- The paper demonstrates that LLMs form internal structures analogous to human understanding through a three-tiered framework.
- It employs techniques like sparse autoencoders and linear probing to uncover latent features and track dynamic factual relationships.
- The study shows that LLMs transition from rote memorization to principled reasoning by revealing underlying computational circuits.
Mechanistic Indicators of Understanding in LLMs
Recent advances in mechanistic interpretability (MI) challenge the notion that LLMs such as GPT-3 simply function by identifying superficial statistical patterns in texts. This paper presents findings suggesting that LLMs have internal structures functionally analogous to human understanding, particularly understanding that involves recognizing connections. By proposing a three-tiered conception of understanding, the paper argues for a nuanced perspective on machine intelligence. The tiers include conceptual understanding, state-of-the-world understanding, and principled understanding, each reflecting different ways LLMs synthesize and apply learned information.
Conceptual Understanding
Conceptual understanding involves the development of internal representations, or "features," analogous to human concepts. LLMs trained for @@@@2@@@@ derive benefits from forming such features, as they enable the models to unify diverse input manifestations under a single representation. For example, a "Golden Gate Bridge" feature emerges within the model, allowing it to consistently interpret references to the bridge across various contexts, languages, and modalities (Figure 1).

Figure 1: Deep learning model activations as vectors in latent spaces. (a) The activations at one layer of a DL model can be conceptualized as a vector picking out a point in a latent space. The latent space has as many dimensions as there are nodes in the layer. (b) In these latent spaces, and as a result of the training stage, inputs are effectively differentiated along certain directions; each direction corresponds to a learned feature of the input space. When an input produces an activation vector picking out a point within that space, the position of this point along such a direction reflects how strongly that feature is present in the input.
The concept of features as directions in latent space provides insight into how LLMs differentiate inputs non-linearly by associating them with task-relevant abstractions. Superposition permits models to encode more features than neurons through feature overlap, enhancing overall representational capacity. Sparse autoencoders can help disentangle superposed features, revealing latent conceptual structures (Figure 2).
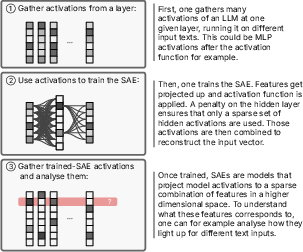
Figure 2: Steps to discover features in LLMs using Sparse autoencoders (SAEs). The idea is to train a sparse autoencoder to project activations of an LLM to a sparse combination of features picked from a very large set of possible features (steps 1 and 2). Often---but by no means always---these features end up corresponding to human-interpretable concepts (which one can determine with step 3).
State-of-the-World Understanding
State-of-the-world understanding signifies grasping factual relationships between features beyond mere conceptual associations. LLMs can form internal models that dynamically track changes in the environment, as demonstrated by Othello-GPT, which constructs and updates board states using sequence-based learning (Figure 3). This showcases the capacity to learn and maintain complex interrelationships akin to forming a dynamic but integrated understanding that reflects external states.

Figure 3: Probing board states from Othello-GPT. The model is asked to predict legal moves given the sequence of moves that led to the board state shown in (a). Legal moves have to use a disc of the player whose turn it is (here: black) and place that disc on a previously empty square in such a way as to “sandwich” the opponent’s discs (here: white) between the player’s own discs. This can be done horizontally, vertically, or diagonally—“D6,” for example, is a legal move for black here. (b) As the model processes previous moves, 64 separately trained linear probes each correctly predict the state of one of the 64 board squares from the residual stream (and this works at various locations of the stream, e.g., after 4, 5 or 6 transformer blocks).
Principled Understanding
Principled understanding reflects the ability to uncover underlying rules or generative principles that connect disparate facts and facilitate generalization. The discovery of circuits, such as the Fourier multiplication algorithm for modular addition, illustrates how models transition from rote memorization to computational principles (Figure 4).
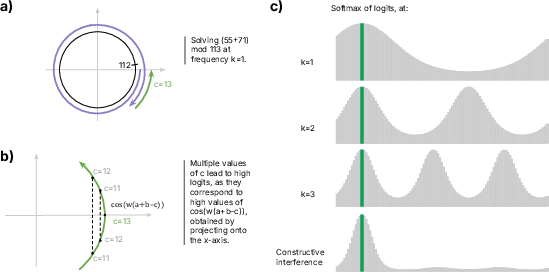
Figure 4: The two advantages of the Fourier multiplication algorithm: the circle-wrapping trick and the constructive interference trick. (a) The circle-wrapping trick exploits the periodicity of the cosine function. When performing 55 + 71, the model adds the corresponding angles on the unit circle. This results in a total rotation of 126 steps. The angle wraps around the circle once, and, when it passes step 112, resets to zero—finally landing at position c = 13. (b) However, because the cosine function is relatively flat near its maximum, neighboring values of c also receive high logit scores, making the algorithm less precise. At frequency k = 1, the cosine peaks at the correct value (high accuracy) but has a broad profile (low precision). (c) As the frequency k increases (e.g., k = 2 or k = 3), the angle wraps around the unit circle k times faster. This creates k distinct peaks: while each peak becomes sharper (indicating higher precision), the model becomes less accurate overall, since it now has multiple plausible candidate values for the answer. When k > 1, the model is effectively performing the addition modulo P / k rather than modulo P. For example, at k = 2, the model not only peaks at the correct value (e.g., c = 13), but also at the value P / 2 (e.g., if P = 113, the second peak appears around 113 / 2). By combining signals from multiple frequencies, the model achieves constructive interference, reinforcing the correct output while canceling out others---thus achieving both high precision and high accuracy.
This emergent circuit exemplifies a sophisticated form of understanding, transcending direct memorization, thereby embodying generative principles applicable to novel instances not encountered during training.
Conclusion
The detailed study of mechanistic patterns and interpretability of LLMs unveils a complex cognitive framework emphasizing a level of understanding beyond simple statistics. Although differing from human cognition, these models manifest forms analogous to conceptual, factual, and principled understanding, underscoring their emergent capacities in navigating and interpreting linguistic patterns. Moving forward, discussions on machine understanding must explore these findings, taking into account their implications for AI development and deployment while considering their unique structural and computational nature.