- The paper introduces SemRAG, which integrates semantic chunking and knowledge graphs to enhance retrieval accuracy and reduce computational costs.
- It employs a cosine similarity-based algorithm to segment texts into coherent chunks that align with structured knowledge for efficient indexing.
- Experimental results on MultiHop RAG and Wikipedia datasets demonstrate improved answer relevancy and optimized buffer performance under tailored conditions.
SemRAG: Semantic Knowledge-Augmented RAG for Improved Question-Answering
Introduction
The paper "SemRAG: Semantic Knowledge-Augmented RAG for Improved Question-Answering" presents an advanced framework designed to enhance the performance of LLMs by integrating domain-specific knowledge through semantic chunking and knowledge graphs. SemRAG addresses the inefficiencies of conventional Retrieval Augmented Generation (RAG) processes, which often suffer from high computational costs and scalability issues due to extensive fine-tuning requirements. It achieves this by utilizing a semantic chunking algorithm that segments documents according to cosine similarity from sentence embeddings, maintaining semantic coherence while reducing computational demands.
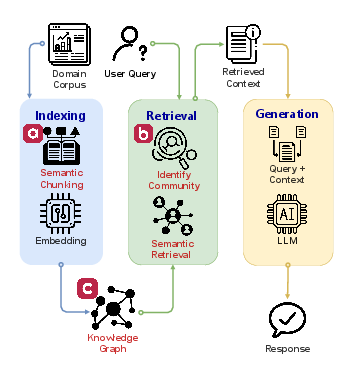
Figure 1: SemRAG framework leveraging semantic chunking and knowledge graphs for enhanced contextual understanding; (a) Semantic Indexing: Segment the document into smaller chunks indexed and stored in a database. (b) Context Retrieval: Retrieve the top k community based on semantic similarity. (c) Knowledge Graph: Information is extracted to build the knowledge graph hierarchy with communities.
SemRAG builds upon previous advancements in the field of RAG, notably addressing three critical stages: indexing, retrieval, and generation. Traditional methods often utilize computationally intensive chunking processes, where a trade-off exists between noise reduction and context retention. Techniques such as Hybrid Search and Semantic Ranking have aimed to improve retrieval performance, yet still face challenges regarding computational overhead and the integration of relevant information.
One promising direction explored is the use of knowledge graphs, which offer efficient structuring of data into entities and relationships. By disambiguating complex connections within the information dataset, knowledge graphs enhance retrieval accuracy and contextual understanding compared to keyword-based systems.
Methodology
The methodology centers around integrating semantic chunking with knowledge graph technologies, forming the framework of SemRAG. The semantic chunking algorithm dynamically groups sentences based on cosine similarity, ensuring coherent and contextually rich chunks within token constraints. The indexing phase aligns these semantic chunks with structured knowledge graph entities and relationships, creating an efficient architecture for retrieval tasks.
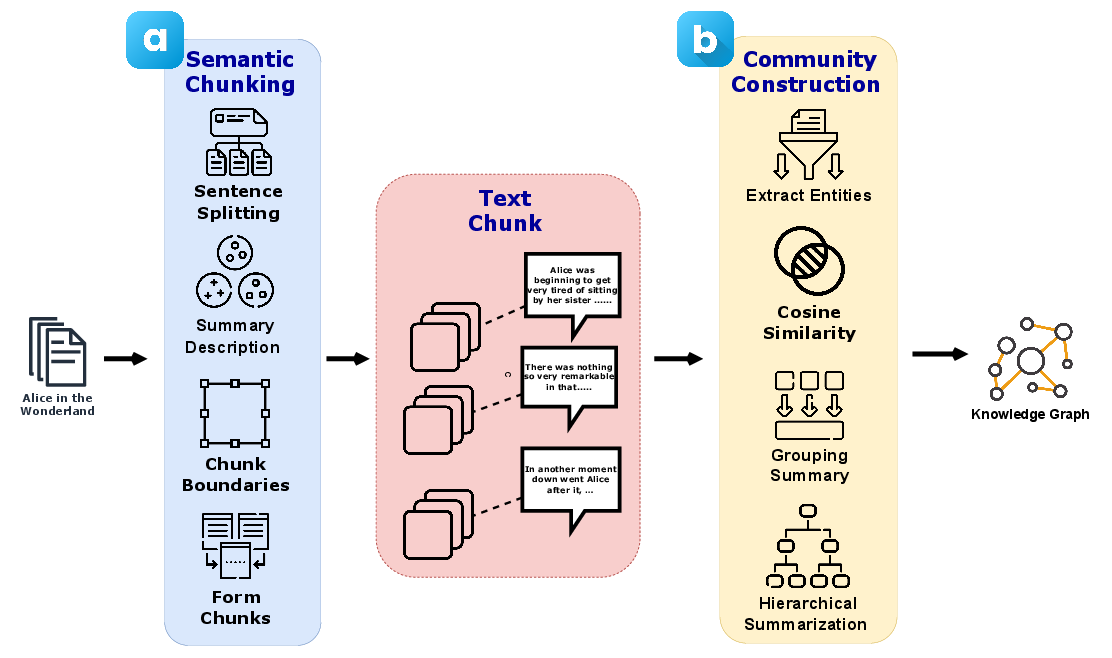
Figure 2: SemRAG consists of two phases, semantic indexing and graph communities construction. (a) Semantic Chunking: long text has been split and segmented into meaningful chunks based on semantic relevance. (b) Graph Communities Construction: building a knowledge graph based on hierarchical community summarization.
Experimental Results
The experimental setup involved testing SemRAG on distinct datasets—MultiHop RAG and Wikipedia. Across various models like Mistral, Llama3, and Gemma2, results consistently demonstrated SemRAG's superior performance in answer relevancy and correctness compared to baseline methods. Notably, optimized buffer sizes, particularly around size 5, yielded optimal improvements in retrieval efficiency without introducing excessive noise.
Buffer size was shown to directly affect graph complexity (Figure 3), particularly in multi-hop datasets, where relational context is crucial for complex queries. Performance improvements were most notable in environments where semantic chunk size was tailored to the dataset's structural characteristics, highlighting the importance of corpus-sensitive optimization.
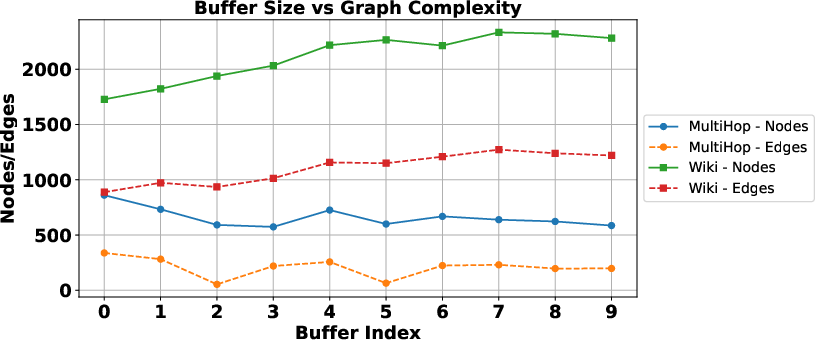
Figure 3: Buffer Size vs Graph Complexity.
Conclusion
SemRAG successfully addresses the limitations of conventional RAG systems by integrating semantic chunking and knowledge graphs, offering improved contextual understanding and enhanced @@@@3@@@@ without imposing heavy computational costs. This framework facilitates efficient application of domain-specific knowledge in LLM pipelines, aligning with sustainability objectives through its scalable nature.
Future Work
Future research directions could include exploring further lightweight approaches for integrating knowledge graphs within RAG frameworks, developing ground-truth metrics for chunk boundaries, and investigating argentic chunking methods that isolate atomic facts for more precise entity retrieval.
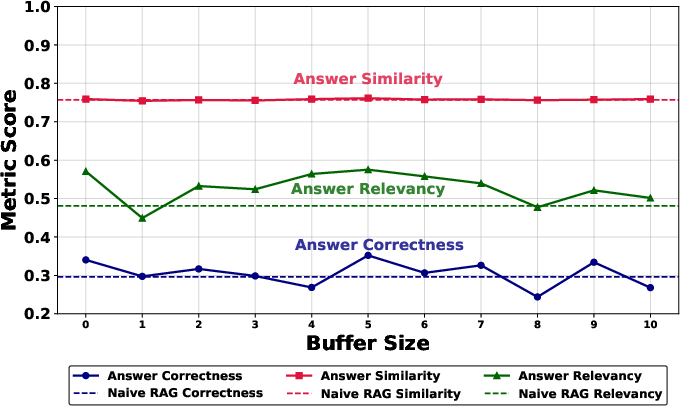
Figure 4: Performance of Buffer Sizes (0-10) vs Naive RAG Based on RAGAS Test Metrics Llama 3 (Multi-Hop).

