- The paper introduces MobileVLM V2, which improves architecture and training to achieve faster speed and better accuracy on standard vision-language benchmarks.
- It demonstrates that a 1.7B parameter model can match or outperform larger 3B models by utilizing high-quality image-text pairs and diverse academic data.
- The study highlights a lightweight projection mechanism that reduces token count and latency, making it ideal for deployment in resource-constrained environments.
MobileVLM V2: A Deep Dive into Efficient Vision LLMs
The paper "MobileVLM V2: Faster and Stronger Baseline for Vision LLM" (2402.03766) introduces MobileVLM V2, an enhanced family of vision LLMs (VLMs) building upon the MobileVLM architecture. It posits that improvements in architectural design, training schemes tailored for mobile VLMs, and curated high-quality datasets can significantly boost VLM performance. The study demonstrates that a 1.7B parameter MobileVLM V2 model can achieve performance comparable to or better than larger 3B scale VLMs on standard benchmarks.
Core Architectural and Training Innovations
The primary advancements in MobileVLM V2 are centered around three key areas: data utilization, training strategies, and projection mechanisms.
- Enhanced Data Utilization: The model leverages 1.2 million high-quality image-text pairs from ShareGPT4V [chen2023sharegpt4v] to improve vision-language feature alignment. Additionally, the training data incorporates more academic tasks such as ScienceQA [lu2022learn], TextVQA [singh2019towards], and SBU [Ordonez_2011_im2text] to increase diversity and instruction-following capabilities.
- Effective Training Strategies: Unlike previous approaches that freeze the LLM during pre-training, MobileVLM V2 employs thorough training of all projector and LLM parameters during both pre-training and instruction tuning. This strategy is shown to better harness the potential of high-quality data.
- Lightweight Projection Mechanism: The paper introduces a streamlined projection mechanism that bridges the vision and LLMs. By improving the representation of image tokens with enhanced positional information, the model can compress the number of image tokens without significant performance degradation.
The MobileVLM V2 architecture (Figure 1) comprises a pre-trained vision encoder (CLIP ViT-L/14), a pre-trained LLM (MobileLLaMA), and a lightweight downsample projector (LDPv2). The LDPv2 module includes feature transformation, token reduction via average pooling, and positional information enhancement using a PEG module with skip connections. This design reduces the number of parameters and increases the running speed.
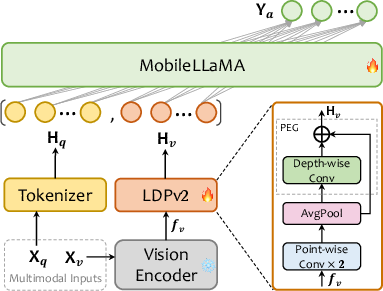
Figure 1: MobileVLM V2's architecture. Xv and Xq indicate image and language instruction, respectively, and Ya refers to the text response from the LLM MobileLLaMA. The diagram in the lower right corner is a detailed description of LDPv2, \ie, the lightweight downsample projector v2.
Experimental Results and Analysis
The authors conducted extensive experiments to evaluate the performance of MobileVLM V2. The results demonstrate that MobileVLM V2 achieves a new state-of-the-art trade-off between performance and inference speed across several vision language benchmarks.
Benchmarks
The benchmarks used in the evaluation include:
- Image question answering: GQA [hudson2019gqa], SQA [lu2022learn], TextVQA [singh2019towards]
- Comprehensive benchmarks: MME [fu2023mme], MMBench [liu2023mmbench]
- Object hallucination benchmark: POPE [li2023evaluating]
The primary performance metric is accuracy, measured across the various benchmarks. The paper also reports inference speed, measured in tokens per second, and latency on mobile devices.
Key Findings
The experimental results highlight the following key findings:
- MobileVLM V2 outperforms previous models with clear margins, achieving a 75% faster speed than MoE-LLaVA-2.7B×4 [lin2024moellava] while also outperforming it by 1.4 points on the average score.
- MobileVLM V2 models are generally faster and stronger in terms of token generation and average scores.
- Scaling the model to 7B parameters results in further performance improvements.
Latency Comparison
(Figure 2) shows the latency comparison of SOTA VLMs on an NVIDIA A100 GPU. MobileVLM V2 models exhibit faster token generation and higher average performance.
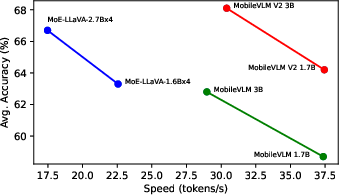
Figure 2: Speed comparison of SOTA VLMs on an NVIDIA A100 GPU. The accuracy is averaged on six VLM benchmarks (see Table~\ref{tab:compare-with-sotas-vlms}).
Model Scaling
(Figure 3) shows the average performance improvement on six VLM benchmarks when scaling MobileVLM V2's models.
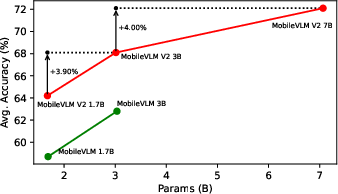
Figure 3: Average performance improvement on six VLM benchmarks when scaling MobileVLM V2's models across several standard tasks (see also Table~\ref{tab:compare-with-sotas-vlms}).
(Figure 4) shows a radar plot comparing MobileVLM V2's performance with other models.
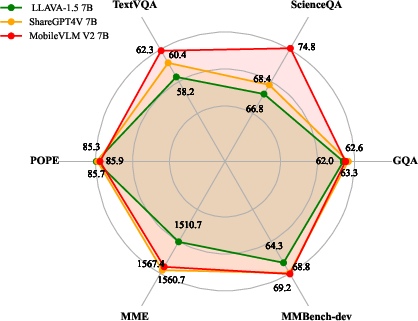
Figure 4: Radar plot of MobileVLM V2's performance compared with its peers on 6 standard benchmarks.
Mobile Device Latency
On the NVIDIA AGX Jetson Orin platform, MobileVLM V2 demonstrates a lower inference latency than its counterparts at the same parameter scale. The lightweight projector design contributes to this improved performance.
Ablation Studies
Ablation studies validate the impact of data scaling, training strategy, and projector design on the overall performance of MobileVLM V2.
(Figure 5) shows examples of MobileVLM V2 1.7B in various scenes.

Figure 5: Examples of MobileVLM V2 1.7B in various scenes.
Implications and Future Directions
The MobileVLM V2 architecture presents a significant advancement in efficient vision LLMs. Its ability to achieve high performance with relatively small model sizes and low latency makes it well-suited for deployment on resource-constrained devices. The improvements in data utilization, training strategies, and projection mechanisms offer valuable insights for future research in this area. The observation that the latency gap narrows upon the 7B model suggests that future work could focus on effectively utilizing high-resolution inputs. Additionally, exploring open and more powerful small LLMs remains a promising avenue for future research. In principle, MobileVLM V2 can also be combined with MoE designs to achieve higher performance, but how to do so without sacrificing the memory and latency advantage of MobileVLM V2 remains as future work.
Conclusion
MobileVLM V2 advances the state-of-the-art in efficient VLMs through innovations in data, training, and architecture. The result is a high-performing, low-latency model suitable for real-world deployment in resource-constrained environments.

