- The paper presents a novel RAG system that integrates dense vector retrieval and re-ranking to boost LLM accuracy and reduce hallucinations.
- The methodology employs BGE-M3 and a re-ranking model on Chinese Wikipedia and Lawbank, enhancing relevance for domain-specific queries.
- Evaluations on datasets like TTQA and TMMLU+ demonstrate improved performance, with significant implications for legal and financial applications.
Knowledge Retrieval Based on Generative AI
Introduction
This paper presents a question-answering system leveraging Retrieval-Augmented Generation (RAG) using Chinese Wikipedia and Lawbank as the primary retrieval data sources. The system combines dense vector retrieval with re-ranking, incorporating BGE-M3 and BGE-reranker to enhance retrieval relevance, and employs an LLM for generating accurate responses. The system benefits are evident in improved LLM capabilities, achieved through integrating BGE models that effectively handle dense vector retrieval and re-ranking to reduce information hallucinations, protect data privacy, and operate locally without reliance on external services.
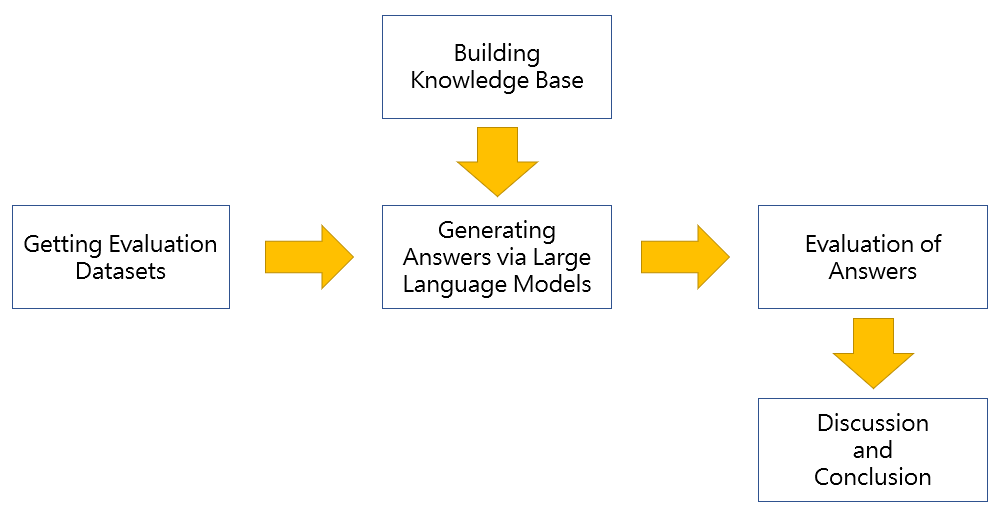
Figure 1: Basic Flow for this study.
Traditionally, IR systems have relied on keyword matching and ranking algorithms, which often fall short in relevance and contextual understanding. Advanced IR, supported by dense vector retrieval models such as BERT and Sentence-BERT, overcomes these challenges through semantic embeddings in high-dimensional spaces. This evolution has paved the way for LLMs capable of handling complex language tasks, albeit with challenges surrounding outdated or domain-specific information.
The progression from Statistical LLMs (SLMs) to LLMs allows for few-shot learning and better comprehension through methods like attention mechanisms. However, static training remains a limitation, addressed by models like the introduction of RAG, which integrates dynamic retrieval with LLMs.
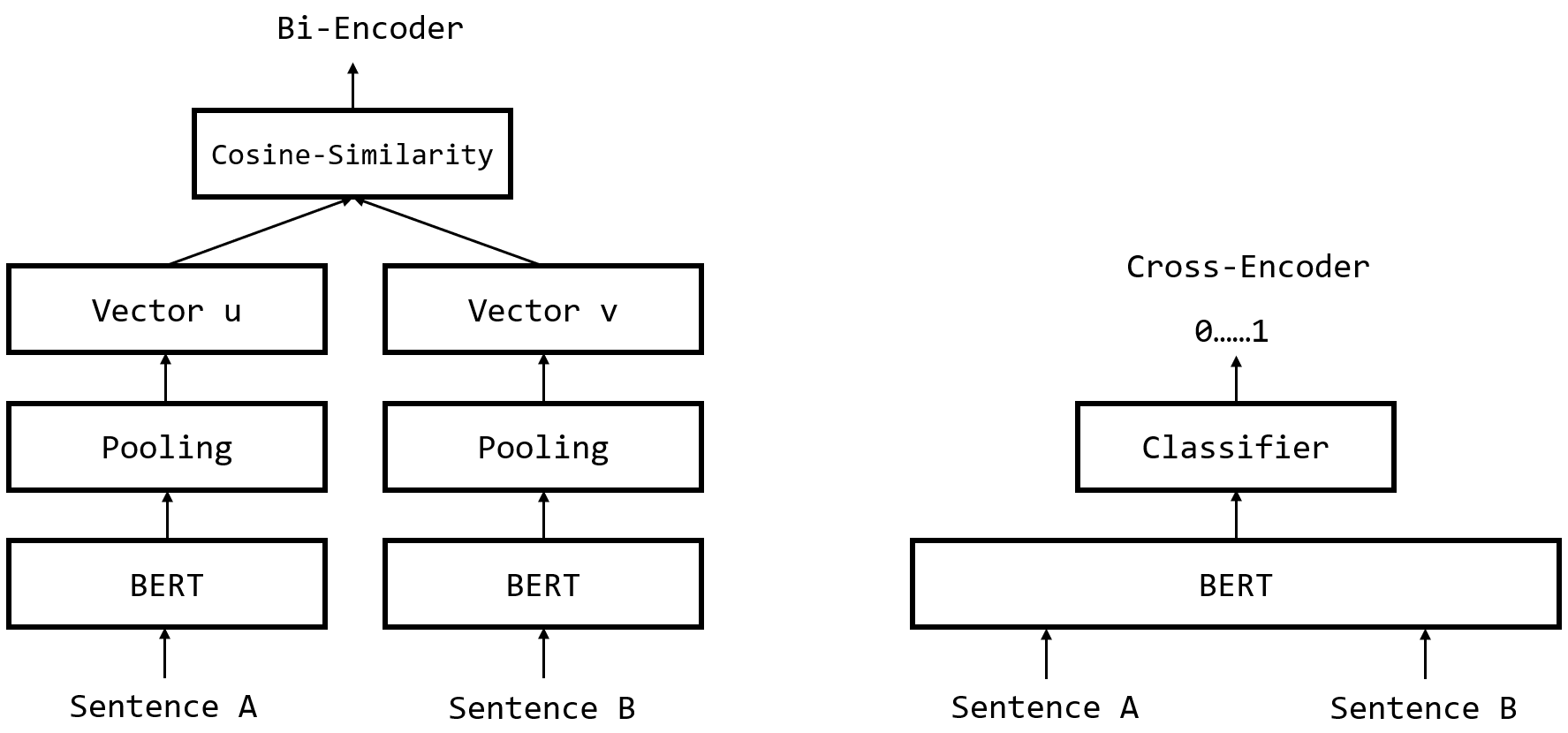
Figure 2: Bi-Encoder and Cross-Encoder.
Retrieval-Augmented Generation
RAG frameworks address the limitations of pre-trained LLMs by incorporating IR to access up-to-date, domain-relevant data. This method involves retrieving semantically relevant documents, which are then fed into an LLM for response generation. RAG frameworks can dynamically query external sources, ensuring real-time knowledge is available to mitigate obsolescence issues inherent in static model training.
Experimental Setup
Embedding Model and Data Sources
The paper uses the BGE-M3 model for multilingual and multi-granular text embedding, capable of cross-lingual retrieval and semantic searching across extensive datasets. The retrieval datasets include Chinese Wikipedia and specialized legal texts from Lawbank. Evaluation datasets utilized are TC-Eval and TMMLU+, providing a basis for traditional Chinese evaluation and challenging scenarios for LLMs.
Evaluation
The study evaluates models with and without RAG support using the TTQA dataset and various LLMs, evidencing higher accuracy with RAG. Additionally, domain-specific retrieval (i.e., Lawbank) enhances performance for specialized queries, as shown in increased accuracy on finance and insurance-related topics across several LLMs.
(Figure 3 to Figure 4)
The inclusion of domain-specific data significantly bolsters LLM performance compared to general knowledge sources, underscoring the importance of specialized retrieval mechanisms in RAG systems.
Discussion
Findings and Implications
The RAG system outperforms traditional LLM setups by resolving hallucination and accuracy issues through comprehensive retrieval and relevance ranking. This methodology is highly applicable in domains requiring precise knowledge retrieval, such as law and finance, where accurate and up-to-date information access is essential for practical applications.
Practical Applications and Limitations
The system's practicality extends to legal decision-making and educational tools, emphasizing local deployment for privacy and cost-effectiveness. Limitations include data coverage in niche domains and computational demands of re-ranking models, suggesting the need for further optimization and expansion of data sources.
Future Directions
Future research should focus on expanding the knowledge base, incorporating multi-modal data for broader applicability, and optimizing computational efficiency. User experience improvements are necessary to facilitate the system's integration into real-world applications.
Conclusion
The paper illustrates the potential of the RAG framework to elevate knowledge retrieval processes, enhancing LLM accuracy and domain applicability. The innovative integration of dense vector retrieval and dynamic re-ranking mechanisms marks a significant advancement in addressing the limitations posed by traditional LLMs. Continued research and development could further refine this approach, setting a precedent for future IR and LLM integration efforts.