- The paper introduces Archetypal SAE that embeds convex hull constraints to enhance the stability of dictionary learning in sparse autoencoders.
- It demonstrates a trade-off balancing reconstruction fidelity and sparsity, validated through extensive experiments on large vision models.
- The approach improves model interpretability and paves the way for applications in diverse domains beyond vision.
Archetypal SAE: Adaptive and Stable Dictionary Learning for Concept Extraction in Large Vision Models
Introduction
The paper "Archetypal SAE: Adaptive and Stable Dictionary Learning for Concept Extraction in Large Vision Models" (2502.12892) addresses a critical limitation in Sparse Autoencoders (SAEs), which have been prominent in machine learning for interpretability tasks by decomposing model representations into a dictionary of human-interpretable concepts. Despite their utility, SAEs exhibit significant instability, leading to inconsistent dictionaries across similar datasets, thus undermining reliability in interpretability applications. To tackle this issue, the authors introduce Archetypal SAEs, drawing inspiration from the Archetypal Analysis framework. This novel approach constrains dictionary atoms to the convex hull of the data, significantly enhancing stability while preserving state-of-the-art reconstruction abilities.
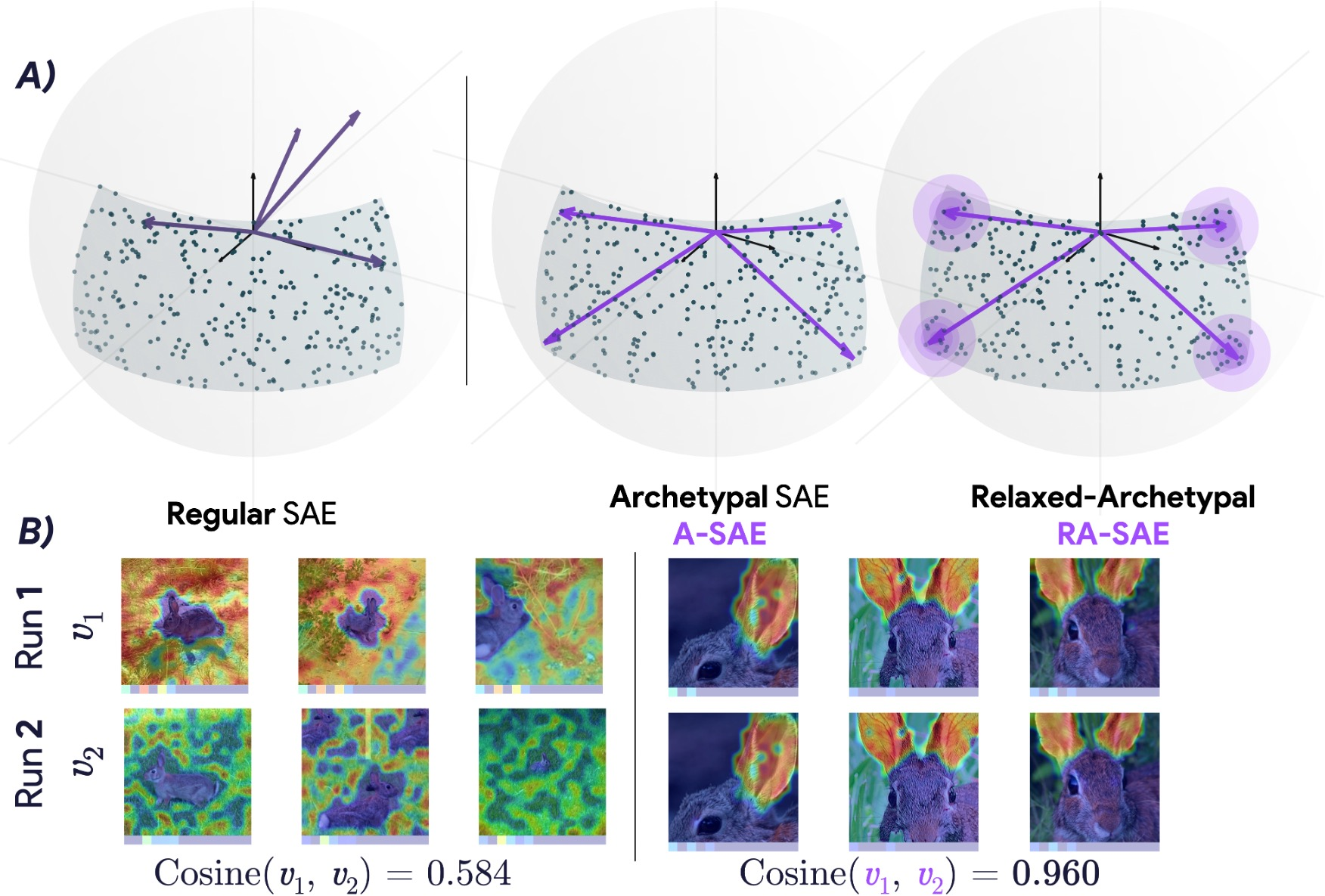
Figure 1: Archetypal-SAEs constrain dictionary atoms to the data's convex hull, improving stability, which contrasts the instability seen in standard SAEs.
Methodology
The framework proposed operates by mapping activations into a sparse concept space using dictionary learning methods. The optimization task involves minimizing reconstruction errors while adhering to sparsity constraints. Classical methods such as Non-negative Matrix Factorization and K-means have been utilized but lack modern scalability. Conversely, SAEs leverage backpropagation and batch-learning capabilities, making them appealing for large-scale datasets. However, these methods suffer from instability, leading to distinct dictionaries upon reruns, as demonstrated in recent empirical results.
Archetypal Sparse Autoencoder (A-SAE)
Archetypal SAEs introduce a geometric constraint by ensuring dictionary atoms reside within the convex hull of sample representations. This geometric anchoring yields substantial stability across training runs by preventing dictionary atoms from pointing in directions unrelated to the dataset.
Experimental Validation
Stability and Reconstruction Trade-offs
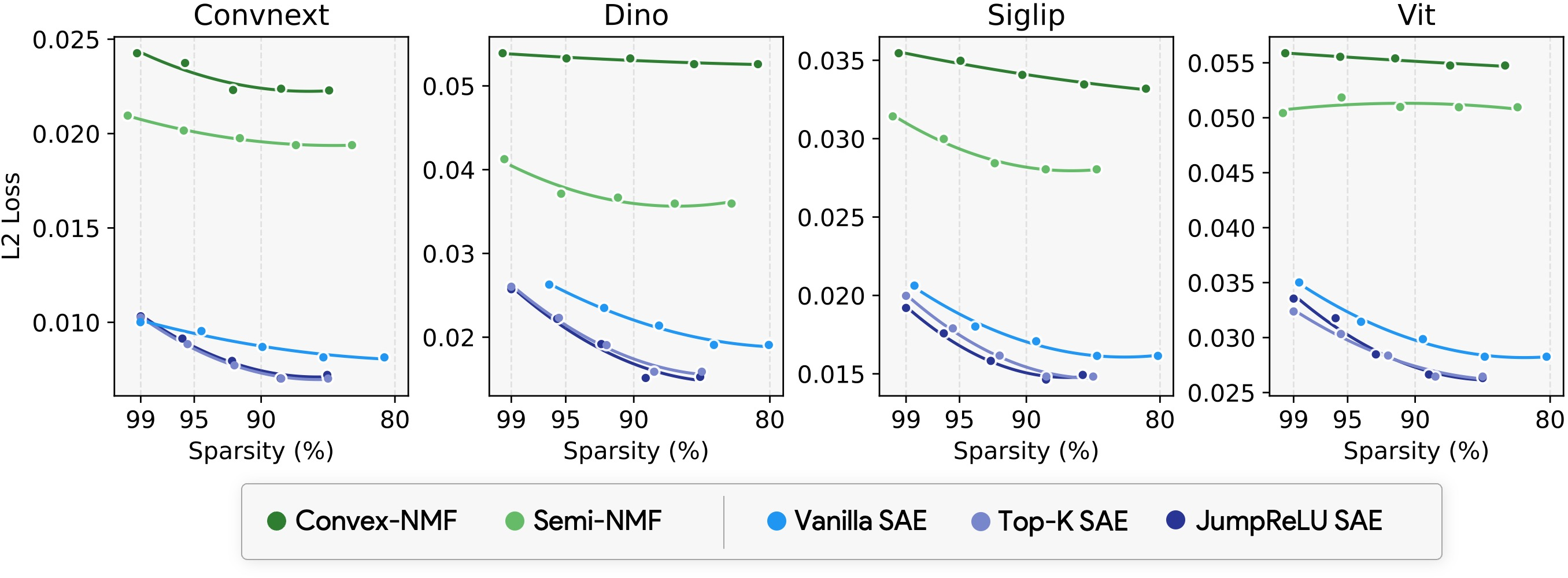
Extensive experimentation demonstrates the stability-reconstruction trade-off achieved by Archetypal SAEs compared to conventional SAE methods. By implementing dictionary learning techniques across a variety of vision models, the authors establish Archetypal SAEs offering better stability without compromising reconstruction fidelity. The newly introduced stability metric leverages optimal average cosine similarity between dictionaries across multiple training runs, a vital aspect highlighted by empirical findings.
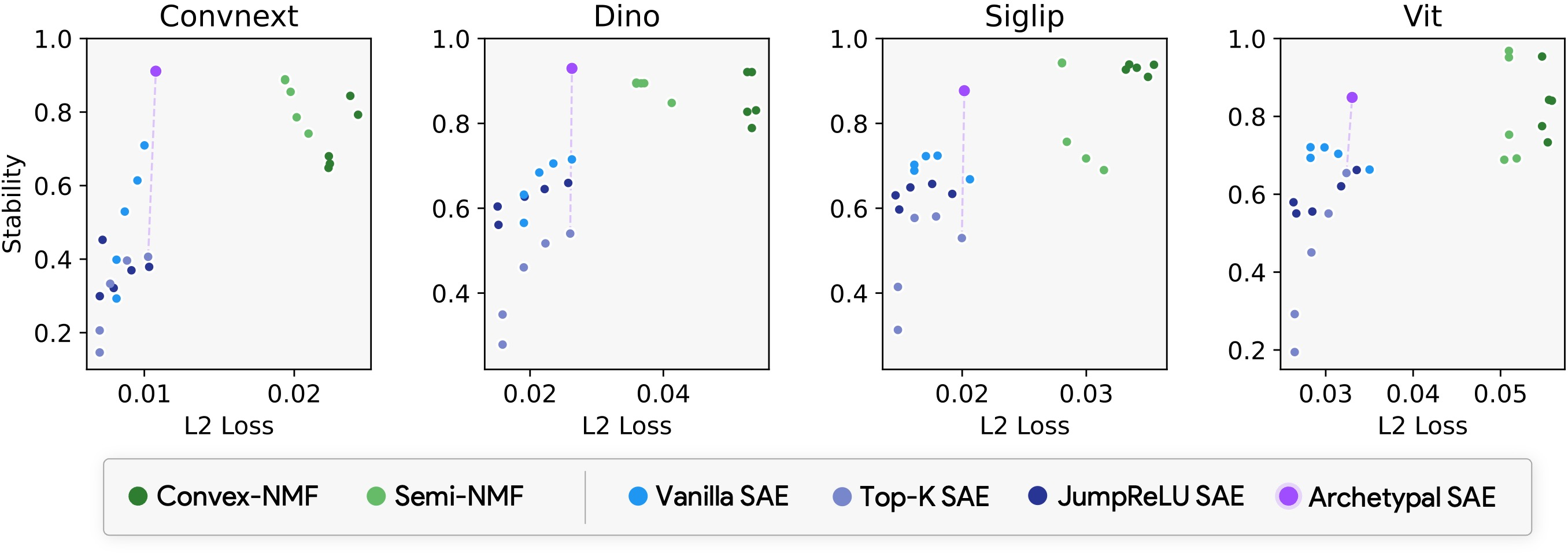
Figure 3: Stability-reconstruction tradeoff showcasing archetypal dictionaries reducing instability.
Impact of Relaxation Parameter
The work explores the impact of relaxation parameter adjustments, which allows exploration beyond the convex hull of data. This mechanism maintains a balance between standard SAE methods and the stringent constraints of archetypal analysis, proving effective in achieving comparable reconstruction performance alongside enhanced stability.
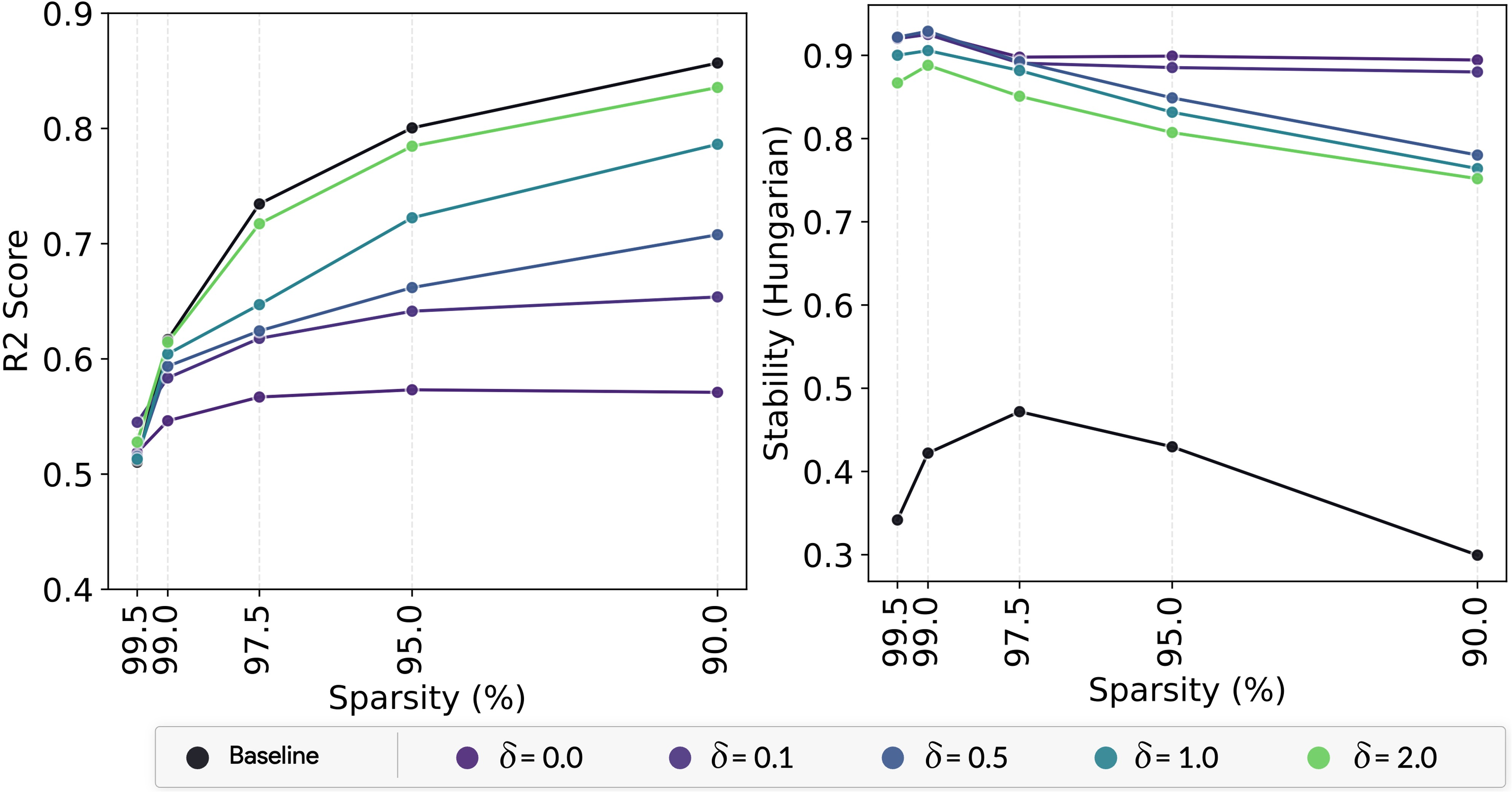
Figure 4: Impact of relaxation parameter on the performance of Archetypal SAE methods.
Implications and Future Work
The introduction of Archetypal SAEs posits significant implications for explainability in large vision models by enhancing stability and interpretability of learned representations. This approach paves the way for extending its application beyond vision, including LLMs and structured data domains. The balance between reconstruction fidelity and stability holds the potential for developing more reliable interpretability protocols, crucial for real-world applications requiring transparency, accountability, and ethical compliance.
Conclusion
In summary, the authors have presented an innovative solution to the instability problem in SAEs, leveraging archetypal anchoring to enhance dictionary learning stability. Experimental results cement the approach's validity, demonstrating marked improvements in structured concept extraction and interpretability. This work contributes meaningfully to the interpretability community, offering a robust method that addresses foundational reliability concerns in dictionary learning for AI models.
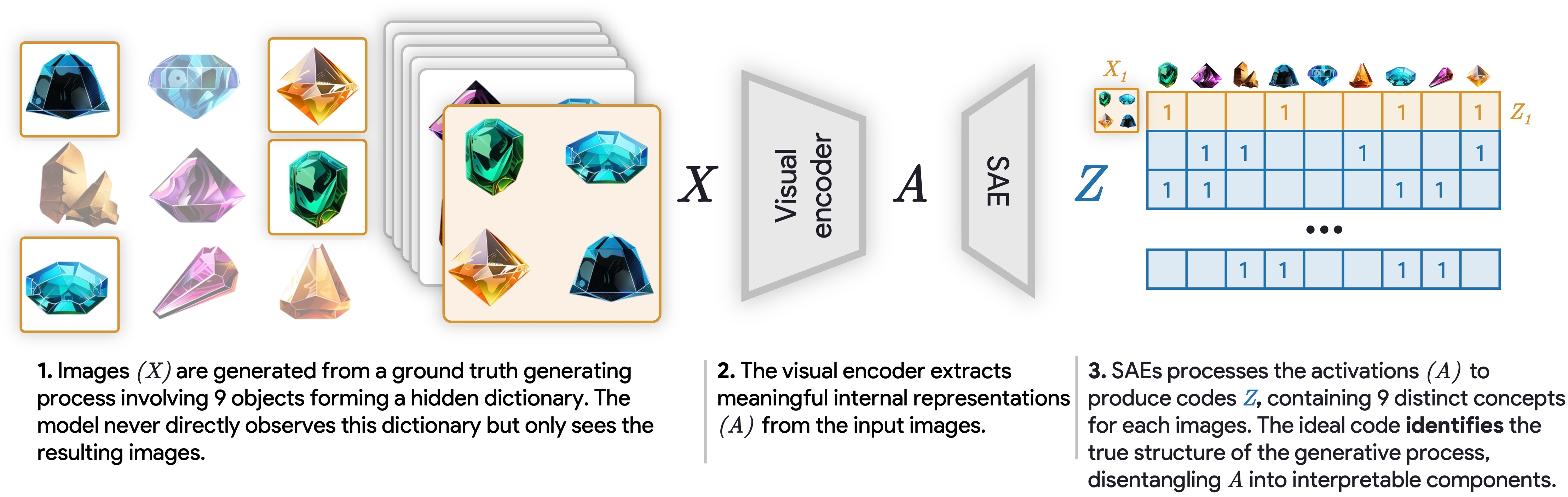
Figure 5: Benchmarks showing SAEs' ability to disentangle and recover hidden generative processes in datasets.