- The paper demonstrates that RAG significantly reduces hallucination and query latency in 1B Gemma LLMs.
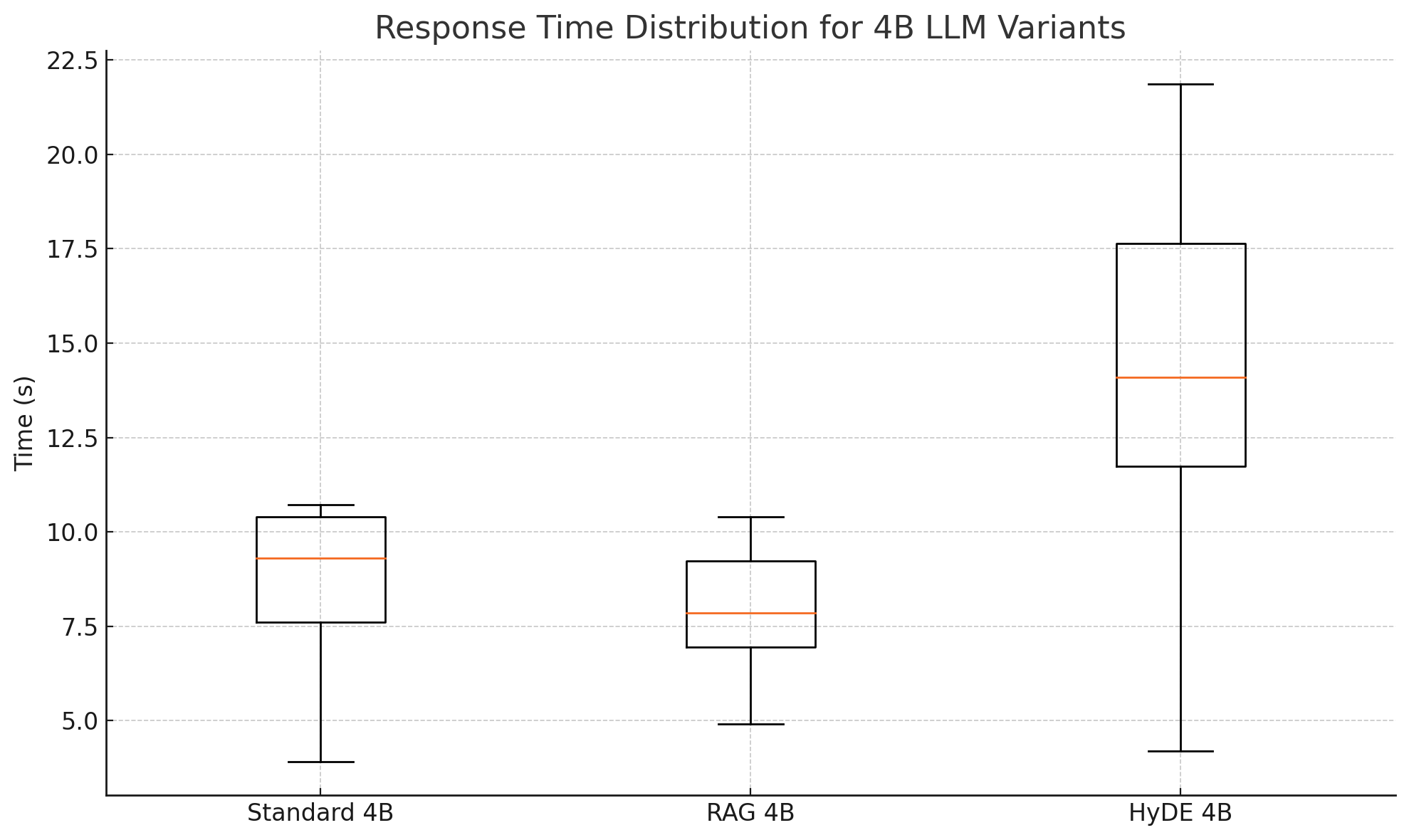
- It compares augmentation strategies, revealing HyDE's computational overhead and scalability challenges in 4B models.
- Integrating MongoDB and Qdrant, the research highlights robust memory management and semantic retrieval for personal assistants.
Evaluation of RAG and HyDE Augmentation Strategies in Compact Gemma LLMs
Introduction
The paper "Assessing RAG and HyDE on 1B vs. 4B-Parameter Gemma LLMs for Personal Assistants Integration" investigates augmentation strategies for compact LLMs, specifically focusing on 1 billion (1B) and 4 billion (4B) parameter variants. The study aims to address the resource constraints faced by LLM deployment in privacy-sensitive environments by using Retrieval-Augmented Generation (RAG) and Hypothetical Document Embeddings (HyDE). With a structured memory architecture employing MongoDB for short-term data and Qdrant for long-term semantic storage, the research explores the performance and factual reliability improvements across user-specific and scientific queries.
Methodology
To effectively assess RAG and HyDE methodologies, the study developed a sophisticated personal assistant system using a combination of technologies. The architecture leverages Docker Compose for container orchestration, LM Studio for model hosting, FastAPI for backend management, and React.js for frontend interfacing. MongoDB serves to store structured personal information, while Qdrant facilitates semantic vector search for the physics corpus. The study design incorporates rule-based operation modes to dynamically switch between personal, physics, and standard contexts based on user input.
The integration of RAG and HyDE is pivotal in enhancing interaction quality. RAG employs an external knowledge retrieval approach during inference, effectively minimizing hallucination risks and improving factual grounding. Conversely, HyDE generates hypothetical embeddings to enrich semantic retrieval, albeit with increased computational demands and variability.
Results
Physics Data Set Analysis
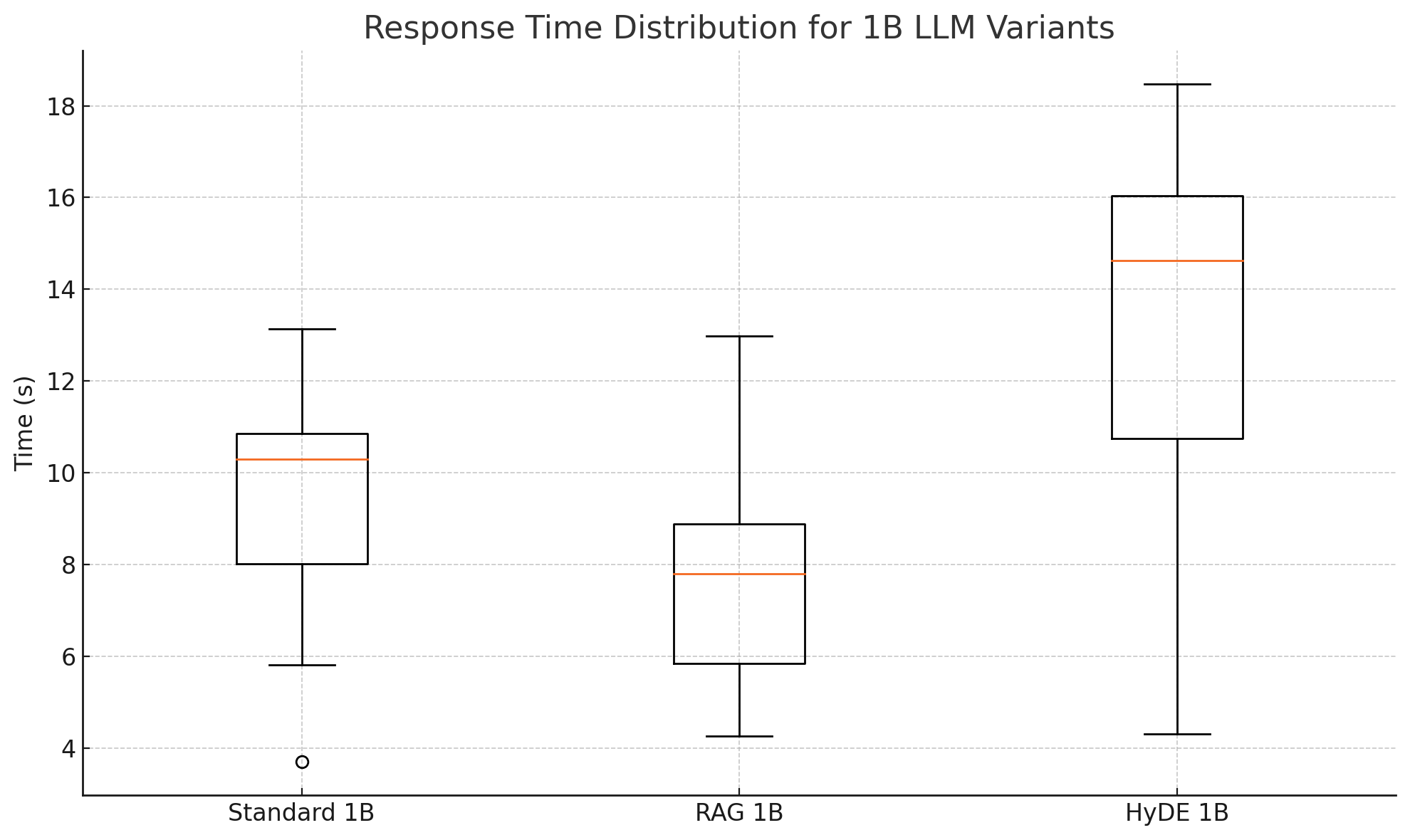
All model configurations—Standard, RAG, and HyDE—demonstrate competent problem-solving capability regarding physics queries. However, semantic and qualitative improvements varied markedly among augmentation strategies.
- Reduction of Hallucination Risk: RAG consistently grounds responses in factual data, eliminating black-box tendentiousness typical in LLMs.
- Latency Analysis for 1B LLM (Figure 1):
Scaling models from 1B to 4B yields marginal improvements across Standard variants but exacerbates latency and variability in HyDE due to increased computational complexity.
- Latency Analysis for 4B LLM:
Personal Data Retrieval
In personal data contexts, RAG showcases zero hallucination rates by precisely echoing stored user information. HyDE, however, introduces factual inaccuracies across all test questions, likely due to its generative nature.
Conclusion
The study concludes that RAG provides a practical, efficient enhancement method for compact Gemma LLMs, significantly mitigating hallucination and latency issues while grounding model outputs in factual context. HyDE's computational overhead limits its applicability, highlighting the need for optimized retrieval strategies. The synergy of MongoDB and Qdrant offers robust, scalable memory integration suitable for personal assistant applications, although future work should emphasize real-user data evaluations and domain expansion for broader applicability.
Implications and Future Work
This research establishes a foundation for deploying compact LLMs in privacy-first environments, offering a blueprint for further technological integration and memory optimization. Future studies should focus on enhancing HyDE's retrieval efficiency, expanding domain coverage, and conducting real-user trials to fully assess practical deployment readiness. Hybrid augmentation strategies combining RAG and HyDE may offer balanced benefits, fostering deeper semantic retrieval without compromising computational feasibility.