- The paper introduces a novel TMU that reduces inference latency by up to 34.6% through optimized tensor manipulation operators.
- It employs a RISC-inspired execution model with a reconfigurable masking engine to support diverse tensor operations in AI SoCs.
- System-level strategies such as double buffering and tensor prefetching are used to enhance data movement and overall throughput.
Tensor Manipulation Unit (TMU): High-Throughput AI SoC Design
This paper presents the Tensor Manipulation Unit (TMU), a reconfigurable, near-memory hardware block designed to optimize data-movement-intensive (DMI) operations in AI Systems-on-Chip (SoCs). It addresses crucial performance bottlenecks in modern AI workloads by efficiently handling tensor manipulation (TM) operators, which are traditionally underexplored compared to compute-intensive operations.
Introduction to Tensor Manipulation
Tensor manipulation (TM) operators are pivotal in contemporary neural networks, functioning predominantly to orchestrate data movement with minimal computation. Common TM operations such as transpose, reshape, and non-maximum suppression constitute substantial portions of inference latency due to their extensive interaction with memory hierarchies.
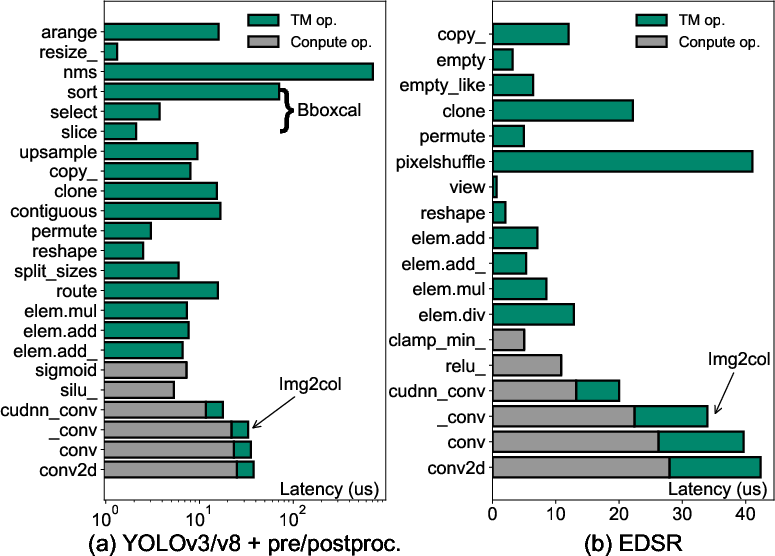
Figure 1: The average operator-level latency when running (a) YOLOv3/v8+pre/postproc and (b) EDSR on an NVIDIA RTX 3080.
The paper identifies that up to 40.62% of end-to-end inference latency can be attributed to TM operators as demonstrated in benchmarks on NVIDIA RTX 3080 GPUs (Figure 1). TMU aims to alleviate these latencies by streamlining memory data transfers.
TMU Architecture and Execution Model
The TMU integrates closely with a Tensor Processing Unit (TPU) within an AI SoC, utilizing a RISC-inspired execution model enabling support for diverse TM operators. With both coarse-grained and fine-grained manipulations, TMU processes tensor streams efficiently using a unified address abstraction.
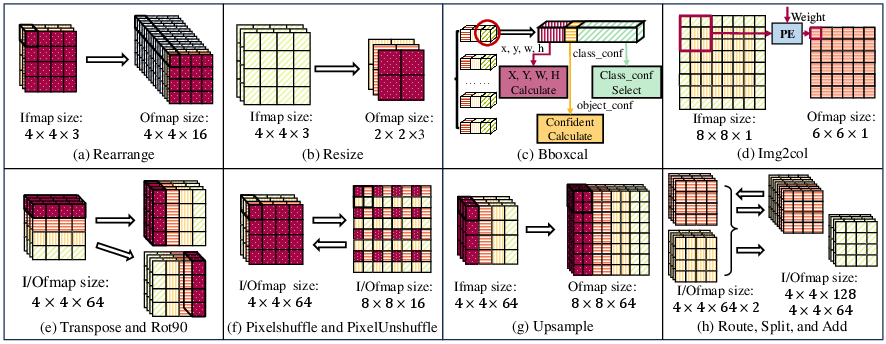
Figure 2: Graphical representation of typical TM operators adopted in state-of-the-art neural networks.
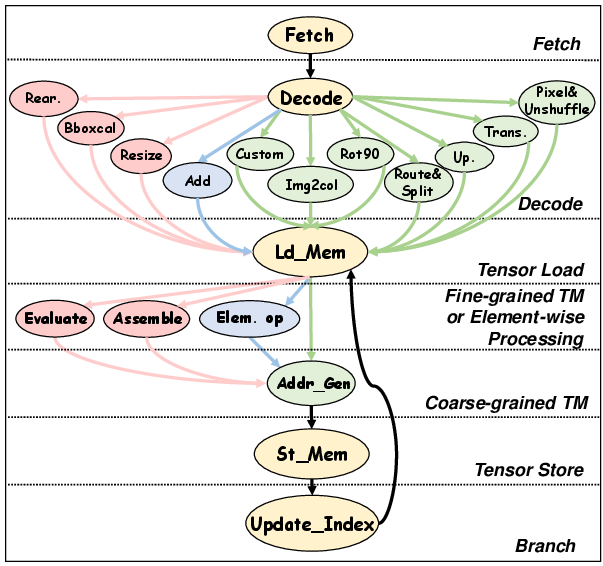
Figure 3: Generic execution model for TM.
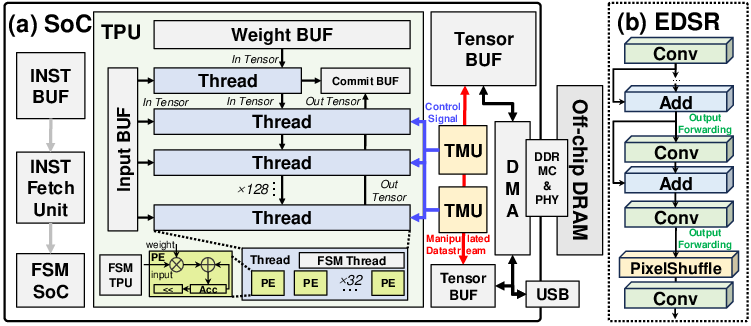
Figure 4: (a) System architecture integrating the proposed TMU and TPU. Two TMUs are deployed to support tensor prefetching. (b) Network architecture of EDSR.
As illustrated in Figures 2 and 3, TMU employs a novel address generator and reconfigurable masking engine to optimize both data routing and element-wise processing. Integrated into a comprehensive SoC architecture (Figure 4), it supports operator-level configurations through a matrix-based approach, accommodating transformations such as Img2col and PixelShuffle dynamically.
System-Level Strategies
To minimize latency and optimize throughput, TMU employs double buffering, tensor prefetching, and output forwarding strategies as shown in Figure 5.
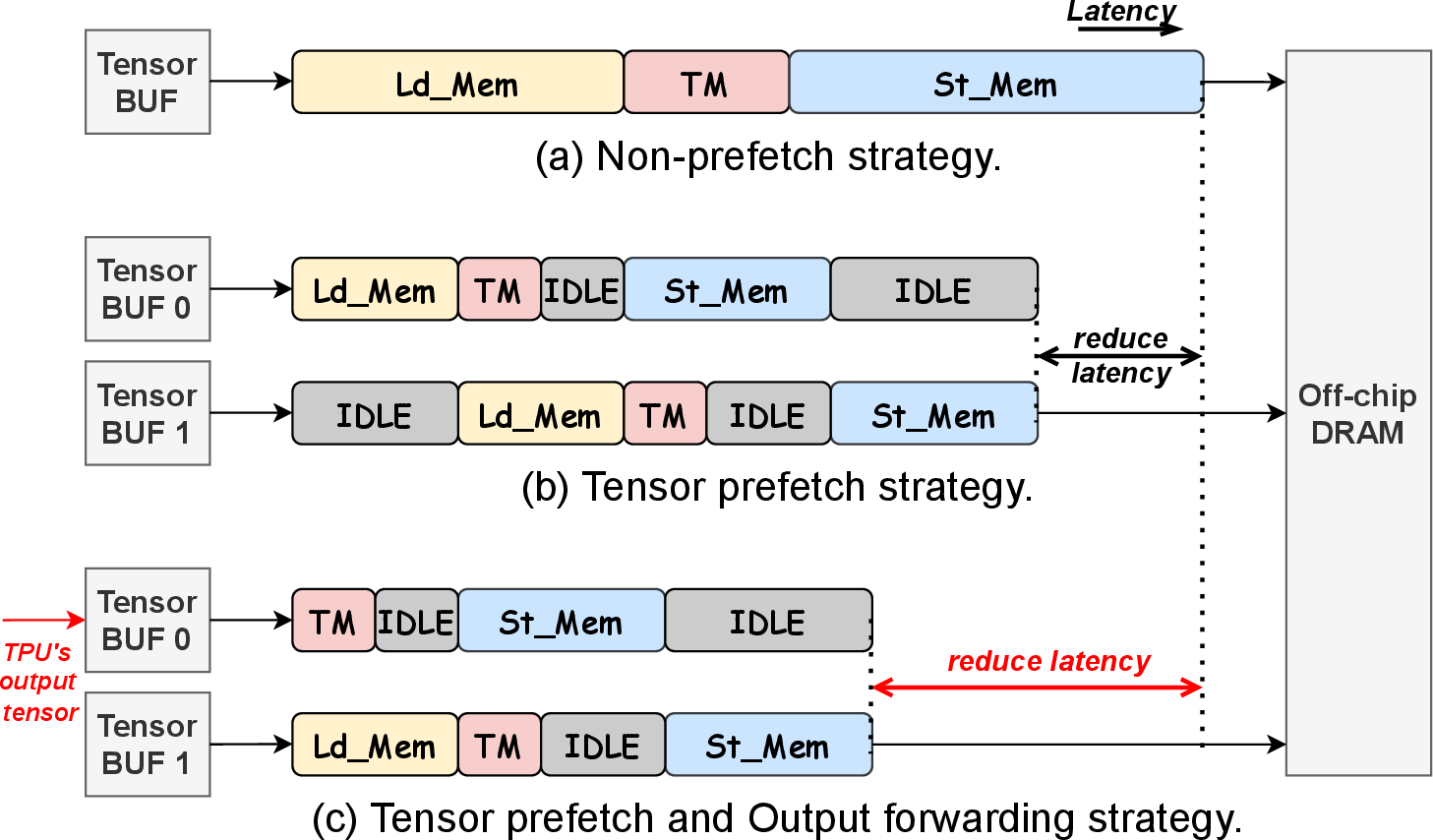
Figure 5: (a) Non-prefetch strategy. (b) Tensor prefetch strategy. (c) Tensor prefetch and Output forwarding strategy.
These strategies enhance collaboration between the TMU and TPU, effectively overlapping data movement with computation to mitigate performance bottlenecks in neural network pipelines.
Experimental Evaluation
The TMU showcases substantial latency improvements across various neural network implementations, including YOLOv8 and EDSR, achieving up to a 34.6% reduction in inference latency. It's synthesized using SMIC 40 nm technology, occupying only 0.019 mm2 of silicon, proving its viability in compact, high-throughput AI SoCs.
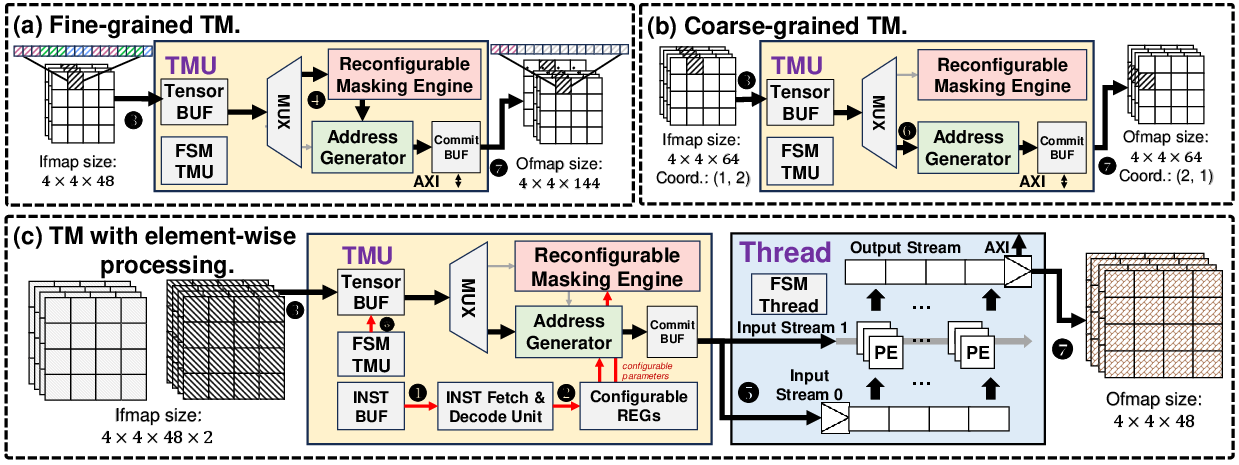
Figure 6: TMU's microarchitecture and dataflows. (a) Fine-grained TM. (b) Coarse-grained TM. (c) TM with element-wise processing.
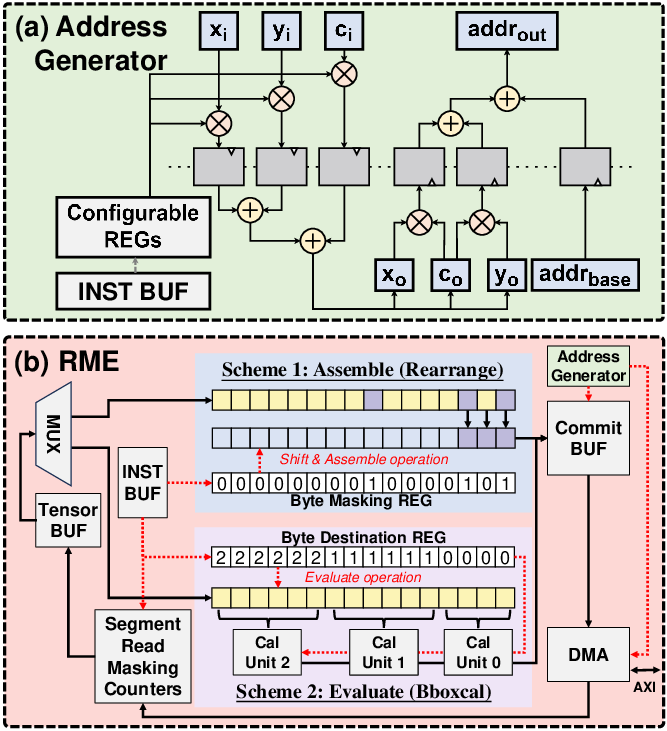
Figure 7: (a) Address generator for coarse-grained TM operators. (b) Reconfigurable masking engine (RME) for fine-grained TM operators.
The TMU outperforms conventional CPUs and GPUs by orders of magnitude, demonstrating that advanced architectural support for TM operators is critical for next-generation AI systems.
Conclusion
TMU provides significant architectural advancements for AI SoCs by addressing the underexplored domain of tensor manipulation. Its novel approach to high-throughput data movement, combined with computational efficiencies, sets a precedent for upcoming AI hardware developments. The integration of TMU not only decreases inference latency but ensures adaptability across diverse and evolving neural network workloads. The findings suggest considerable potential for extending TMU frameworks to broader AI applications, paving the way for scalable and reconfigurable AI SoC architectures.