- The paper demonstrates how integrating retrieval with generation reduces hallucinations and enhances factual accuracy in NLP.
- It evaluates key metrics such as Recall@k, MRR, BLEU, and ROUGE to benchmark retrieval and generative performance.
- The paper identifies challenges like system latency, privacy issues, and multimodal integration while outlining future research directions.
A Systematic Review of Key Retrieval-Augmented Generation (RAG) Systems: Progress, Gaps, and Future Directions
Introduction
This paper provides a comprehensive evaluation of the evolution and application of Retrieval-Augmented Generation (RAG) systems within the field of NLP. RAG systems synergize LLMs with sophisticated information retrieval mechanisms, addressing the critical limitations of parametric models, such as "hallucinations" and outdated knowledge.
Foundations of RAG
RAG systems integrate a retrieval component with a sequence-to-sequence (seq2seq) generator to conceptualize outputs in the context of external documents. A fundamental equation governing this integration is:
P(y∣x)=i=1∑KPret(zi∣x)Pgen(y∣x,zi),
where Pret denotes the retriever's distribution over documents, and Pgen is the generator's output conditional probability. This structure ameliorates factual inaccuracies by grounding outputs in realistic content fetched in real time.
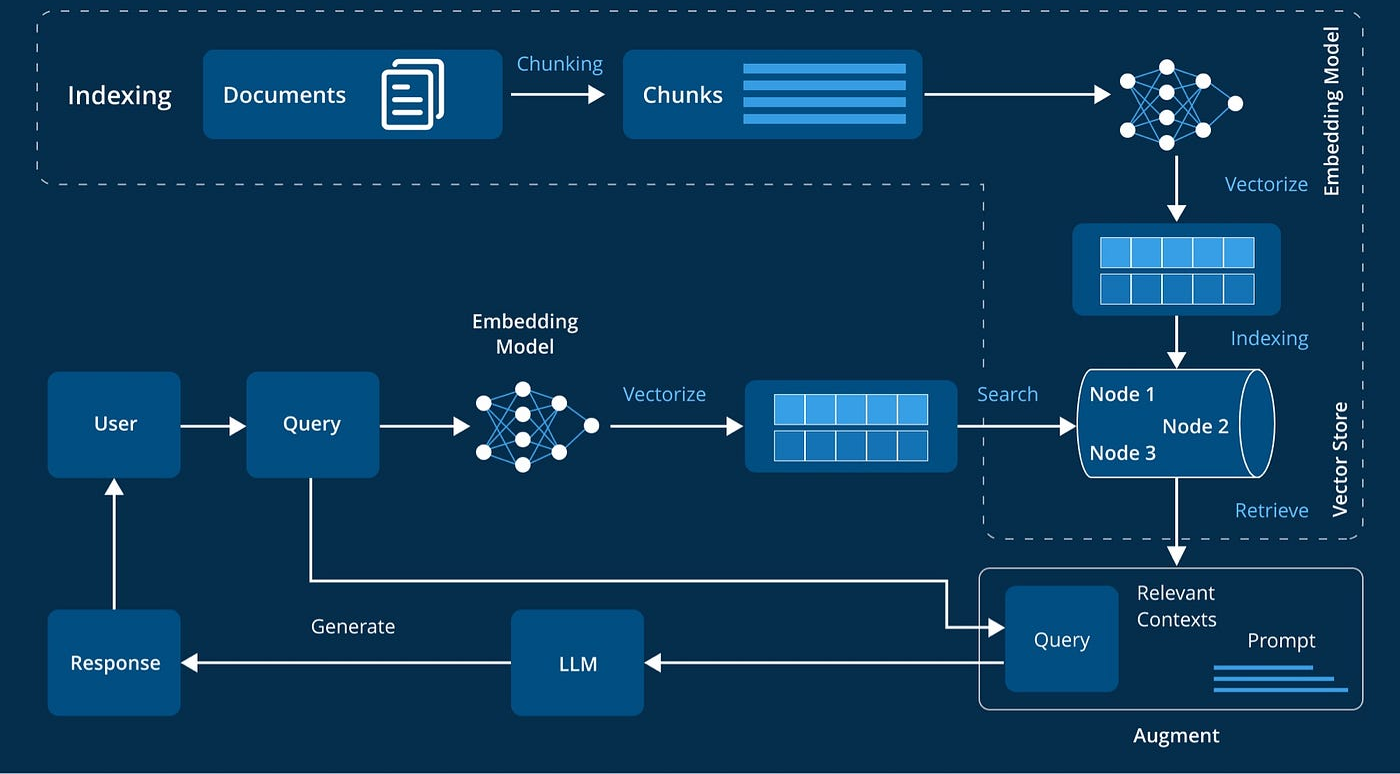
Figure 1: Illustration of a RAG Architecture.
Evolution and Historical Progress
RAG's evolution traces back to early retrieval-augmented QA systems like DrQA. Over time, it matured through milestones such as the formalization in 2020 by Lewis et al. and the development of dense passage retrieval (DPR). The integration of architectures like Fusion-in-Decoder (FiD) further enhanced retrieval quality and generative fluency.
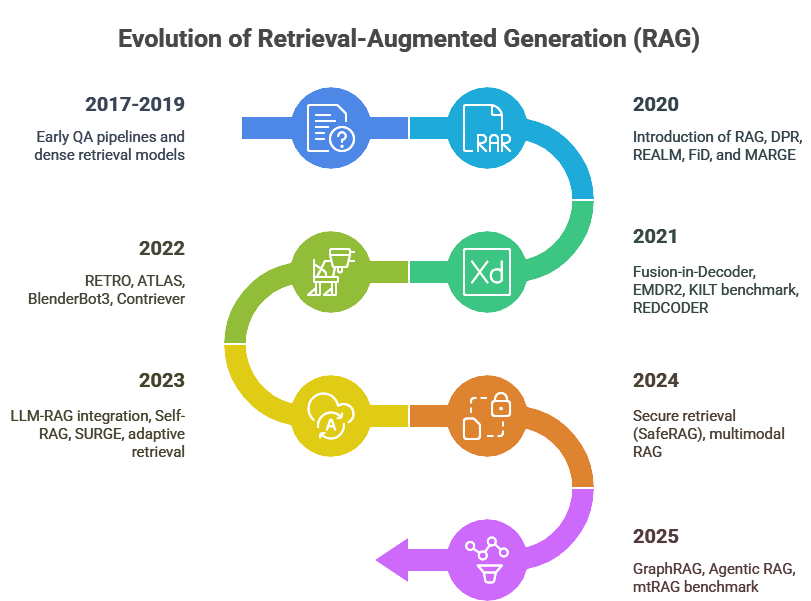
Figure 2: Evolution of a RAG Architecture.
From 2020 to 2024, innovations such as the RETRO model and trails in few-shot learning by systems like Atlas showcased the capacity to utilize smaller models effectively with extensive knowledge retrieval strategies.
Industry Applications and Challenges
The application of RAG systems in industries ranges substantially, benefiting sectors such as health care, law, and enterprise search, where proprietary knowledge retrieval is key. However, challenges such as retrieval latency and integration complexity remain significant.
Privacy and regulatory compliance represent pivotal concerns in enterprise applications. The assurance of private data retrieval, often achieved through specialized techniques like Federated Retrieval, highlights the ongoing technical and ethical concerns.
Evaluation Framework and Benchmarks
Evaluating RAG systems involves gauging retrieval accuracy (Recall@k, MRR), generation quality (EM, F1, BLEU, ROUGE), and system scalability. Key benchmarks include Natural Questions and KILT, with attention to generation fidelity and evidential alignment emphasized.
Figure 3: Evolution of RAG: 2017 - Mid-2025.
Future Directions and Research
Potential research avenues involve multi-hop retrieval enhancement, secure retrieval methods, and multimodal RAG systems. Addressing these will involve crafting more efficient architectures that seamlessly integrate vast knowledge databases across multiple modalities.
A widespread adoption and evolution of RAG indicate its potential to fundamentally improve knowledge-dependent AI applications. However, ensuring factual reliability and real-time adaptability will guide future innovations.
Conclusion
RAG systems symbolically represent a paradigm shift in AI knowledge integration. Despite their current strengths in enhancing LLMs with dynamic knowledge retrieval, continual optimizations are necessary to tackle existing inefficiencies and standardize these systems in varied application domains. Future improvements in retrieval mechanisms and integration strategies will catalyze the transformation of generative AI solutions across industries.

