- The paper introduces a novel LLIA framework that enables low-latency, audio-driven portrait video generation using diffusion models.
- It employs a dynamic variable-length video generation strategy and pipeline parallelism to meet real-time performance demands.
- Experimental results on high-end GPUs demonstrate high FPS and effective facial expression control, validating the framework's practical potential.
LLIA: Low-Latency Interactive Avatar Generation via Diffusion Models
This paper introduces LLIA (low-latency interactive avatars), a novel framework for real-time audio-driven portrait video generation using diffusion models, addressing the challenges of speed, latency, and duration inherent in interactive avatar applications. The method focuses on minimizing response latency, achieving real-time performance, and enabling natural conversational states and fine-grained expression control.
Key Components and Innovations
The LLIA framework incorporates several key components to achieve its objectives. The model builds upon Stable Diffusion 1.5 (SD1.5) architecture and integrates Appearance ReferenceNet, Audio Layer, Motion Module, and Face Locator modules. LLIA pioneers a robust variable-length video generation training strategy to reduce response latency while preserving video quality. The system categorizes avatar states into listening, idle, and speaking, using class labels as conditional inputs for state control. LLIA also introduces a method for explicit facial expression control by manipulating the reference image fed into the ReferenceNet.
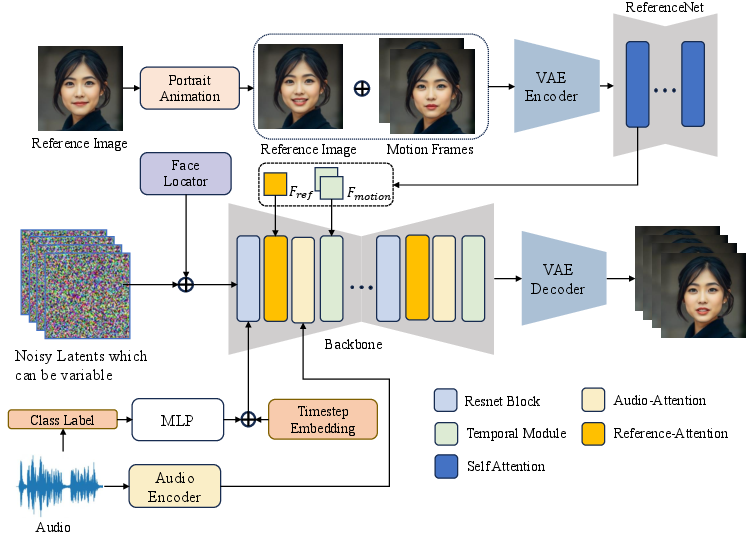
Figure 1: Overview of the proposed method, highlighting novel modules for portrait animation, state determination via class labels, and dynamic video length adaptation.
Variable-Length Video Generation
The core innovation in LLIA is the variable-length video generation training strategy. Response latency is a critical factor in interactive avatars, and reducing the length of generated video clips is essential. The paper introduces a dynamic training approach where the number of generated frames (f) is initially fixed to train the motion module and audio layer effectively. Once the model converges, f becomes dynamic during training, ensuring f≥n (n being the number of motion frames). This strategy enables the model to adopt different video generation lengths during inference without accumulating errors.
To address the computational demands of diffusion models, the paper employs consistency models trained with a DDPM pre-trained model for few-step video generation. The model is further quantized to INT8, and the UNet and VAE modules are processed concurrently via pipeline parallelism to accelerate inference speed.
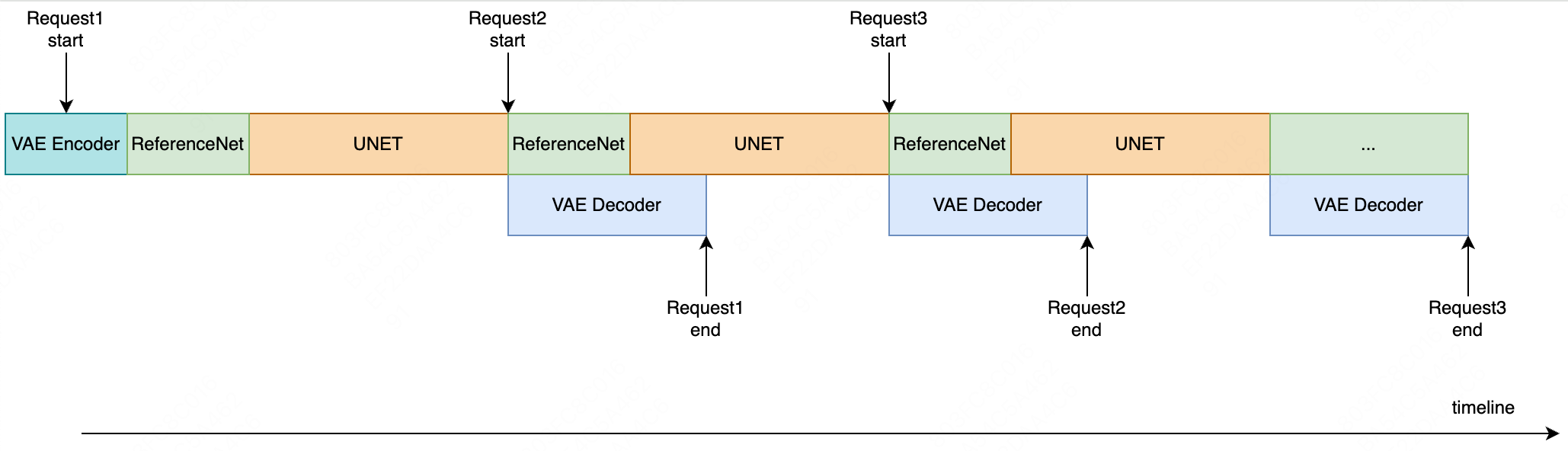
Figure 2: Illustration of the inference pipeline parallelism, showcasing concurrent processing of UNet and VAE modules for reduced latency.
Conversational States and Expression Control
LLIA incorporates class labels as conditional inputs to control avatar states (listening, idle, and speaking). The acoustic features of the audio input determine the specific state signal, allowing the model to interpret user intent and generate appropriate state transitions. Fine-grained facial expression control is achieved by applying a pre-trained portrait animation model to modify the expression in the reference image before feeding it into ReferenceNet.

Figure 3: The digital avatar performs a nodding response action in the listening state, controlled by the input class label prompt.

Figure 4: The model switches smoothly between various expressions according to different facial expressions in the input reference images.
Experimental Results and Analysis
The paper presents extensive experimental results demonstrating the effectiveness of LLIA. On an NVIDIA RTX 4090D, the model achieves a maximum of 78 FPS at a resolution of 384×384 and 45 FPS at 512×512, with initial video generation latencies of 140 ms and 215 ms, respectively. Qualitative results showcase the model's ability to generate diverse avatar styles and maintain high generation quality with few-step sampling.

Figure 5: The model demonstrates qualitative results based on different avatar styles, showing the versatility of the approach.

Figure 6: Portraits generated with 2-step, 4-step, and 25-step sampling, demonstrating comparable quality with reduced sampling steps.
Dataset
A high-quality dataset of over 100 hours was curated, comprising open-source data, web-collected videos, and synthetic data designed to improve performance in listening and idle states. This dataset was filtered through a rigorous multistage pipeline involving automated processing and manual screening.
Implementation Details
The model was trained on 48 A100 GPUs, using Stable Diffusion v1.5 (SD1.5) weights for initialization. Various training configurations were employed, including random scaling of input images, AdamW optimizer, and MSE loss. Model quantization and pipeline parallelism were implemented for efficient deployment. INT8 quantization achieved significant speed enhancements while maintaining original model performance.
Conclusion
The LLIA framework presents a significant advancement in real-time audio-driven portrait video generation. By addressing the challenges of latency, computational cost, and interactivity, the method demonstrates the potential of diffusion models in time-sensitive, user-driven applications. The results indicate that diffusion-based digital avatars can achieve real-time interaction with low response latency, opening avenues for practical interactive applications.

