- The paper introduces Memory Decoder, a pretrained, plug-and-play memory that adapts large language models to domain-specific data without modifying base parameters.
- It employs a compact transformer decoder trained to mimic kNN retrieval distributions, achieving reduced perplexity and faster inference compared to traditional methods.
- Empirical results across GPT-2, Qwen2, and Llama3 models demonstrate improved scalability and robustness, bridging parametric and non-parametric domain adaptation approaches.
Memory Decoder: A Pretrained, Plug-and-Play Memory for LLMs
Motivation and Problem Setting
Domain adaptation for LLMs remains a critical challenge, particularly in specialized fields such as biomedicine, finance, and law, where domain-specific terminology and knowledge are essential for reliable performance. Traditional approaches—Domain Adaptive Pretraining (DAPT) and Retrieval-Augmented Generation (RAG)—present significant trade-offs. DAPT requires full-parameter retraining for each model, incurring high computational cost and risking catastrophic forgetting. RAG, while parameter-efficient, introduces substantial inference latency due to expensive nearest-neighbor searches and extended context processing.
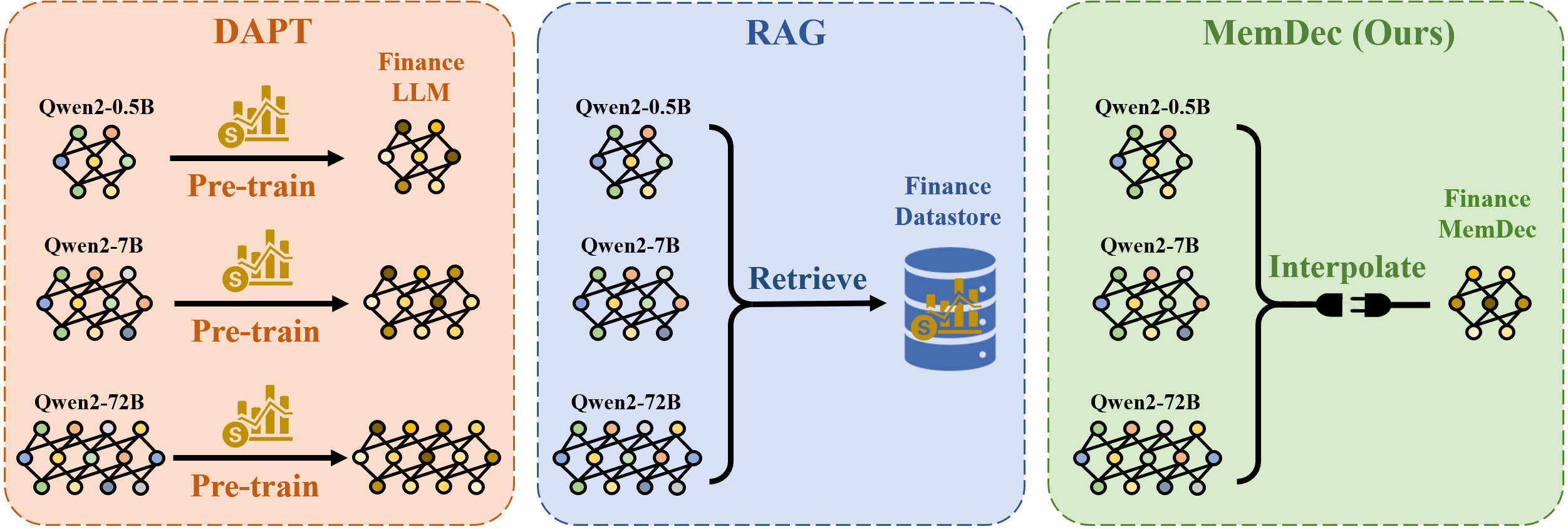
Figure 1: Comparison of domain adaptation approaches. DAPT modifies model parameters per size, RAG incurs retrieval overhead, while Memory Decoder enables plug-and-play adaptation without parameter modification or retrieval latency.
The Memory Decoder (MemDec) paradigm addresses these limitations by introducing a pretrained, plug-and-play memory module that can be interpolated with any LLM sharing the same tokenizer, enabling efficient domain adaptation without modifying the base model or incurring retrieval overhead.
Architecture and Training Procedure
Memory Decoder is implemented as a compact transformer decoder, pretrained to imitate the output distribution of non-parametric retrievers (e.g., kNN-LM) on domain-specific corpora. The pretraining objective is a hybrid loss: KL divergence between the Memory Decoder's output and the kNN distribution, regularized by standard cross-entropy to maintain corpus-level linguistic coherence. This approach enables the Memory Decoder to internalize the retrieval-based knowledge into its parameters, effectively compressing the information from large key-value datastores.
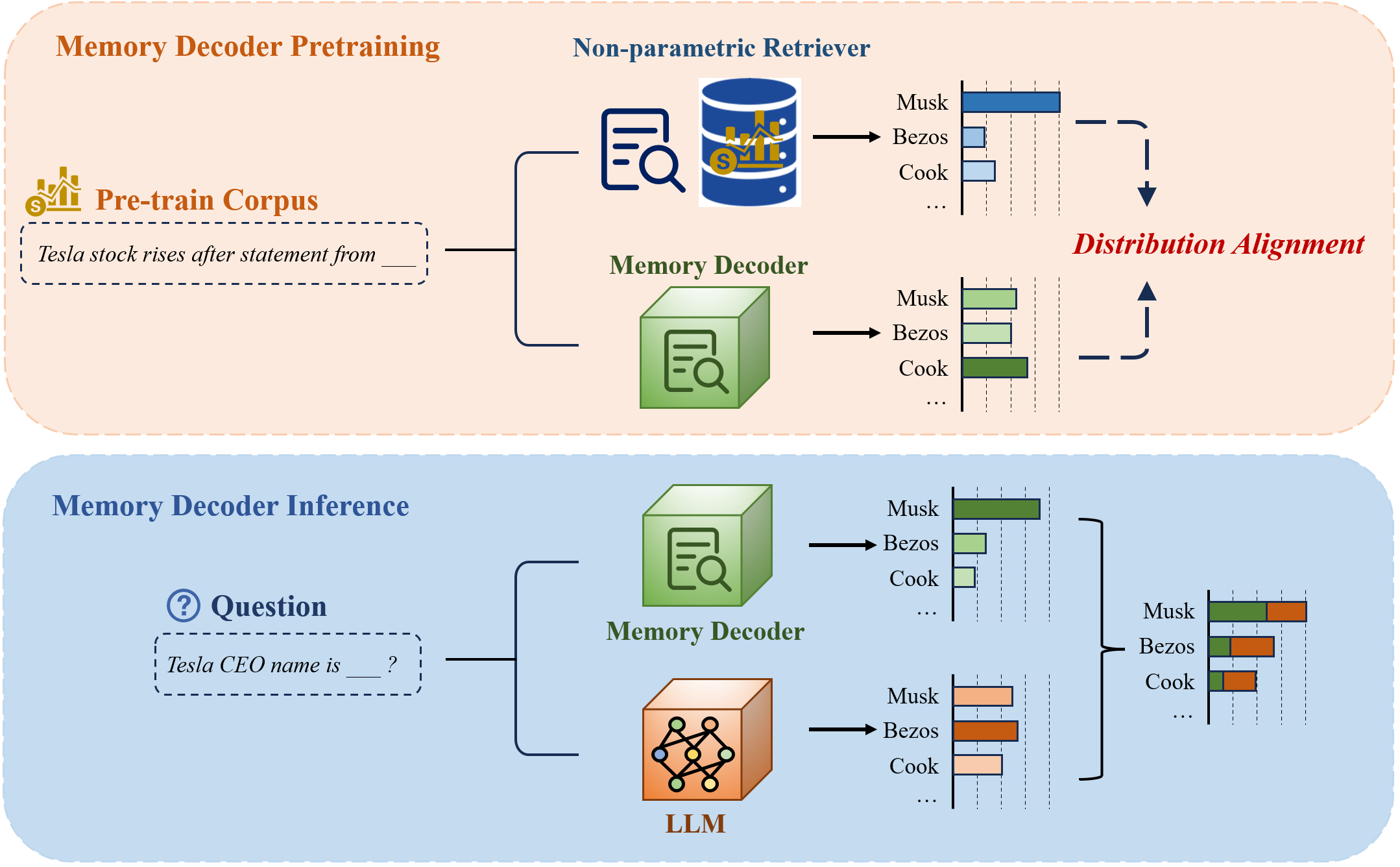
Figure 2: Overview of Memory Decoder architecture. Pretraining aligns the decoder's output with kNN distributions; inference interpolates its output with the base LLM for domain-enhanced predictions.
During inference, both the base LLM and the Memory Decoder process the input context in parallel. Their output distributions are linearly interpolated, controlled by a hyperparameter α, to produce domain-adapted predictions. This design ensures minimal inference overhead—only a single forward pass through the small decoder—contrasting sharply with the latency of RAG and kNN-LM.
Empirical Results and Analysis
Language Modeling and Downstream Tasks
Memory Decoder demonstrates strong empirical performance across multiple model families (GPT-2, Qwen2, Llama3) and domains. On WikiText-103, a single 124M parameter Memory Decoder consistently improves perplexity across all GPT-2 variants, outperforming DAPT and LoRA, and matching or exceeding kNN-LM without retrieval cost. Notably, for GPT2-medium, Memory Decoder achieves lower perplexity than DAPT, despite not modifying the base model.
On nine diverse NLP tasks, Memory Decoder preserves or improves general language capabilities in zero-shot settings, avoiding the catastrophic forgetting observed in DAPT, which suffers severe degradation on tasks such as textual entailment and open-domain classification.
Cross-Model and Cross-Vocabulary Adaptation
A single Memory Decoder (0.5B parameters) can be integrated with Qwen2 and Qwen2.5 models ranging from 0.5B to 72B parameters, consistently reducing perplexity and outperforming LoRA. The same decoder, with minimal retraining (10% of original budget), can be adapted to Llama3 models, achieving substantial improvements in biomedical and financial domains. This cross-model and cross-tokenizer generalizability is a key practical advantage, enabling efficient domain adaptation across heterogeneous model ecosystems.
Inference Efficiency
Memory Decoder achieves significant inference speedup compared to RAG and kNN-LM. On Qwen2.5-1.5B, Memory Decoder incurs only 1.28× overhead relative to the base model, compared to 2.17× for kNN-LM. The efficiency gap widens with larger datastores, as Memory Decoder's cost remains constant while kNN search scales linearly.
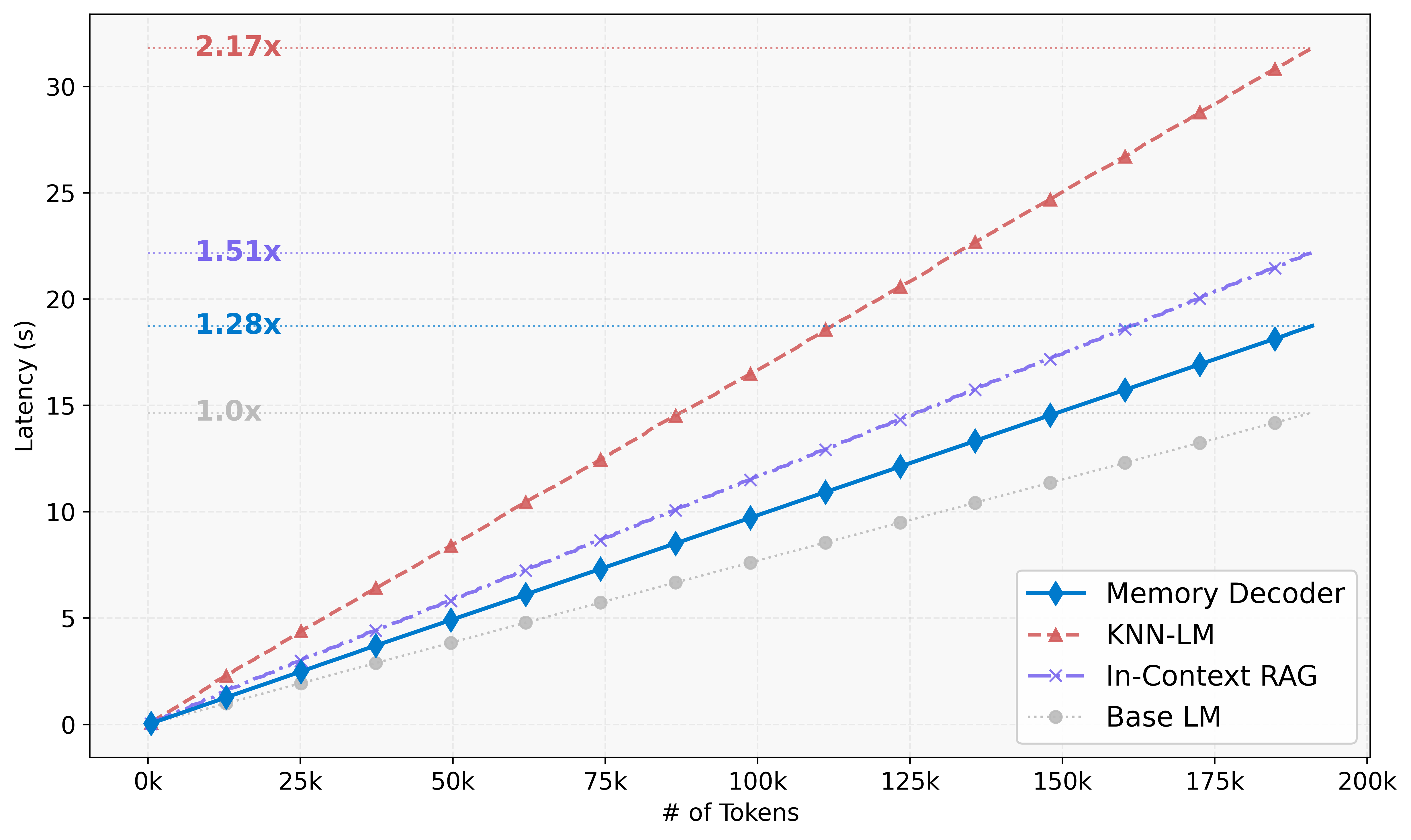
Figure 3: Inference latency comparison across domain adaptation methods. Memory Decoder achieves substantially lower latency than RAG and kNN-LM.
Knowledge-Intensive Reasoning
On knowledge-intensive QA tasks (Natural Questions, HotpotQA), Memory Decoder provides substantial improvements over both the base model and kNN-LM, which can degrade performance due to shallow reasoning. By internalizing retrieval patterns, Memory Decoder maintains compositional reasoning while enhancing factual recall.
Distributional Properties
Memory Decoder successfully mimics the extreme sparsity and concentration of kNN distributions, assigning high probability mass to long-tail factual tokens while maintaining semantic coherence for function words and logical continuations. This dual capability enables best-of-both-worlds behavior: memorization of domain-specific knowledge and preservation of generalization.
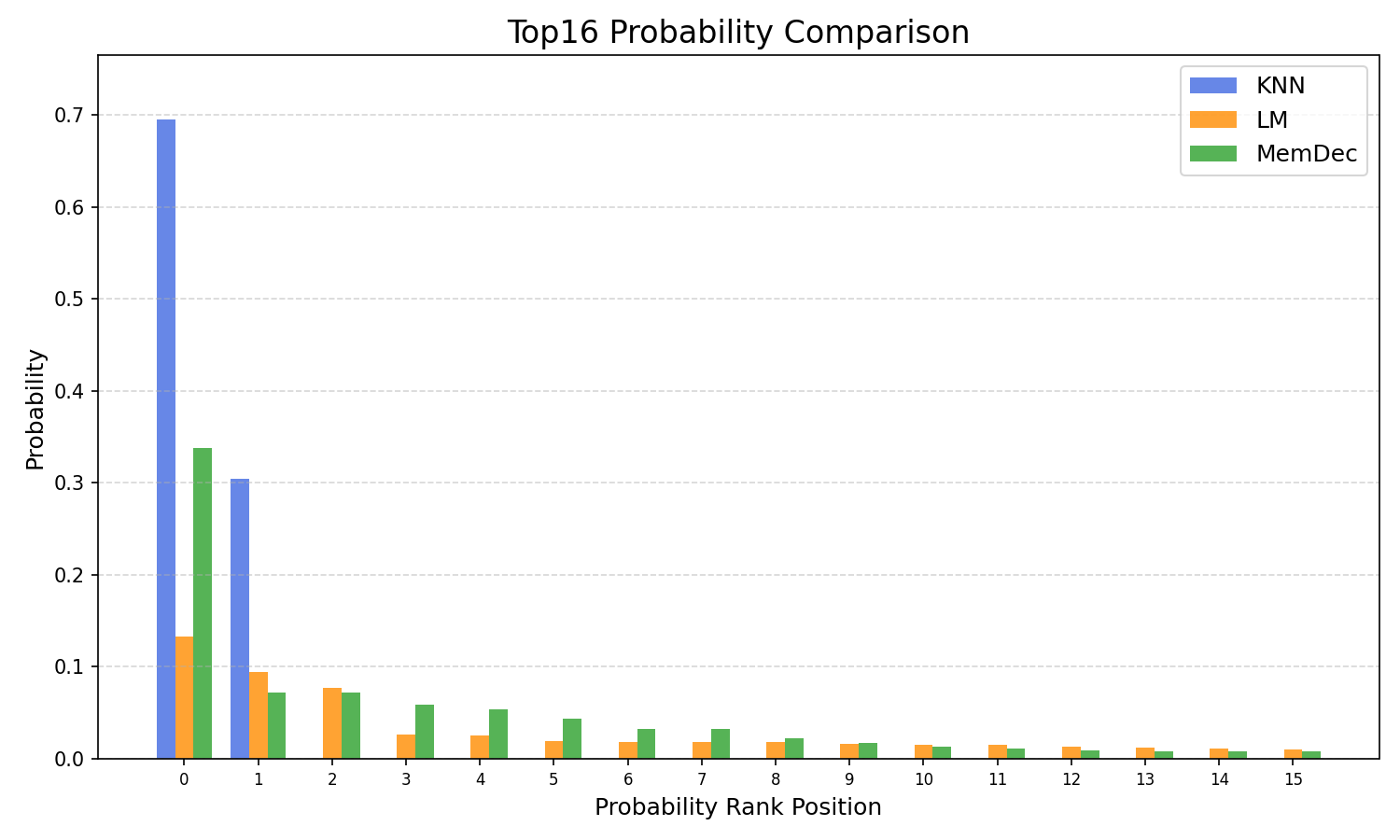
Figure 4: Probability distributions from k-NN retrieval, standard LM, and Memory Decoder for GPT-2-Large. k-NN distribution is highly sparse; Memory Decoder closely matches this pattern.
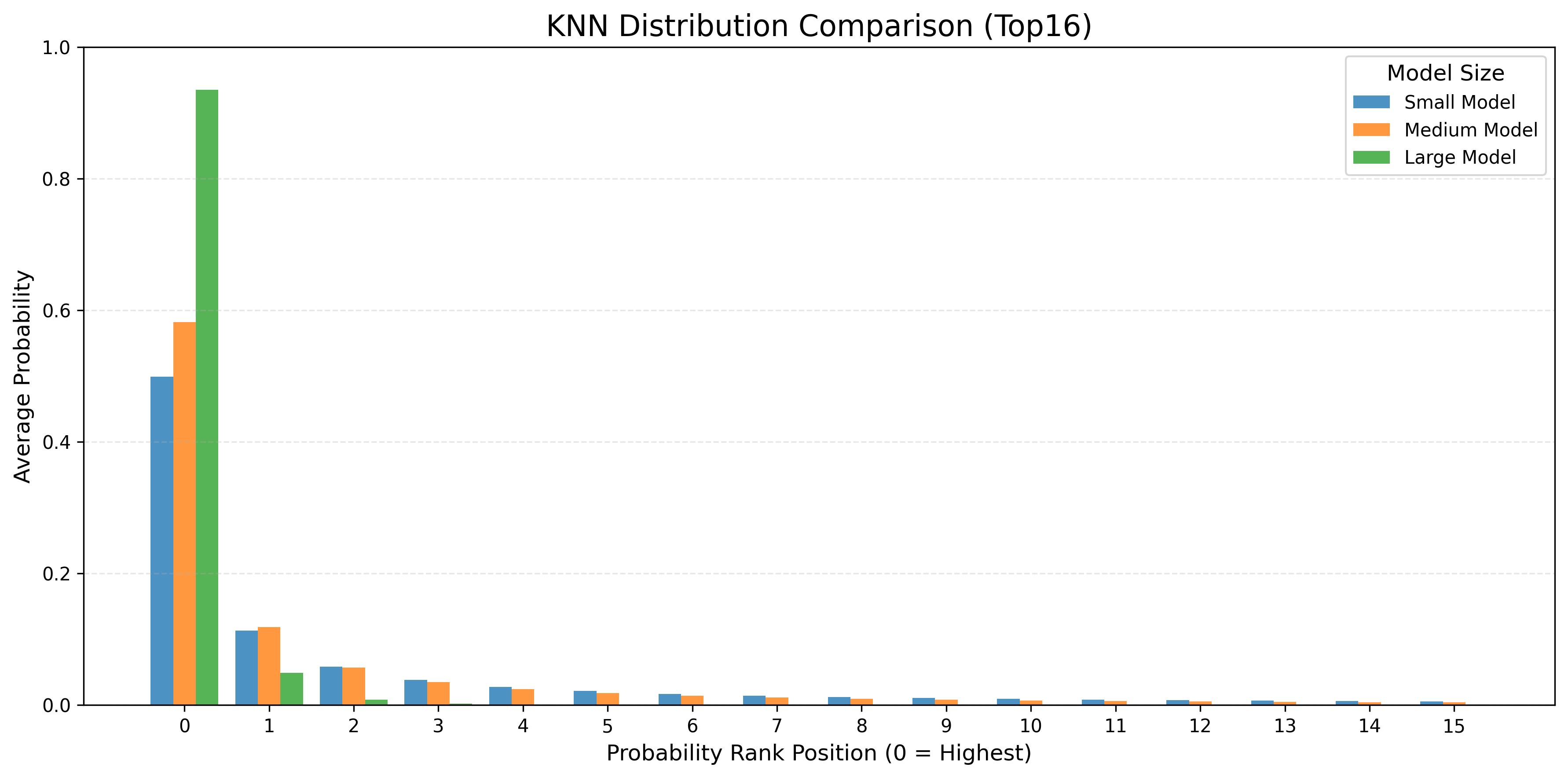
Figure 5: k-NN distribution sparsity across model scales. Larger models yield sparser distributions, which Memory Decoder effectively emulates.
Ablation and Sensitivity Studies
Memory Decoder's performance is robust to the interpolation parameter α, with less than 2.5% variation across a wide range. Decoder size ablation shows that even small decoders (117M) achieve competitive results with DAPT, and larger decoders further improve performance. Hybrid training (KL + CE) outperforms single-objective variants, confirming the necessity of both distribution alignment and corpus supervision.
Implementation Considerations
- Pretraining Cost: Requires kNN distribution computation over the domain corpus, incurring one-time cost amortized across all adapted models.
- Plug-and-Play Integration: No modification of base model parameters; integration is via distribution interpolation at inference.
- Cross-Tokenizer Adaptation: Minimal retraining required to align embedding spaces; not strictly zero-shot but highly efficient.
- Deployment: Suitable for production environments where inference efficiency and modularity are critical.
Theoretical and Practical Implications
Memory Decoder introduces a modular paradigm for domain adaptation, decoupling domain expertise from model architecture. This enables scalable specialization of LLMs without retraining or parameter modification, facilitating rapid deployment in specialized domains. The approach bridges parametric and non-parametric methods, internalizing retrieval-based knowledge while preserving reasoning and generalization.
Theoretically, the success of KL divergence in matching kNN distributions highlights the importance of asymmetric, mode-seeking objectives for learning sparse, retrieval-like distributions. The plug-and-play architecture suggests future directions in modular LLM design, where specialized memory components can be dynamically composed with general models.
Future Directions
- Zero-Shot Cross-Architecture Transfer: Further research into embedding alignment could enable true zero-shot adaptation across tokenizer families.
- Dynamic Memory Composition: Investigating multiple domain-specific decoders for multi-domain adaptation.
- Continual Learning: Extending Memory Decoder to support continual domain adaptation without retraining.
- Integration with In-Context Learning: Exploring synergies between Memory Decoder and advanced prompting strategies.
Conclusion
Memory Decoder provides an efficient, versatile, and modular solution for domain adaptation in LLMs. By pretraining a compact transformer decoder to emulate non-parametric retrieval distributions, it enables plug-and-play integration with any compatible LLM, achieving strong empirical gains in perplexity, downstream task performance, and inference efficiency. The approach preserves general capabilities, avoids catastrophic forgetting, and generalizes across model families and tokenizers with minimal retraining. Memory Decoder establishes a new paradigm for scalable, modular domain adaptation in LLMs, with significant implications for both research and practical deployment.