- The paper introduces DRAG, a framework that distills retrieval-augmented generation from LLMs to SLMs, reducing hallucinations and improving factual accuracy.
- The framework employs a multi-stage process combining evidence generation, ranking, and graph-based knowledge representation to optimize computational efficiency.
- Experimental results on benchmarks like ARC-C, MedMCQA, and MMLU show DRAG outperforms prior methods with improvements up to 27.7%.
DRAG: Distilling RAG for SLMs from LLMs to Transfer Knowledge and Mitigate Hallucination via Evidence and Graph-based Distillation
Introduction
The research introduces DRAG, a framework designed to distill Retrieval-Augmented Generation (RAG) techniques from LLMs to smaller LLMs (SLMs). DRAG addresses the challenges of computational inefficiency and hallucination in existing RAG systems by leveraging evidence- and graph-based distillation methods. This is crucial for optimizing RAG frameworks for deployment in resource-constrained environments without compromising factual accuracy or retrieval capabilities.
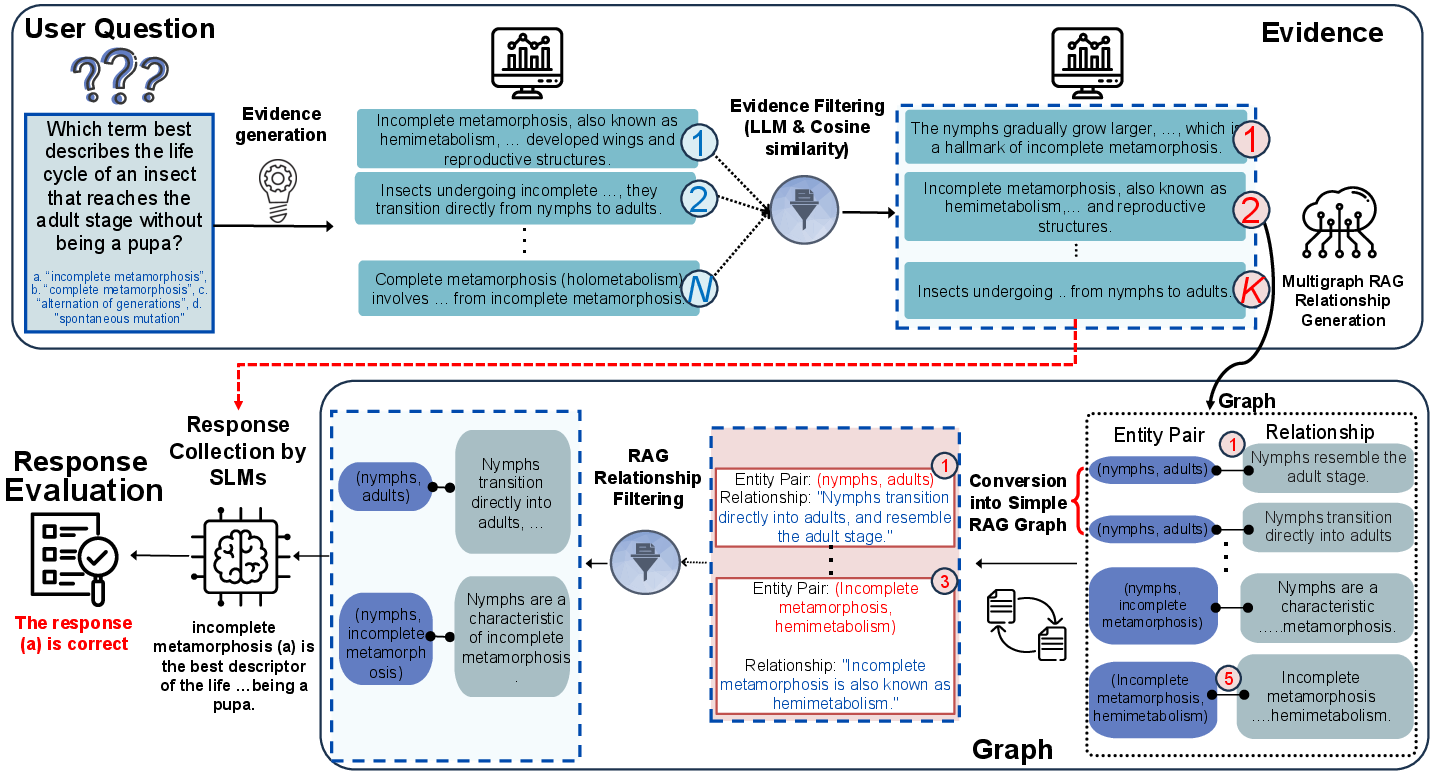
Figure 1: Framework Overview of Our Evidence- and Graph-based RAG Distillation. Given a user query, the approach processes and distills the necessary information through structured evidence and graph-based mechanisms.
Methodology
DRAG operates through a multi-stage process encompassing evidence generation, evidence ranking, graph-based knowledge representation, and application in SLM evaluation. Initially, evidence relevant to a specific query is generated using a large-scale LLM (Figure 1). This evidence is ranked and filtered to ensure relevance and accuracy. Subsequently, structured knowledge in the form of graphs is extracted, capturing essential entity relationships without the redundancy of raw text.
The final stage employs SLMs to generate accurate and contextually grounded responses using the distilled knowledge. This ensures mitigation of hallucination and enhances efficiency, aligning the smaller model's predictions with factual evidence and ranked knowledge graphs.
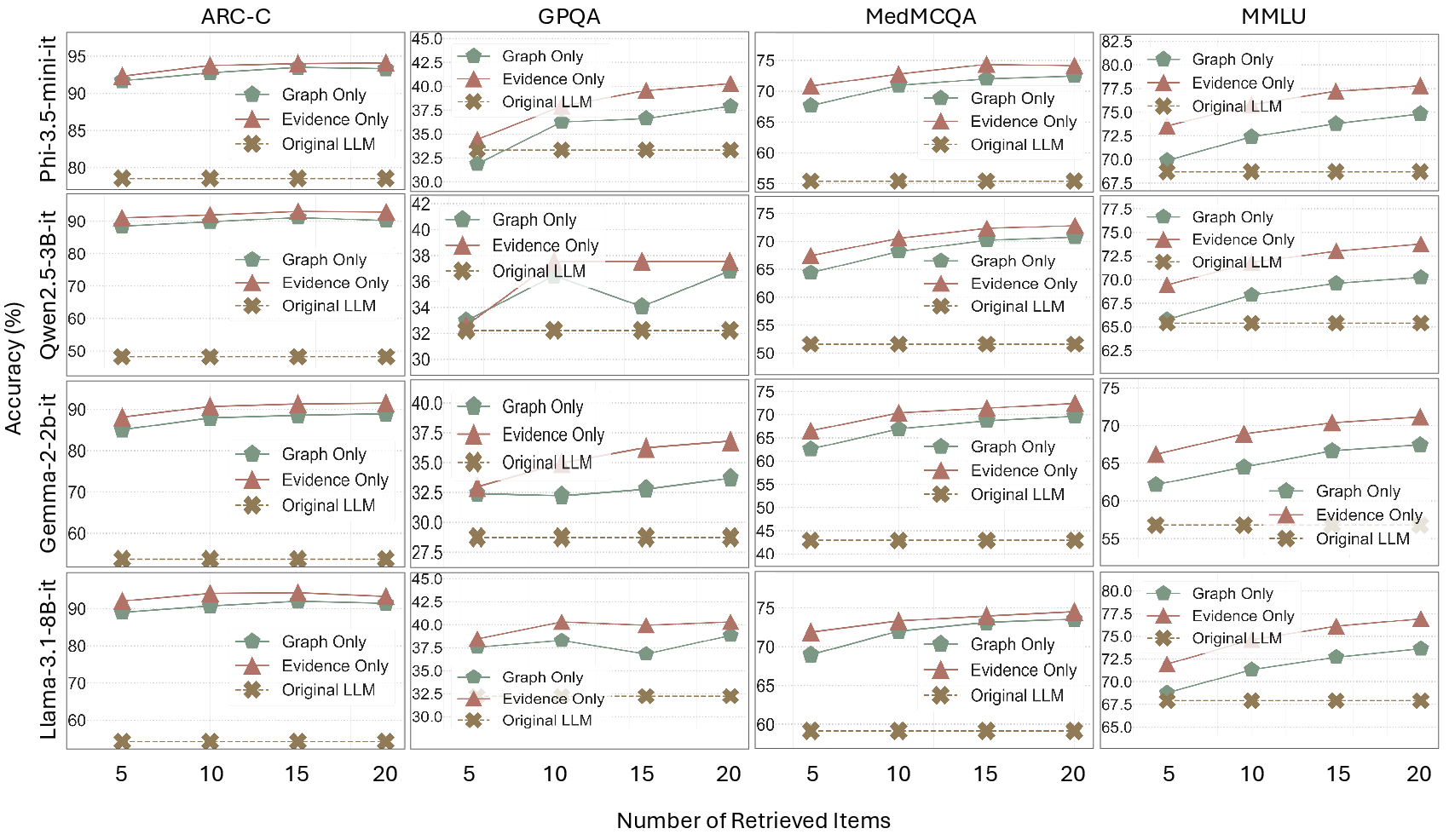
Figure 2: Effect of retrieved graph-based and evidence-based RAG on multiple-choice QA tasks, demonstrating superior accuracy and consistency.
Experimental Results
DRAG's efficacy is illustrated through evaluations on multiple benchmarks such as ARC-C, MedMCQA, and MMLU. The results reveal that DRAG outperforms existing methods like MiniRAG and SimRAG by substantial margins, particularly in factual accuracy and computational efficiency. For instance, DRAG achieved a 93.0% score on ARC-C, representing a 27.7% improvement over prior methods.
In addition, DRAG showcases competitive performance across diverse LLMs and SLMs, reinforcing its robustness and adaptability in various retrieval-augmented scenarios. The framework's ability to enhance factual accuracy while preserving computational resources is a significant advantage for real-world applications.
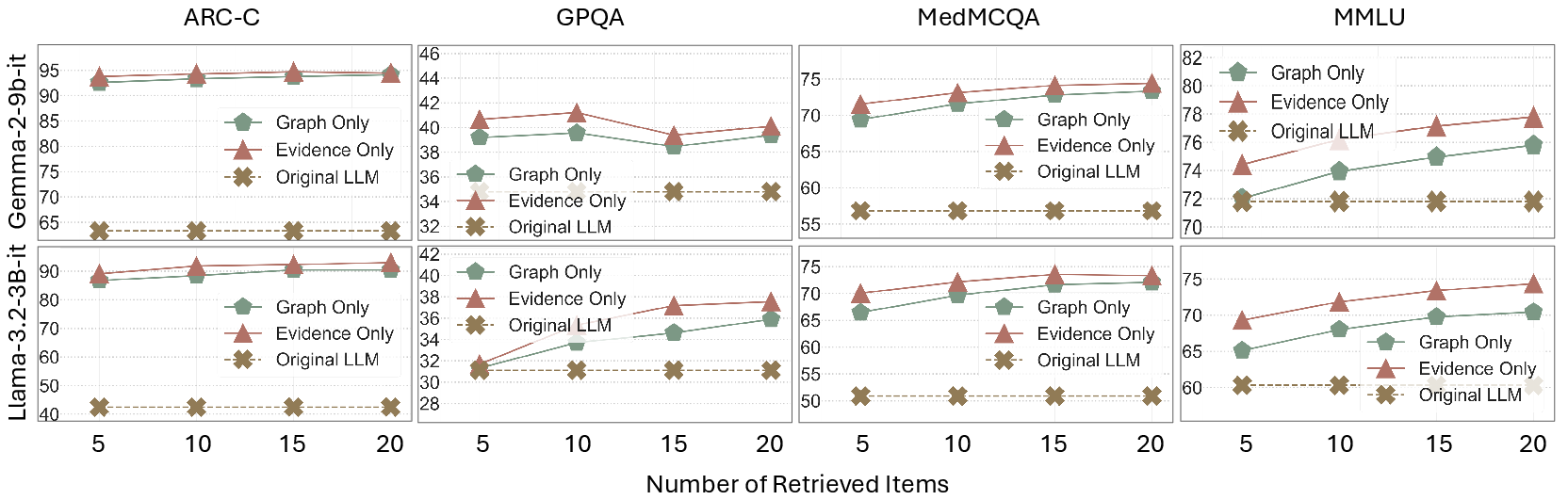
Figure 3: More results on Retrieval Strategies, illustrating the comparative effectiveness of different approaches in harnessing retrieved knowledge.
Implications and Future Directions
The DRAG framework sets a new precedent for the deployment of retrieval-augmented generation techniques in small-scale LLMs. By marrying evidence-based and graph-based distillation, DRAG successfully bridges the resource-efficiency gap between large and small LLMs. Furthermore, its introduction of a privacy-preserving mechanism highlights additional practical utilities.
Future research could explore further optimizations in the evidence and ranking processes, potentially incorporating more sophisticated privacy mechanisms and extending the framework's applicability to broader LLM architectures and domains.
Conclusion
DRAG represents a significant advancement in the distillation of retrieval-augmented generation capabilities, offering a scalable solution that balances accuracy, efficiency, and factual consistency. Its success in enhancing small LLM performance underscores its potential for widespread adoption in environments demanding computational and resource efficiency.