with average MAC energy cost of 0.034 pJ.
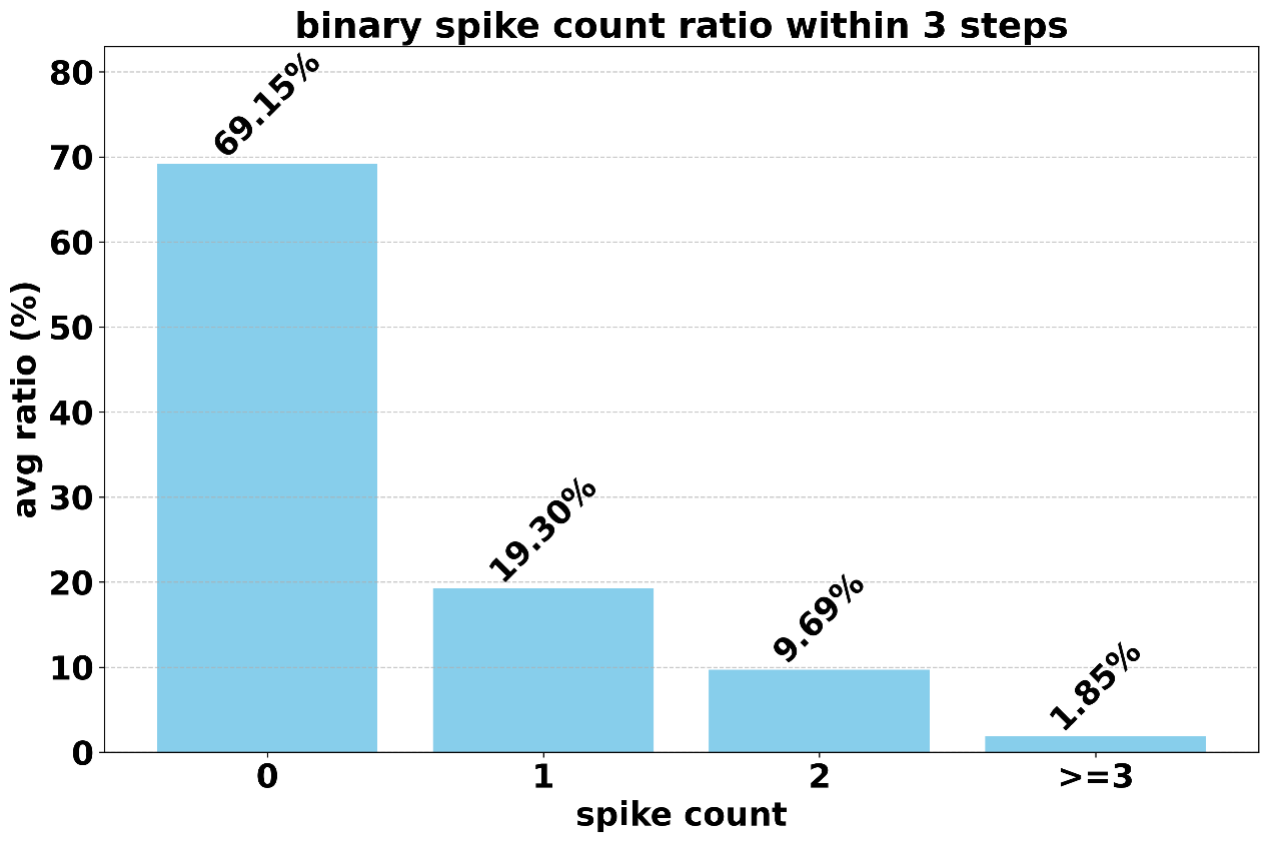
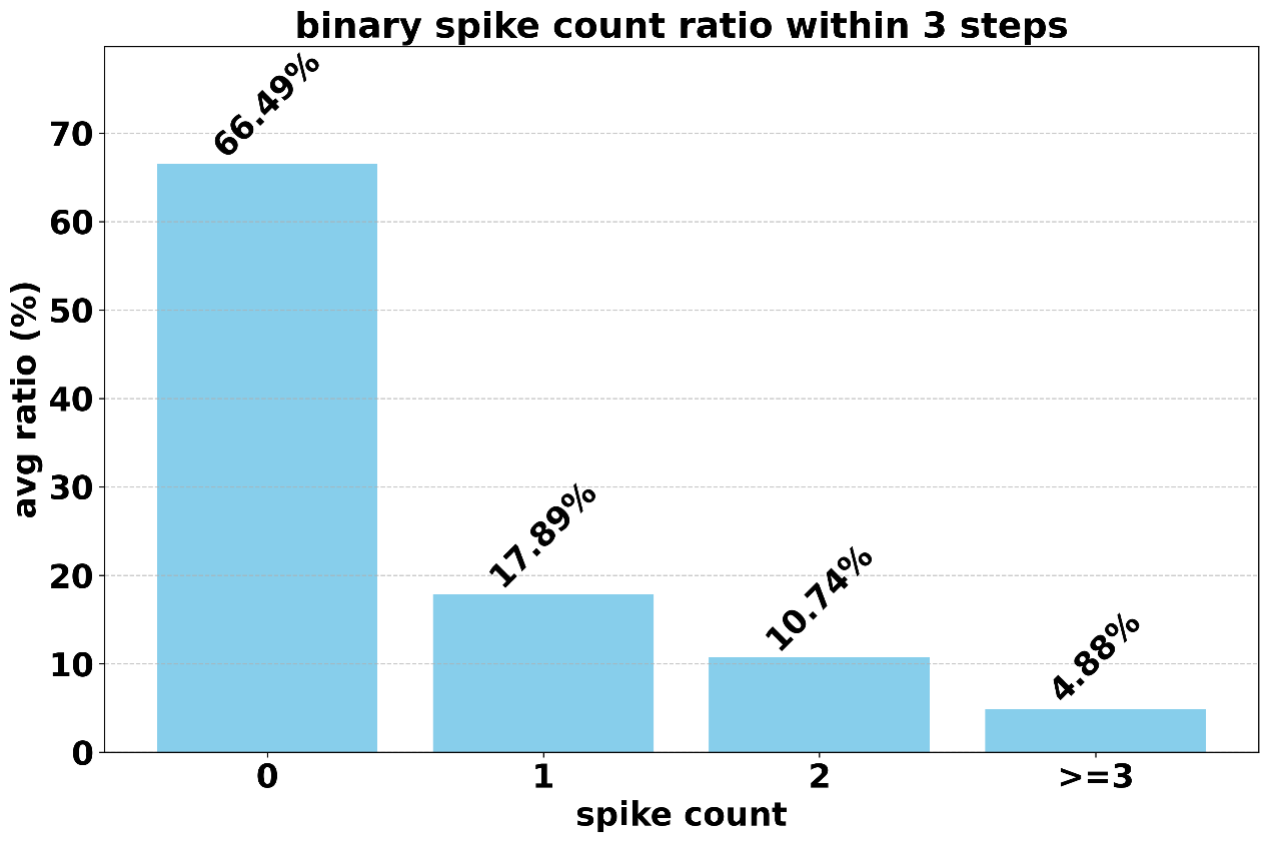
Figure 8: Spike counts distribution for SpikingBrain-7B and SpikingBrain-76B under bitwise spike coding.
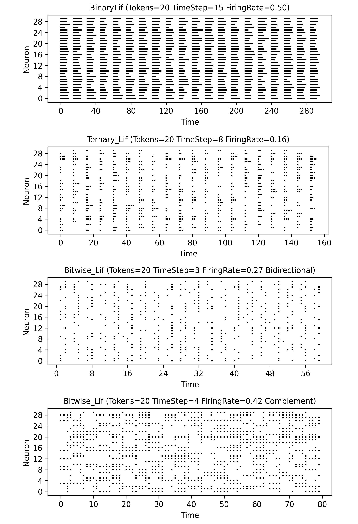
Figure 9: Time–neuron firing maps for binary, ternary, and bitwise spike coding, visualizing sparsity and temporal compression.
Conclusion
SpikingBrain demonstrates the practical integration of brain-inspired mechanisms into large model architectures, achieving efficient long-context training and inference on non-NVIDIA hardware. The models deliver competitive performance with minimal data, order-of-magnitude speedups, and substantial energy savings via spiking-driven computation. These advances provide a reference for future neuromorphic hardware and scalable deployment of efficient LLMs, with implications for both theoretical model design and real-world applications in resource-constrained environments.