- The paper introduces Omni-RAG, a pipeline that leverages LLM-driven query rewriting, denoising, and decomposition to boost retrieval correctness by +4% and faithfulness by +34%.
- It employs a multi-stage process with intent-aware retrieval, cross-encoder reranking, and chain-of-thought generation to enhance factual accuracy amid noisy queries.
- The evaluation confirms that modular query preprocessing and targeted context selection significantly improve robust response generation in live scenarios.
LLM-Assisted Query Understanding for Live Robust RAG: The Omni-RAG Framework
Motivation and Background
Live Retrieval-Augmented Generation (RAG) systems, which combine LLMs with external knowledge retrieval, are essential for accurate, context-aware content generation in real-world applications. A major bottleneck for live RAG systems stems from the need to robustly handle user queries that are ambiguous, noisy, contain multiple intents, or deviate from the clean, atomic queries typical of scholarly benchmarks. Existing RAG pipelines often overfit to clean, single-intent queries, exhibiting rapid performance degradation in realistic dynamic scenarios with noise or multi-faceted intent [rag-survey] [LLMs_as_judges_survey].
Addressing these obstacles, this work introduces Omni-RAG, a RAG pipeline that explicitly leverages LLMs for query understanding, decomposition, and denoising. The design is directly motivated by the SIGIR 2025 LiveRAG Challenge, which stresses efficient, robust response generation from complex live queries against a fixed web-scale corpus (FineWeb) and a fixed LLM generator (Falcon-10B-Instruct).
System Architecture: Query Understanding-Centric RAG
Omni-RAG incorporates a multi-stage pipeline:
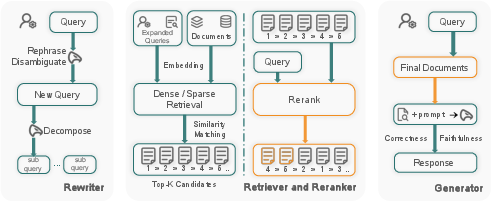
Figure 1: The overall pipeline of Omni-RAG: LLM-driven query denoising and decomposition, intent-aware retrieval, reranking, and response generation.
The architecture consists of three key stages:
- Deep Query Understanding and Decomposition: Noisy queries (e.g., with typos, incomplete phrasing, or multiple tasks) are rewritten by a prompt-based LLM into corrected, clarified form. Subsequently, the clarified query is decomposed by the LLM (with structured prompting) into a set of atomic sub-queries suitable for targeted retrieval.
- Intent-Aware Knowledge Retrieval: Each sub-query is dispatched independently to the retrieval backend (here, OpenSearch over the FineWeb corpus), extracting a candidate set of documents per sub-intent. Retrieval results for all sub-queries are then merged.
- Reranking and Generation: The union of retrieved documents is reranked using a high-capacity cross-encoder (BGE-reranker-large), which scores each document’s relevance to either the original or rewritten query context. The top-N documents (empirically N=10) are selected for input to the generation LLM (Falcon-10B) via a chain-of-thought prompt that includes both the rewritten query and the supporting context.
This explicit division enables the system to achieve fine-grained semantic coverage, higher recall for complex queries, and robust downstream reasoning/generation under adverse live query conditions.
Implementation and Evaluation Methodology
Query Understanding: Denoising and Decomposition
Prompted LLMs (optionally fine-tuned for denoising) are used to rewrite the input query, followed by decomposition into M sub-queries, structured as JSONs for programmatic consumption. The rewriting step ensures search queries are better aligned with retriever expectations, mitigating semantic drift and retrieval noise [queryma] [queryllmliu] [RQ-RAG]. Decomposition enhances multi-intent coverage and supports parallel retrieval paths [Least-to-Most] [QCompiler].
Multi-Intent Retrieval and Aggregation
Each sub-query qs′ is issued to the OpenSearch backend for top-k retrieval (K set empirically via ablation). The overall candidate document pool Dretrieved is the set-union over all intents. This design increases both recall and the semantic diversity of retrieved contexts, at the expense of greater initial redundancy.
Reranking for Document Quality and Redundancy Mitigation
Redundancy and irrelevance, introduced by retrieval along diverse decomposed paths, are suppressed through a reranker. BGE large [bge_embedding] [chen2024bge] is used as a cross-encoder reranker scoring (q,d) across all retrieved candidates. Only the top-N are provided to the generator, which empirically optimizes both factuality and answer quality versus longer, noisier contexts.
Generation and Self-Consistency
The final answer is generated by Falcon-10B with a chain-of-thought prompting paradigm. For reliability, multi-path self-consistency [cot-sc] is optionally employed—generating multiple reasoning traces and ensembling for improved factual robustness. However, empirical results indicate an optimal tradeoff: increasing the number of reasoning paths does not always yield higher factual faithfulness, sometimes even reducing it due to hallucination on less relevant retrieval branches.
Evaluation with LLM-Based Pseudo-Labels
Due to lack of ground-truth, system performance is measured using LLM-based pseudo-labels (generated by Qwen2.5-7B-Instruct). Dedicated prompts assess "relevance" and "faithfulness" of omnibus model outputs. Scoring is contextualized using few-shot in-context examples to ensure rating consistency, a critical practice for automated LLM-based evaluation [LLMs_as_judges_survey] [survey-eval]. Final pseudo-labels are cross-validated by another generative LLM (Falcon-10B) to avoid same-model scorer/generator bias [G-Eval] [GPTScore] [Meta-Rewarding].
Empirical Results and Discussion
Omni-RAG delivered strong pragmatic results, ranking #2 on the official leaderboard of the SIGIR LiveRAG Session 1 among 12 systems. Notably, relative to competency-matched baselines:
- +4% Correctness and +34% Faithfulness versus the next-best participant, attributed to higher recall and effective context reranking.
- The performance improves monotonically (to a point) with the number of retrieved documents, confirming the benefit of denoising/decomposition plus reranking over naïve one-shot retrieval.
On dry runs, relevance and faithfulness increase with retrieval depth and are optimized with a moderate value for self-consistency paths (e.g., sc=4). Excessively high path counts degrade factual accuracy by introducing spurious reasoning traces from off-topic retrieval.
Key Strengths and Limitations
Strengths:
- Explicit modeling of linguistic noise, ambiguity, and multi-intent queries, which are characteristic of live user interaction but neglected in prior RAG benchmarks [selfrag] [queryma].
- Demonstrably higher recall and robustness to retrieved context noise, without substantially sacrificing context quality via aggressive reranking [YoranWRB24] [LiLCX024].
- Scalable to web-scale corpora, compatible with high-throughput search infrastructure (OpenSearch), and decoupled from any proprietary LLM backbone.
Limitations:
- The framework incurs extra pipeline latency due to multi-step LLM calls (for rewriting and decomposition), which may create throughput constraints in scenarios demanding sub-second response latency.
- Chain-of-thought and self-consistency approaches introduce quadratic scaling w.r.t the number of reasoning paths and retrieved contexts. Mitigating this cost with context filtering, compression [RECOMP] [LongRefiner], or LLM acceleration techniques remains a priority for real-time applications.
- Absolute faithfulness remains bounded by retriever coverage and corpus quality; domain-specific KBs could further supplement for closed-domain or high-value tasks [kgfid] [KnowPAT].
Theoretical and Practical Implications
The Omni-RAG framework provides direct empirical evidence that LLM-centric query understanding/rewriting remains underexplored and undervalued within RAG pipelines. The clear improvement on robust answering of ambiguous, multi-intent, and noisy queries indicates that future RAG research and system design should emphasize (i) explicit query denoising, (ii) intent-plane decomposition, and (iii) modular reranking as first-class citizens, not post-hoc patches [RA-ISF] [RQ-RAG] [EchoPrompt]. These steps are central for deployment in high-noise, open-world environments such as conversational agents, search assistants, and enterprise QA systems.
Methodologically, LLM-based evaluation provides a viable route for automatic, multidimensional measurement of RAG outputs in the absence of static ground-truth answers, provided scorer/generator independence and explicit prompt design [G-Eval] [LLMs_as_judges_survey] [Meta-Rewarding].
Future Directions
- Adaptive query decomposition: Incorporate uncertainty-aware decomposition (via LLM epistemic uncertainty or entropy) to optimize the number and nature of sub-queries dynamically per input [SKR] [Plan-and-Solve].
- Retriever-generator co-evolution: Jointly train/fine-tune denoiser, decomposer, retriever, reranker, and generator in end-to-end differentiable pipelines, allowing for direct feedback-loop optimization [rw-r, FullRank, iterretgen].
- Domain transfer and long-context support: Extend to dynamic, multi-source knowledge bases, and leverage context compression for long-sequence LLMs [LongRefiner] [HtmlRAG] [CoRAG].
- Robust LLM-based evaluation: Continue research on robust, multi-facet LLM-based assessment, ensuring cross-domain, cross-lingual generalization and human-aligned calibration [survey-eval] [TIGERScore] [LLM-Eval].
Conclusion
Omni-RAG demonstrates the efficacy of LLM-driven query understanding and intent decomposition as core mechanisms for enhancing live RAG system robustness. By modularizing denoising, decomposition, multi-path retrieval, reranking, and chain-of-thought generation, the pipeline closes the reality gap between academic benchmarks and noisy, ambiguous live settings. This paradigm—anchored in explicit preprocessing, fine-grained context selection, and robust evaluation—should be considered foundational for next-generation open-domain RAG deployments, and presents multiple avenues for advanced research on adaptive understanding and response under complex query regimes.