- The paper presents VectorMesh, a dense tensor accelerator that minimizes repetitive DRAM fetches using mesh FIFOs, achieving a 2-22x reduction in bandwidth requirements.
- It employs a butterfly network based data routing and fine-grained tiling within Tile Execution Units to optimize data reuse and enhance on-chip storage efficiency.
- Experimental results demonstrate that VectorMesh significantly improves performance for DNN, CNN, and spatial matching workloads, bringing execution closer to theoretical limits.
A Dense Tensor Accelerator with Data Exchange Mesh for DNN and Vision Workloads
The paper introduces a cutting-edge dense tensor accelerator named VectorMesh designed for enhancing the performance and efficiency of deep neural networks (DNN) and computer vision workloads. This essay explores the architecture, capabilities, and practical implications of implementing VectorMesh, an insightful advancement in the field of dedicated hardware accelerators for AI tasks.
Introduction
The architectural design described targets a solution for the increasing computational demands of modern DNN and vision-based workloads without corresponding growth in DRAM bandwidth. VectorMesh employs densely packed processing elements (PEs) and leverages a Tile Execution Unit (TEU)-based design, embodying several processing elements connected via a butterfly network alongside SRAM buffers. The novel integration of mesh-structured FIFOs between TEUs effectively allows for data sharing and minimizes redundancy by promoting global data visibility while decreasing the necessity for repetitive DRAM fetches, as demonstrated by the architecture's alignment with the roofline model for CNN, GEMM, and spatial matching workloads.
VectorMesh Architecture
The VectorMesh architecture builds upon a network of interconnected Tile Execution Units (TEUs). Each TEU incorporates multiple PEs and local SRAM buffers organized through a butterfly network for efficient data routing, resulting in a simplistic yet effective architecture (Figure 1).
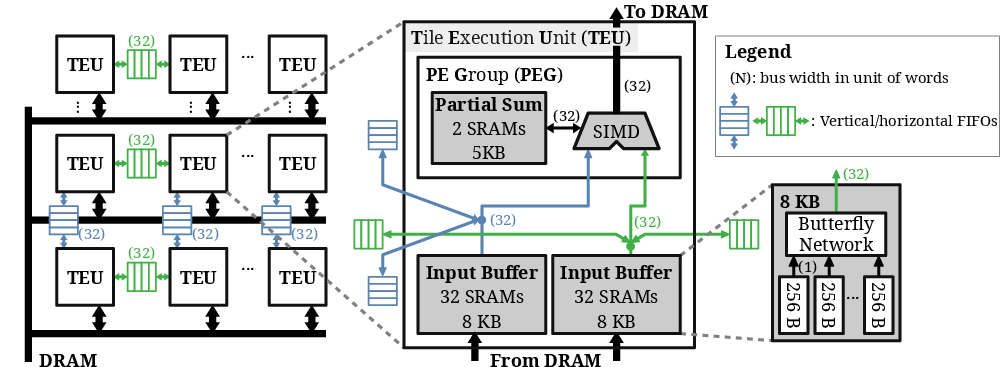
Figure 1: \bf The VectorMesh architecture. \normalfont The architecture can execute the workloads such as DNN, CNN, and spatial matching. Using classic butterfly networks for data routing results in a simple yet efficient design.
Key features of VectorMesh include the use of mesh FIFOs to facilitate local data exchange without redundancy, thereby preserving on-chip storage space. Each TEU contains its processing elements (PEs) supported by local SRAM and PSum buffers, with a butterfly network ensuring efficient data routing (Figure 1). This design allows for effective execution of a diverse array of workloads including DNNs and spatial matching algorithms.
Figure 1: \bf The VectorMesh architecture. \normalfont The architecture can execute the workloads such as DNN, CNN, and spatial matching. Using classic butterfly networks for data routing results in a simple yet efficient design.
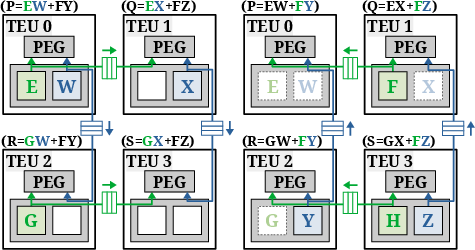
Figure 2: \normalfont The data sharing mechanism ensures all input buffers store unique data, maximizing the utilization of SRAMs.
Experiments and Results
Experiments using a cycle-level simulator illustrate the enhanced efficiency and versatility of VectorMesh, demonstrating significant improvements in bandwidth efficiency and area utility compared to existing architectures like TPU and Eyeriss.

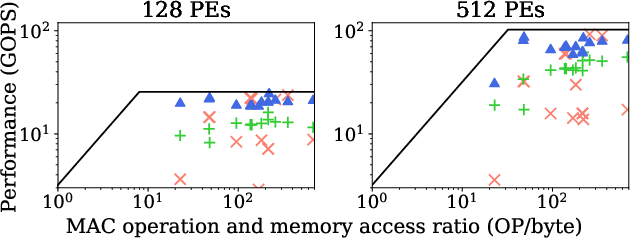
Figure 3: \bf Architectural comparisons using the roofline analysis against the workloads in tab:#1{exp:standard_cnn}.
Architectural Efficiency
VectorMesh achieves superior performance due to its ability to support a wide range of workloads, including DNN and computer vision applications. The architecture exploits a fine-grained tiling mechanism within its TEUs, bolstering data reuse and hence, reducing DRAM and global buffer fetches significantly, by factors of 2-22 times and up to 5 times, respectively, when benchmarked against leading architectures like TPU and Eyeriss.
Workload Support and Scheduling
By formulating workloads as tensors, VectorMesh can efficiently decompose them into tiles, achieving improved parallelism without underutilizing local buffers. This tiling strategy, when combined with the unique data sharing through mesh FIFOs, facilitates high throughput with minimal data duplication between local and global buffers.
Experimental Results
The performance evaluation through simulations demonstrated that VectorMesh provides a notable advantage by running DNN workloads closer to their theoretical performance limits (Figure 3). It offers remarkable reduction in data fetches from global and DRAM buffers, evidenced by a reduction factor of 2-22 times and up to 5 times less than existing architectures like TPU and Eyeriss for various workload configurations.
Figure 3: Architectural comparisons using the roofline analysis against the workloads in tab:#1{exp:standard_cnn}.
For modern CNN architectures and spatial matching workloads, the VectorMesh not only supported conventional layers but showed superior adaptability and performance optimization (Figure 4). Importantly, this adaptation is achieved through an efficient data routing protocol enabled by classic butterfly networks and strategic PE synchronization.
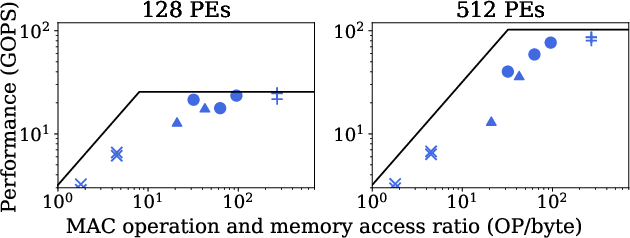
Figure 4: \bf Roofline analysis for workloads supported exclusively by VectorMesh.
Conclusion
The VectorMesh architecture represents a significant stride forward in the specialization of hardware to efficiently handle a variety of intensive DNN and vision workloads. By emphasizing efficient data exchange via mesh FIFOs and implementing robust workload scheduling, VectorMesh presents a practical, highly scalable, and resource-efficient solution. Future exploration may focus on further optimization methods for specific workloads, particularly within the rapidly evolving landscape of deep learning applications. As implementational challenges and theoretical advancements continue to surface, VectorMesh delineates a significant step towards optimizing the synergy between hardware design and DNN execution.