- The paper presents DisWM, which transfers semantic knowledge from distracting videos using disentangled representation learning to improve RL sample efficiency.
- It employs a beta-VAE pretraining phase combined with offline-to-online latent distillation to bridge domain gaps between video data and RL tasks.
- Empirical evaluations on benchmarks like DMC and MuJoCo show that DisWM outperforms baselines in handling visually distracting environments.
Disentangled World Models: Learning to Transfer Semantic Knowledge from Distracting Videos for Reinforcement Learning
Abstract
The discussed paper introduces Disentangled World Models (DisWM), a reinforcement learning (RL) framework that addresses sample efficiency in visually distracting environments by transferring semantic knowledge from distracting videos. The method incorporates disentangled representation learning and latent distillation from pretrained video models to enhance RL in complex tasks. The essence of this approach lies in its capability to pretrain on action-free videos, distill this knowledge to model-based RL environments, and fine-tune in these environments with advantaged semantic interpretations.
Overview of Disentangled World Models
DisWM is premised on pretraining a video prediction model with disentangled representation learning, bearing no action or reward signals (Figure 1). This offline phase focuses on extracting robust semantic features through a β-VAE framework. Subsequently, these semantic features are transferred online via latent distillation. During the reinforcement learning phase, the action-conditioned world model undergoes further refinement, now incorporating interactions of actions and rewards, which augment the diversity of visual observations and reinforce learning efficiency.
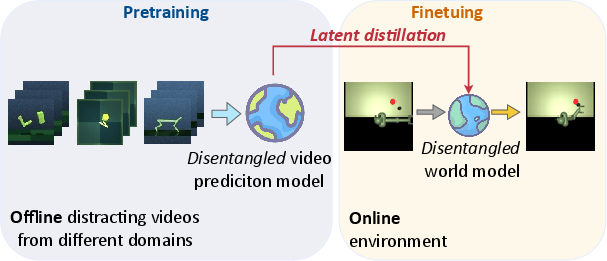
Figure 1: Overview of our proposed framework. The key idea is to leverage distracting videos for semantic knowledge transfer, enabling the downstream agent to improve sample efficiency on unseen tasks.
Pretraining Framework
The pretraining stage employs a β-VAE to encode video observations into latent spaces, where disentanglement constraints are enforced to ensure robust feature separation (Figure 2). This phase attempts to predict future latent states while reinforcing the disentangled preservation of features across varied videos devoid of action and reward inputs. These latent spaces are theorized to be close to isotropic Gaussian, enhancing latent orthogonality and reducing interdependencies.
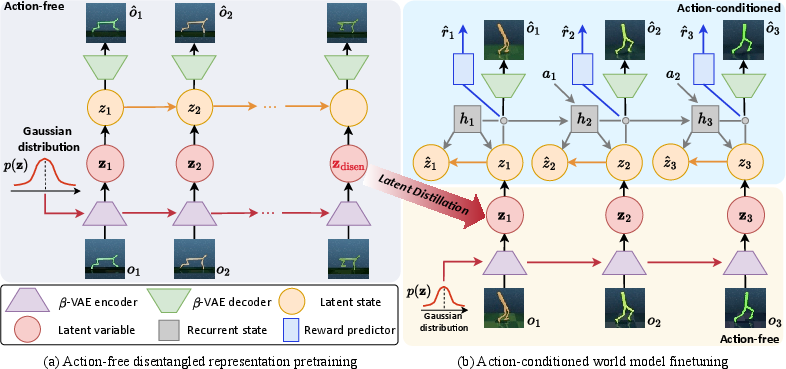
Figure 2: Architecture of Disentangled World Models. The action-free video prediction model with disentanglement constraints is pretrained on distracting videos offline for well-disentangled latent variable z, which extracts semantic knowledge from the visual observations.
Offline-to-Online Latent Distillation
Transitioning from offline to online stages, the latent distillation bridges domain discrepancies encountered between the video data and RL tasks. The KL divergence between the offline zdisen and the online ztask acts as a formal measure to distill learned disentangled capabilities into the RL models. This critical adaptation phase underpins the semantic transfer, ensuring the latent space excels in subsequent reinforcement tasks.
World Model Adaptation
Upon initialization with latent knowledge, the world model adaptation fine-tunes in real environments (Figure 3). It capitalizes on disentangled latents to predict rewards, actions, and transitions, incorporating environment-specific alterations. By leveraging disentanglement loss and latent distillation co-modulated by hyperparameter tuning, the model adeptly handles environmental unpredictabilities.

Figure 3: Example image observations of our modified DMC and MuJoCo Pusher with color distractors.
Experimental Evaluation
DisWM demonstrates empirical strength across standard benchmarks like DeepMind Control Suite and MuJoCo Pusher. It consistently shows superior learning curves, attributed to its prior semantic knowledge enriching agent actions and reward interpretations—a marked contrast against methods like TED and APV (Figure 4). The disentangled attributes enable it to maintain performance amidst visual distractions, such as varying object colors and motions.
(Figure 4)
Figure 5: Performance of DisWM on DMC showing superior efficiency in disentangled world model adaptation over other baselines.
Model Analysis
DisWM's methodical dissection includes ablation studies validating latent distillation efficacy and disentanglement constraints. Empirical results illustrate that absence of these components impedes model performance, underscoring their necessity. Sensitivity analyses fine-tune key parameters like the latent space dimension and disentanglement weights, verifying their impact on semantic disentanglement and RL results (Figures 5 and 6).
(Figures 5 and 6)
Figure 6: Visualization of traversals of beta-VAE during the pretraining phase.
Figure 7: Fine-grained disentanglement results on MuJoCo Pusher during world model adaptation phase. Each row showcases traversal results on specific attributes.
Conclusion
In conclusion, DisWM emerges as a robust framework fostering efficient transfer learning in reinforcement learning scenarios, particularly where visual distractions challenge agent acuity. Its combination of action-free pretraining and systematic latent distillation offers a progressive approach to semantic understanding and task execution. Future work may explore scaling DisWM to more complex, non-stationary environments, further optimizing its latent learning dynamics.