Are LLMs Smarter Than Chimpanzees? An Evaluation on Perspective Taking and Knowledge State Estimation
Abstract: Cognitive anthropology suggests that the distinction of human intelligence lies in the ability to infer other individuals' knowledge states and understand their intentions. In comparison, our closest animal relative, chimpanzees, lack the capacity to do so. With this paper, we aim to evaluate LLM performance in the area of knowledge state tracking and estimation. We design two tasks to test (1) if LLMs can detect when story characters, through their actions, demonstrate knowledge they should not possess, and (2) if LLMs can predict story characters' next actions based on their own knowledge vs. objective truths they do not know. Results reveal that most current state-of-the-art LLMs achieve near-random performance on both tasks, and are substantially inferior to humans. We argue future LLM research should place more weight on the abilities of knowledge estimation and intention understanding.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple but deep question: can today’s AI LLMs understand what other people know and make decisions from their point of view? Humans are very good at this, and it’s a big part of what makes us different from animals like chimpanzees. The authors build two story-based tests to see whether AI models can:
- Spot when a character “magically” knows something they shouldn’t.
- Predict what a character will do next based only on what that character actually knows (not on what the reader or narrator knows).
What the researchers wanted to find out
In easy terms, the paper explores two questions:
- Can AI tell when a story has a “plot hole” where a character uses knowledge they could not possibly have?
- Can AI choose the next action a character would realistically take, based on the character’s own knowledge, not secret information the character doesn’t have?
These skills are part of “theory of mind,” which is the ability to understand that other people have their own thoughts, beliefs, and knowledge that may be different from yours.
How they tested it
The researchers created two short, story-based tasks:
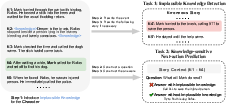
- Task 1: Implausible Knowledge Detection (IKD)
- Think of this like “spot the plot hole.” The model reads a short story and must say if it contains a mistake where a character knows something they shouldn’t. If it says “yes,” it also has to point to the exact sentence(s) where the mistake happens.
- Task 2: Knowledge-sensitive Next-action Prediction (KNP)
- Imagine a character is looking for a treasure. The story includes a line that reveals the exact location, but the character never learned that info. The model must choose the character’s next move based on what the character actually knows (so, not walking straight to the treasure unless they had a reason).
How they built the data:
- They collected 500 short stories from open websites across five genres (romance, fantasy, kids, mystery, sci-fi).
- They used an AI to rewrite some stories to include a “plot hole” about impossible knowledge, then had human editors check and refine them.
- For IKD: 1,000 stories total (500 correct, 500 with a knowledge error), average length ~588 words.
- For KNP: 500 short story-question pairs, average length ~98 words, with two answer choices for the next action.
- Humans also took the tests to provide a baseline for comparison.
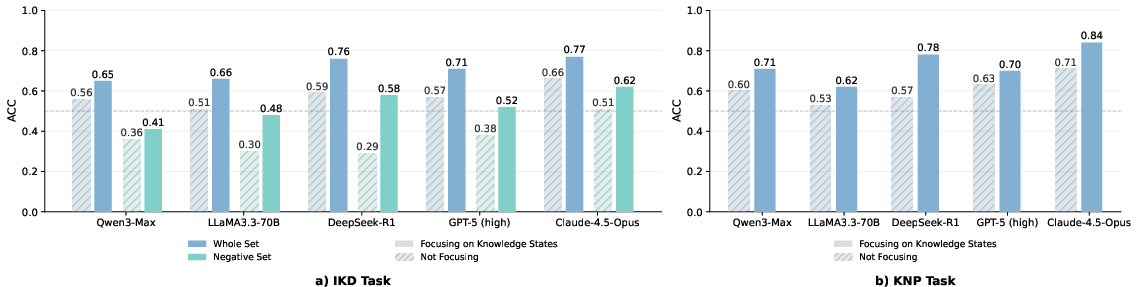
They tested many leading AI models without giving them examples first (zero-shot), and asked them to show their reasoning. They also tried prompts that explicitly told models to pay attention to what each character knows.
What they found and why it matters
Main results:
- On both tasks, most AI models performed close to random guessing (about 50%).
- Humans did much better:
- KNP: humans ~92% vs. best model ~71% (Claude-4.5-Opus and Gemini-3-Pro were top, but still well below humans; some models were near chance).
- IKD (error detection): best model ~66% vs. humans ~76% on classification. When humans were shown exactly where to look, they got even better at pinpointing the error.
- Making models “think longer” or be larger didn’t reliably fix the problem. Bigger size and longer chain-of-thought weren’t enough.
- Explicitly telling models to focus on character knowledge improved scores by about 12 percentage points on average—but they still lagged behind humans.
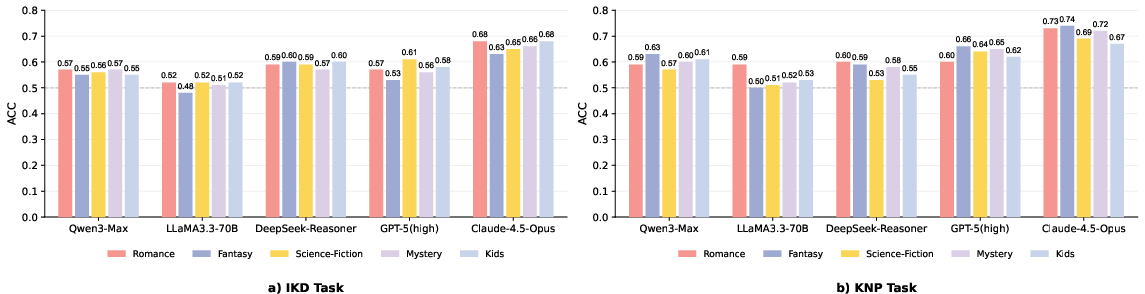
- Genre (romance, fantasy, etc.) didn’t change the results much, though fantasy was a bit trickier because models sometimes excused things as “magic.”
Why this matters:
- The tests are short and simple, yet they stump top models. That suggests a real gap in models’ ability to track “who knows what”—a key part of human social intelligence.
- If AI can’t reliably reason from a character’s or person’s perspective, it may struggle with tasks like giving helpful advice, understanding misunderstandings, following multi-person instructions, or being a good educational or social assistant.
What this means going forward
This research shows that, despite impressive scores on many benchmarks, today’s AI models often fail at a basic human skill: tracking knowledge states and using them to predict actions. That’s a building block of theory of mind and “understanding and sharing intentions.”
Implications:
- AI training should focus more on perspective-taking—explicitly teaching models to separate “what is true” from “what a specific person knows or believes.”
- Better datasets and methods are needed to help models learn to follow what each character (or user) can see, hear, and know across time.
- Improving this skill could make AI more trustworthy and useful in social, educational, and collaborative settings, where understanding others’ viewpoints is essential.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concise list of what remains missing, uncertain, or unexplored in the paper, framed as actionable gaps for future research.
- Dataset construction relies heavily on LLM-generated rewrites (GPT-5) to insert implausible knowledge, introducing potential style and distribution artifacts that may advantage or disadvantage certain models; quantify and mitigate generator-induced bias (e.g., by multi-generator diversity, human-only rewrites, adversarial de-stylization).
- Implausible knowledge is defined and validated qualitatively; formalize a taxonomy (e.g., private thoughts, offstage events, future events, identity recognition, spatial knowledge) and report per-type performance to pinpoint specific failure modes.
- Human validation details are sparse (no inter-annotator agreement, limited sample sizes); measure annotator agreement (e.g., Cohen’s κ), expand to more annotators, and publish detailed guidelines to improve reliability.
- Human baselines are underpowered (two annotators, 50 items per task) and not statistically analyzed; increase sample sizes, compute confidence intervals, and conduct significance tests to robustly estimate the human–LLM gap.
- Accuracy-only reporting obscures uncertainty; add statistical analyses (CIs, hypothesis tests), per-model variance across runs (multiple seeds), and calibration diagnostics (e.g., probability scores, ROC curves).
- Localization evaluation uses word-level IoU on free-form text spans, which may penalize paraphrases; compare extraction-based metrics (character-level F1 on span indices) and semantic overlap metrics (embedding-based).
- Binary-choice KNP may contain lexical or positional biases despite randomization; run controlled experiments on option symmetry (length, salience, polarity, verb framing), adversarially matched distractors, and report bias diagnostics.
- LLM-as-a-Judge for open-ended KNP uses GPT-5 without human verification; validate judge reliability (human adjudication on a subset, inter-judge agreement), and test multiple judges to assess robustness.
- Zero-shot-only evaluation limits insight; systematically test few-shot, self-consistency, structured reasoning (e.g., program-of-thought), and explicit perspective-tracking prompts to characterize sensitivity to prompting strategies.
- Extended reasoning was concluded ineffective without controlled ablations (e.g., varying depth, planning scaffolds, constraint checking); design targeted reasoning curricula to test whether structure-aware thinking improves KSTE.
- No fine-tuning or architectural interventions were explored; evaluate specialized training (synthetic curricula for knowledge-state tracking, perspective datasets), memory modules, belief-state representations, or multi-agent simulation-based training.
- Convergent validity with existing ToM benchmarks is not assessed; measure correlations with standard false-belief, belief attribution, and multi-agent tasks to establish whether IKD/KNP truly probe ToM dimensions.
- The link from KSTE to USI (intention understanding) is hypothesized but not tested; add tasks that directly assess intention inference contingent on knowledge states, and analyze whether KSTE performance predicts intention prediction accuracy.
- Cross-genre effects are reported but not deeply analyzed; extend analyses to controlled genre-specific manipulations (e.g., fantasy with explicit no-magic constraints), and per-genre knowledge-type breakdowns.
- Language and cultural scope is limited to English narratives; evaluate cross-lingual performance and culturally diverse stories where knowledge plausibility norms differ, and assess transfer across languages.
- Context length is a confound (IKD ~588 words vs. KNP ~98 words); systematically vary context length and narrative complexity to separate long-context retrieval from knowledge-state tracking difficulty.
- Bias tendencies (e.g., GPT-4o defaulting to “consistent,” Gemini to “inconsistent”) are observed but not probed; conduct calibration experiments, threshold adjustments, and meta-prompting to correct prior biases.
- Failure analysis is broad; provide granular error taxonomy (e.g., mislocalizing knowledge statement vs. misattributing access vs. failing causal implication), with per-category breakdowns and representative cases.
- Distinguishing commonsense planning from knowledge-state tracking is not addressed; design controls where both options are equally plausible absent the implausible knowledge, isolating dependence on perspective-taking.
- Real-world generalization is unknown; test KSTE on dialogues, interactive tasks, multi-turn settings, and multi-agent games where knowledge access is dynamic and partial, not narrative-only.
- Multimodal settings are not considered; evaluate whether visual or audio context (e.g., who could see/hear an event) affects KSTE and whether multimodal LLMs handle perspective constraints better.
- Dataset balance (IKD 50/50, KNP always containing an implausible knowledge element) may not reflect real-world distributions; assess performance under skewed base rates and report effects on calibration and decision thresholds.
- Reproducibility details are incomplete (data/code availability, prompts in Appendix only); publish full datasets, generation/validation prompts, seeds, and evaluation scripts to enable independent replication.
- Potential training-set contamination is unaddressed (models may have seen original sources); estimate overlap and control for contamination (e.g., using held-out sources, stylometric checks).
- Judge and generator model overlap (GPT-5 used for generation and judging) risks circularity; use disjoint models for generation and evaluation, and report whether results change under alternative judges/generators.
- The title’s chimpanzee comparison is rhetorical; if the goal is cross-species benchmarking, map IKD/KNP to established animal ToM paradigms (e.g., knowledge/seeing), and compare with published animal performance.
- Safety and societal implications of improving USI/KSTE (e.g., privacy inference risks) are mentioned in related work but not analyzed; add a section on potential misuse, guardrails, and ethical evaluation protocols.
- Theoretical grounding could be strengthened; explicitly align IKD/KNP components with specific USI/ToM constructs (e.g., belief access, ignorance attribution, intention–means reasoning), and formalize expected inference steps.
- Architectural/mechanistic explanations for failures are missing; probe internal representations (e.g., belief state tracking probes, attention to knowledge sources), causal tracing, and interventions that improve source attribution.
- Exploration of simple, rule-based baselines is absent; implement heuristic baselines (e.g., “if knowledge source not mentioned, mark inconsistent”) to calibrate task difficulty and benchmark LLM gains over trivial strategies.
- Robustness across randomness and decoding settings (temperature, top-p) is not reported; evaluate multiple decoding regimes and show stability/variance of results to ensure conclusions are not hyperparameter-specific.
Glossary
- Ablation: An experimental manipulation where components or conditions are removed or varied to isolate their effects. "Ablation 1: We explicitly highlight the erroneous event and instruct the model to identify whether it contains a logical inconsistency."
- Adversarial: Designed or found to cause models to fail or perform poorly, often by exploiting weaknesses. "the proposed benchmarks turn out to be highly adversarial to state-of-the-art LLMs."
- Chain-of-thought reasoning: An approach where models generate intermediate reasoning steps before giving an answer. "Chain-of-thought reasoning does not show clear advantage."
- Counterfactual assumption: Assuming an alternative (non-actual) condition to analyze its implications. "we rewrite event under the counterfactual assumption that the character possesses the identified implausible knowledge"
- Distractor: A deliberately plausible but incorrect option in a multiple-choice question. "We provide two candidate answers: a correct option and a distractor."
- Ex ante: Refers to predictions or assessments made before the outcome is known. "the KNP task (Sec \ref{sec:task2}) focuses on the prediction of next actions ex ante."
- Ex post: Refers to analyses or detections made after the outcome has occurred. "The IKD task (Sec \ref{sec:task1}) focuses on the detection of actions that depend on implausible knowledge ex post"
- False-belief test: A classic Theory-of-Mind assessment that evaluates understanding of others’ incorrect beliefs. "Most follow the false-belief test \cite{baron1985does},"
- Indicator function: A function that returns 1 if a condition holds and 0 otherwise, used in metrics and probability. "and $\mathbbm{1}(\cdot)$ is the indicator function."
- Implausible Knowledge Detection (IKD): A task to detect whether a character uses knowledge they should not have. "For the IKD task, we rewrite the original event to generate an erroneous story;"
- Intersection-over-union (IoU): A set-overlap metric, here used to measure overlap between predicted and true error spans. "compute the intersection-over-union (IoU) with the ground truth at the word level."
- Knowledge-sensitive Next-action Prediction (KNP): A task requiring prediction of a character’s next action based on what they plausibly know. "The Knowledge-sensitive Next-action Prediction (KNP) task, where the implausible knowledge is highlighted for easy reading"
- Knowledge state tracking and estimation (KSTE): Inferring and following what different agents know throughout a narrative or interaction. "we propose to evaluate a prerequisite skill, knowledge state tracking and estimation (KSTE)."
- LLM-as-a-Judge: An evaluation method where a LLM assesses generated answers for correctness. "then apply the LLM-as-a-Judge method \cite{li2024llms} for open-ended evaluation."
- Localization: Identifying and pinpointing the specific part of a text where an error or target phenomenon occurs. "In the localization subtask, if the LLM determines the story to be logically inconsistent, it must localize the error by identifying the error-inducing sentences ."
- Long-context understanding: Model capability to comprehend and reason over very long inputs. "Comparison between several datasets relying on long-context understanding, theory-of-mind, and narrative understanding"
- Out-of-distribution (OOD): Data or settings that differ from those seen during training, often challenging generalization. "free-form narratives offer more diverse and potentially out-of-distribution assessments for ToM"
- Percentage points (pp): An absolute difference between percentages, not a relative percent change. "21 percentage points (pp) above the best LLM, Claude-4.5-Opus."
- Positional bias: A tendency of models to favor answers based on their position (e.g., first or second option) rather than content. "we randomly shuffle the position of correct and distractor answers to avoid positional bias in LLMs."
- Temperature (sampling): A decoding hyperparameter controlling randomness in probabilistic generation. "For temperature and top-p settings, we apply the default settings for all open-source models and closed-source APIs."
- Test-time scaling: Increasing compute or reasoning steps at inference time to improve performance. "cannot simply be resolved through test-time scaling and requires specialized training."
- Theory of Mind (ToM): The capacity to attribute mental states (beliefs, desires, knowledge) to others and reason about them. "A popular view there is that humans possess an advanced theory of mind (ToM)"
- Top-p: Nucleus sampling; a decoding method that samples from the smallest set of tokens whose cumulative probability exceeds p. "For temperature and top-p settings, we apply the default settings for all open-source models and closed-source APIs."
- Understanding and Sharing Intentions (USI): A cognitive capacity to grasp and align with others’ goals and intentions. "we propose an important dimension of LLM evaluation: the ability to understand and share intentions (USI) of humans."
- Zero-shot setting: Evaluating a model on tasks without providing task-specific training or examples. "We test the LLMs using the zero-shot setting."
Practical Applications
Practical Applications of the Paper’s Findings, Methods, and Innovations
Below are actionable use cases derived from the paper’s benchmarks (IKD and KNP), empirical findings (near-random LLM performance on knowledge-state tracking), and methodological insights (prompting to focus on knowledge states improves results). Each item is categorized as Immediate or Long-Term, linked to sectors where relevant, with assumptions/dependencies noted.
Immediate Applications
- Industry (AI/Software): Model evaluation gates for “epistemic robustness”
- Use IKD and KNP as standard pre-deployment tests to detect when models attribute or act on knowledge they should not have (e.g., hallucinated access, “omniscient narrator” bias).
- Integrate as CI/CD checks in MLOps (e.g., “Knowledge-State Unit Tests” in eval pipelines alongside toxicity, bias, and factuality).
- Potential tools/workflows: SDKs for IKD/KNP integration; dashboards with “epistemic error rate” metrics; regression tests per release.
- Assumptions/dependencies: Public availability/licensing of datasets; domain adaptation for non-narrative tasks; calibration of pass/fail thresholds by risk tier.
- Industry (Creative Writing, Media, Publishing, Games): “Plot-hole and knowledge plausibility linter”
- Apply IKD to flag lines/scenes where characters act on implausible knowledge; suggest rewrites.
- For game studios, validate NPC narrative consistency and prevent “omniscient NPC” behavior.
- Potential tools/products: IDE/editor plugins for Scrivener/Google Docs; Unity/Unreal QA tool to check NPC belief consistency; writers’ room assistant.
- Assumptions/dependencies: Domain-specific rules (e.g., fantasy world constraints); multilingual coverage; human-in-the-loop review.
- Academia (NLP, CogSci): Diagnostic benchmark for ToM/KSTE research
- Use IKD/KNP to compare model families, analyze scaling laws, and test training interventions.
- Reproducible baseline for cross-lab comparisons of “knowledge-state tracking.”
- Potential workflows: Shared leaderboard; standardized prompts; ablation templates (Abl. 1–3 from the paper).
- Assumptions/dependencies: Transparent evaluation protocols; dataset maintenance; community adoption.
- Policy/Standards (AI Assurance, Procurement): Minimum evaluation criteria for user-facing LLMs
- Require KNP/IKD-like checks in procurement for chatbots in high-stakes or social contexts (health, law, finance, education).
- Potential outputs: Compliance checklists; certification rubrics referencing “epistemic plausibility” benchmarks.
- Assumptions/dependencies: Regulator and standards-body engagement; sector-specific thresholds; auditability.
- Customer Support/CRM: Guardrails against over-claiming or imputing user knowledge
- Configure system prompts to explicitly “reason with what the user knows/has said,” leveraging the paper’s finding that instructing models to focus on knowledge states yields sizable gains.
- Potential workflows: “Perspective Prompt Pack” templates; turn-by-turn checks that avoid assuming user awareness or consent.
- Assumptions/dependencies: Prompt generalization beyond narratives; monitoring for drift; human escalation.
- Education (EdTech): Reading-comprehension and perspective-taking exercises
- Employ KNP items as classroom tasks to teach students how knowledge access shapes actions; create formative assessments in ToM.
- Potential tools: Item banks, auto-grading with rationales, teacher dashboards highlighting “who knows what” reasoning.
- Assumptions/dependencies: Age-appropriate content; alignment with curricula; bias checks across cultural contexts.
- Legal/Compliance and Safety: “No-peek” checks for sensitive information handling
- Validate that chatbots do not infer or act on private third-party knowledge (reducing defamation/speculation risks).
- Potential products: Privacy guardrails, “knowledge-boundary” monitors that flag unsafe attributions.
- Assumptions/dependencies: Domain-specific policy rules; reliable detection in non-narrative dialogues; incident response workflows.
- Product/UX (Agent Frameworks): Action filters that enforce accessible knowledge
- Add a “BeliefFilter” to agent planning loops: before executing an action, test whether the agent could reasonably know the preconditions (KNP pattern).
- Potential tools: Middleware that checks proposed actions against an explicit per-actor knowledge store.
- Assumptions/dependencies: Accurate state modeling; minimal latency overhead; compatibility with current agent architectures.
- Research & Developer Enablement: Prompt design guidelines for epistemic focus
- Adopt a standardized instruction: “Identify what each actor knows and choose actions only from that perspective.”
- Potential outputs: Prompt libraries, few-shot exemplars, evaluation snippets derived from Ablation 3.
- Assumptions/dependencies: Gains hold across domains; prompt doesn’t overfit to benchmark patterns.
- Security/Trust & Safety: Red-teaming for “implausible knowledge” exploits
- Generate scenarios to test whether LLMs assert access to restricted data or “read minds” of named persons.
- Potential tools: Red-team scenario generator seeded by IKD/KNP patterns; risk scoring.
- Assumptions/dependencies: Human adjudication; alignment with threat models; periodic refresh to avoid overfitting.
Long-Term Applications
- Healthcare (Clinical Assistants, Patient Education): ToM-aware counseling and adherence support
- Assistants that model the patient’s knowledge/beliefs and tailor explanations and next steps accordingly (e.g., discharge instructions, consent).
- Potential products: Patient-facing explainers that adapt to individual misconceptions; clinician copilots that flag gaps in patient understanding.
- Assumptions/dependencies: Robust, validated KSTE in medical context; clinical safety trials; HIPAA/privacy compliance; multilingual, culturally sensitive reasoning.
- Education (Adaptive Tutoring): Student knowledge-state modeling at scale
- Tutors that infer what a learner likely knows and choose pedagogically sound next actions (hints, examples, assessments).
- Potential workflows: Per-learner “belief graph” tracking; sequencing algorithms that avoid assuming unstated mastery.
- Assumptions/dependencies: Longitudinal accuracy of learner models; fairness across demographics; integration with LMS platforms.
- Robotics and Human-Robot Collaboration: Shared mental models for safe teamwork
- Robots that track human partners’ knowledge of the environment and adapt plans (e.g., manufacturing, assistive care).
- Potential tools: “Visibility constraints” modules; multi-modal KSTE combining language, perception, and action logs.
- Assumptions/dependencies: Reliable multimodal grounding; real-time inference; safety certification.
- Multi-Agent Systems (Negotiation, Markets, Games): Belief-aware planning and strategy
- Agents reason about other agents’ knowledge/beliefs to negotiate, coordinate, or compete (e.g., procurement auctions, supply-chain coordination).
- Potential workflows: Explicit belief states in simulators; “No-peek” enforcement in training environments to prevent leakage of hidden info.
- Assumptions/dependencies: Scalable belief modeling; game-theoretic evaluation; guardrails against deceptive exploitation.
- AI Safety and Alignment: Training objectives for knowledge-state fidelity
- Incorporate KSTE tasks into pretraining/finetuning/RL (penalize actions based on inaccessible knowledge; reward epistemic humility).
- Potential methods: Auxiliary losses for belief tracking; curriculum from IKD→KNP→open-world ToM tasks; ToM modules.
- Assumptions/dependencies: Stable training signals; transfer beyond narratives; compute budgets.
- Enterprise Workflows (Knowledge Management): Epistemic provenance and access-aware copilots
- Assistants that cite “who knows what” in an org, routing questions to the right people and avoiding assumptions about stakeholder awareness.
- Potential tools: Belief-state overlays on org graphs; meeting assistants that track knowledge uptake across attendees.
- Assumptions/dependencies: Access control integration; accurate capture of organizational updates; privacy constraints.
- Law and Public Policy: Certification for high-stakes social interaction systems
- Standardized, sector-specific ToM/KSTE benchmarks for systems interacting with minors, vulnerable populations, or legal processes.
- Potential outputs: ISO-like profiles; third-party audits focusing on knowledge attribution errors and action implications.
- Assumptions/dependencies: Consensus across stakeholders; transparent reporting; periodic recertification.
- Media/Entertainment (Advanced Narrative Systems): Consistency-preserving story generation
- Generative tools that maintain per-character knowledge states across long-running franchises or interactive narratives.
- Potential products: Story bibles with dynamic belief tracking; real-time coherence checkers during writers’ rooms.
- Assumptions/dependencies: Long-context, cross-episode memory; rights management; creative flexibility vs. strict coherence.
- Finance (Advisory, Risk, Strategy): Counterparty-belief modeling for compliant advisory
- Advisors that avoid assuming investor knowledge, tailoring explanations and risk disclosures; trading simulators with belief-aware agents.
- Potential workflows: Suitability checks driven by inferred client understanding; negotiation bots respecting knowledge asymmetries.
- Assumptions/dependencies: Regulatory compliance; audit trails; adversarial robustness.
- Security/Integrity: Detection and mitigation of social engineering via ToM-aware checks
- Systems that recognize when an interlocutor is attempting to manipulate perceived knowledge states and adjust responses accordingly.
- Potential tools: Phishing-resistant chat interfaces; automated escalations when knowledge asymmetries are exploited.
- Assumptions/dependencies: High-precision detection to avoid false positives; integration with SOC playbooks.
- Cross-Lingual and Cross-Cultural Evaluation: Globalizing ToM benchmarks
- Extend IKD/KNP to multiple languages/cultures to ensure equitable performance and avoid culturally biased plausibility judgments.
- Potential outputs: International benchmark suite; region-specific calibration datasets.
- Assumptions/dependencies: Diverse annotation pools; careful cultural construct validity; ongoing maintenance.
- Developer Platforms: “Belief-state API” for agent ecosystems
- First-class developer primitives to declare, update, and validate what each agent/role knows; planning constrained by those states.
- Potential products: No-peek planners; epistemic memory stores; LLM wrappers enforcing perspective consistency.
- Assumptions/dependencies: Standardized schemas; interop with vector DBs/knowledge graphs; latency/throughput trade-offs.
In sum, the paper’s core contribution—stress-testing LLMs on knowledge-state tracking and showing substantial gaps—immediately enables better evaluation, guardrails, and writing tools, while paving the way for long-term ToM-aware systems in health, education, robotics, safety, and policy. Feasibility hinges on dataset access, domain transfer, culturally aware evaluation, and new training/evaluation pipelines that make “who knows what” a first-class constraint rather than an afterthought.
Collections
Sign up for free to add this paper to one or more collections.