- The paper presents Lips, a neuro-symbolic framework that integrates LLMs with symbolic reasoning to generate human-readable and formally verifiable proofs for Olympiad inequalities.
- It employs a dual tactic strategy—scaling and rewriting—to optimize proof generation and boost effectiveness, outperforming existing methods by 7.92% on average.
- The approach utilizes specialized goal selection based on homogeneity and decoupling, enhancing automated theorem proving in complex mathematical domains.
Overview of "Proving Olympiad Inequalities by Synergizing LLMs and Symbolic Reasoning"
The paper "Proving Olympiad Inequalities by Synergizing LLMs and Symbolic Reasoning" (2502.13834) introduces Lips, a neuro-symbolic framework that integrates the mathematical intuition from LLMs with symbolic reasoning methods to generate human-readable and formally verifiable proofs for Olympiad-level inequality problems. The presented framework innovatively identifies the optimal roles for LLMs and symbolic tools within the proof generation process, focusing primarily on Olympiad inequalities through a combination of scaling and rewriting tactics. This integration promises advancements in automated theorem proving by overcoming the limitations of existing LLM-based tactic generation which is constrained by data scarcity.
Introduction
Automated theorem proving is a classical objective within AI, aiming to leverage LLMs to create formal proofs for mathematical theorems. Recent progress with LLMs has facilitated this task, yet their potential is restricted by the paucity of formal proof data and difficulties in executing symbolic manipulations. To address these shortcomings, the authors propose a synergy of symbolic reasoning with LLMs, utilizing domain-specific knowledge and circumventing extensive training data requirements. The paper narrows this idea to inequality proofs, exploiting symbolic methods to partition the problem space while LLMs handle complex rewriting processes.
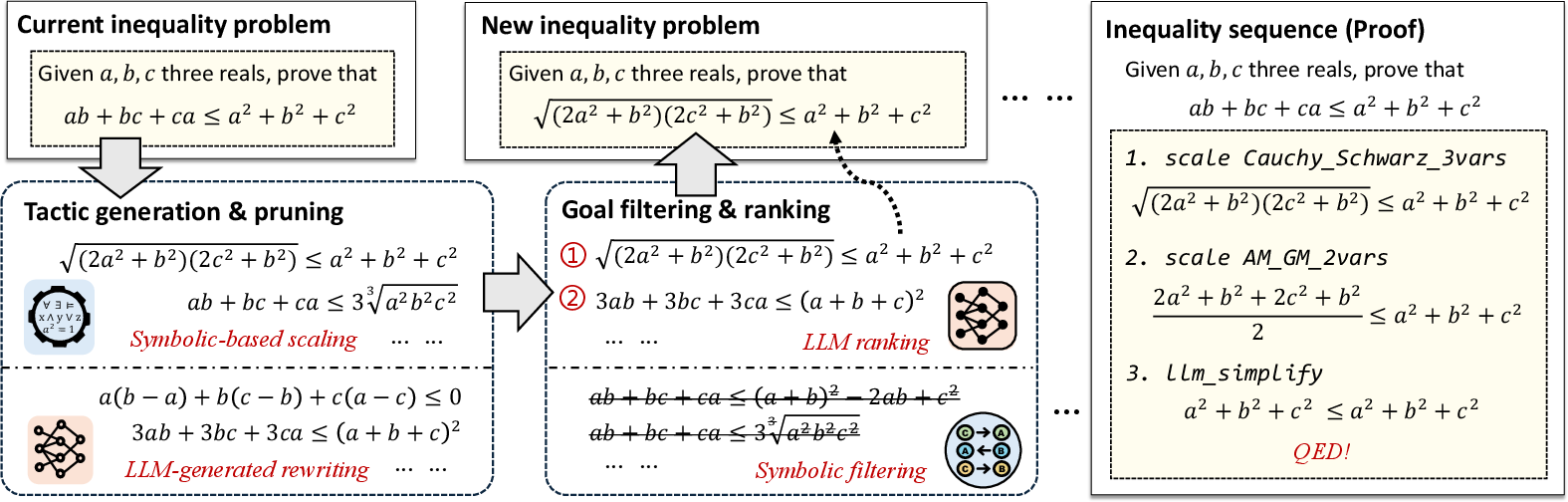
Figure 1: An overview of our neuro-symbolic inequality prover Lips. By integrating both LLMs and symbolic methods in an iterative process of tactic generation and goal selection, it can generate human-readable and formally verifiable proofs in Lean for Olympiad-level inequality problems.
Tactic Generation and Pruning
In tackling inequalities, the paper categorizes tactics into scaling and rewriting. Scaling leverages lemmas like the AM-GM inequality through symbolic pattern matching, while rewriting involves transformations, often infinite, facilitated by LLM-driven symbolic operations. This bifurcation is critical as scaling requires finite lemmas applied mechanically, whereas rewriting needs algebraic creativity. Lips uses symbolic tools to validate scaling tactics, ensuring deductions align with hypotheses, and employs an LLM-driven sample-selection strategy to generate effective rewriting transformations without exhaustive enumeration.
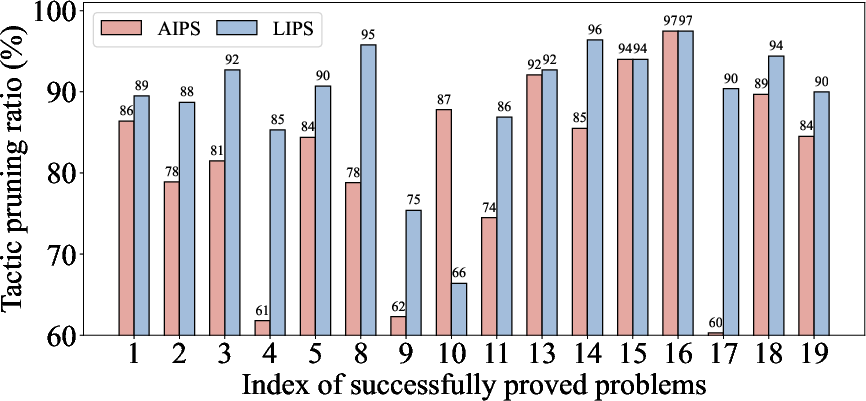
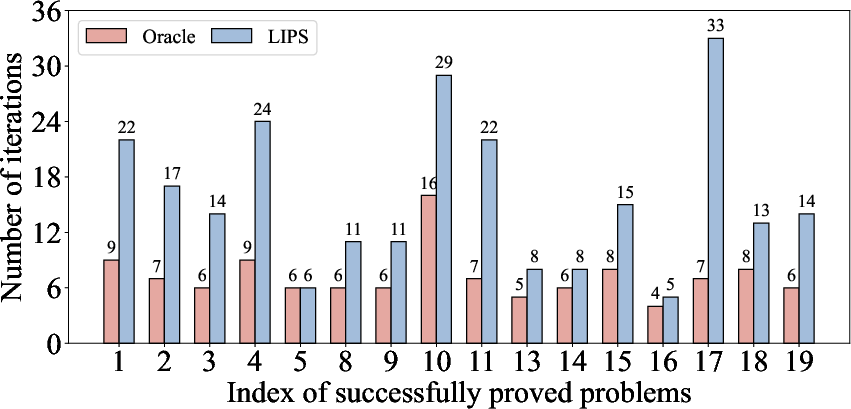
Figure 2: Tactic pruning ratio (uparrow, higher is better) and number of iterations (downarrow). The results illustrate that the tactic pruning method of Lips is very stable, and outperforms the existing method by 7.92\% on average.
Goal Filtering and Selection
The framework introduces strategic goal selection, utilizing symbolic filtering based on two properties: homogeneity and decoupling. Homogeneous inequalities allow extensible transformations, while decoupled terms facilitate simpler manipulation strategies. The filtered goals are then ranked by LLMs using chain-of-thought prompting, prioritizing clear, solvable paths through structured reasoning sequences.
Experimental Results
Lips was evaluated on datasets from math competitions, showcasing remarkable efficacy and efficiency in proving tasks. Experiments confirmed Lips’s superiority over existing neural and symbolic methods with significant improvements in problem-solving success rates and reduced computation times. The framework demonstrated scalability and adaptability, supporting expansions in tactic libraries and enhanced LLM reasoning capabilities.
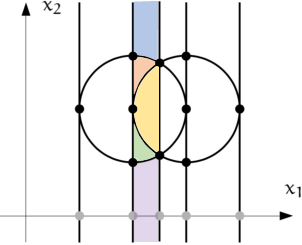
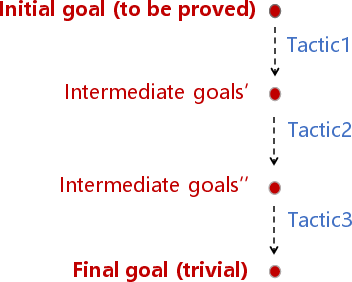

Figure 3: Figure (a) demonstrates how CAD is performed on two intersecting unit circles, deriving multiple sign-invariant cells. Figure (b) illustrates the process of inequality proving, constructing a chain of proof goals; Figure (c) provides a corresponding instantiation of proving ab+bc+ca≤a2+b2+c2.
Conclusion
This study presents a compelling case for synergizing LLMs with symbolic reasoning, marking significant strides in automated theorem proving. Lips efficiently balances symbolic approaches with neural insights, paving the way for automated reasoning across complex mathematical domains. Future research could focus on extending its application scope to higher-level mathematics, leveraging advanced symbolic methods alongside powerful neural networks. This synthesis of techniques offers a promising framework for future exploration in AI-driven mathematics.